 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Deep Joint Source-Channel Coding for Wireless Image Transmission with Semantic Importance
Feb 05, 2023
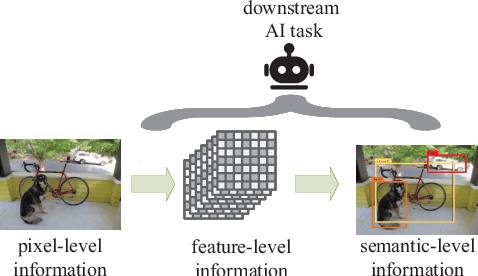
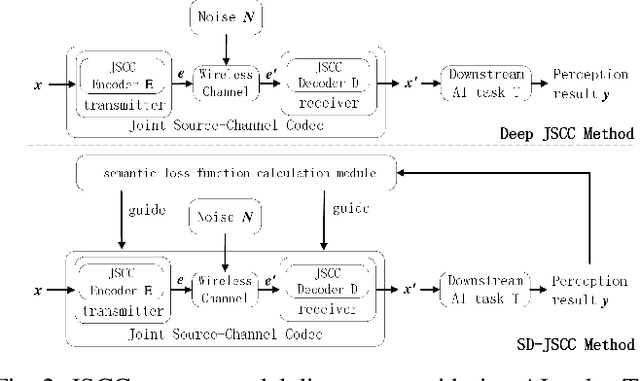
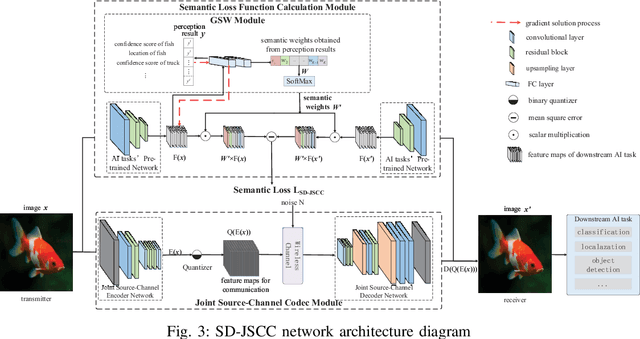
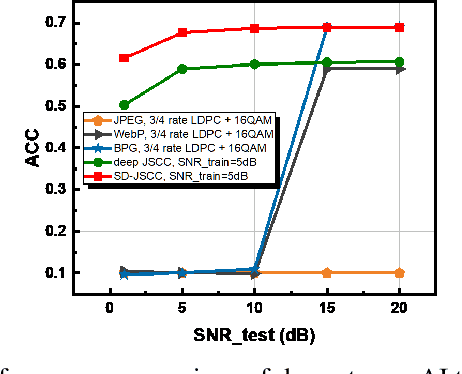
The sixth-generation mobile communication system proposes the vision of smart interconnection of everything, which requires accomplishing communication tasks while ensuring the performance of intelligent tasks. A joint source-channel coding method based on semantic importance is proposed, which aims at preserving semantic information during wireless image transmission and thereby boosting the performance of intelligent tasks for images at the receiver. Specifically, we first propose semantic importance weight calculation method, which is based on the gradient of intelligent task's perception results with respect to the features. Then, we design the semantic loss function in the way of using semantic weights to weight the features. Finally, we train the deep joint source-channel coding network using the semantic loss function. Experiment results demonstrate that the proposed method achieves up to 57.7% and 9.1% improvement in terms of intelligent task's performance compared with the source-channel separation coding method and the deep sourcechannel joint coding method without considering semantics at the same compression rate and signal-to-noise ratio, respectively.
Vision-Language Modelling For Radiological Imaging and Reports In The Low Data Regime
Mar 30, 2023

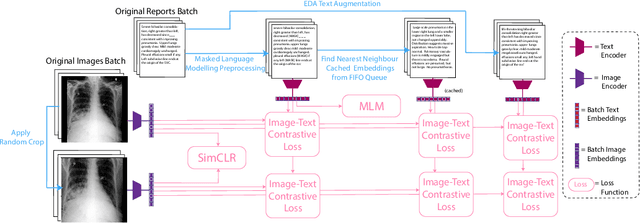
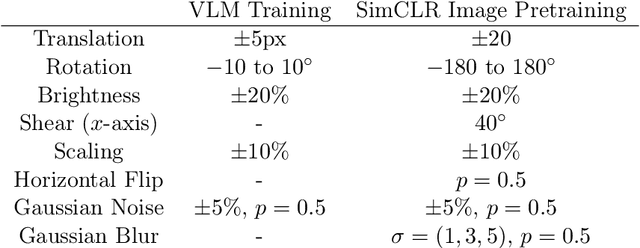
This paper explores training medical vision-language models (VLMs) -- where the visual and language inputs are embedded into a common space -- with a particular focus on scenarios where training data is limited, as is often the case in clinical datasets. We explore several candidate methods to improve low-data performance, including: (i) adapting generic pre-trained models to novel image and text domains (i.e. medical imaging and reports) via unimodal self-supervision; (ii) using local (e.g. GLoRIA) & global (e.g. InfoNCE) contrastive loss functions as well as a combination of the two; (iii) extra supervision during VLM training, via: (a) image- and text-only self-supervision, and (b) creating additional positive image-text pairs for training through augmentation and nearest-neighbour search. Using text-to-image retrieval as a benchmark, we evaluate the performance of these methods with variable sized training datasets of paired chest X-rays and radiological reports. Combined, they significantly improve retrieval compared to fine-tuning CLIP, roughly equivalent to training with the data. A similar pattern is found in the downstream task classification of CXR-related conditions with our method outperforming CLIP and also BioVIL, a strong CXR VLM benchmark, in the zero-shot and linear probing settings. We conclude with a set of recommendations for researchers aiming to train vision-language models on other medical imaging modalities when training data is scarce. To facilitate further research, we will make our code and models publicly available.
Multiscale Relevance of Natural Images
Mar 22, 2023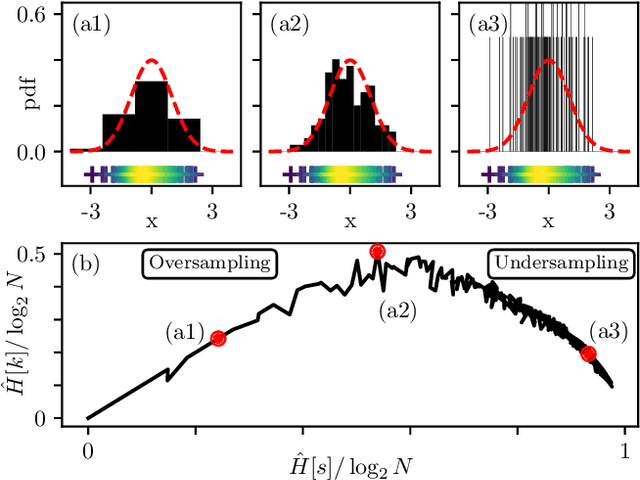

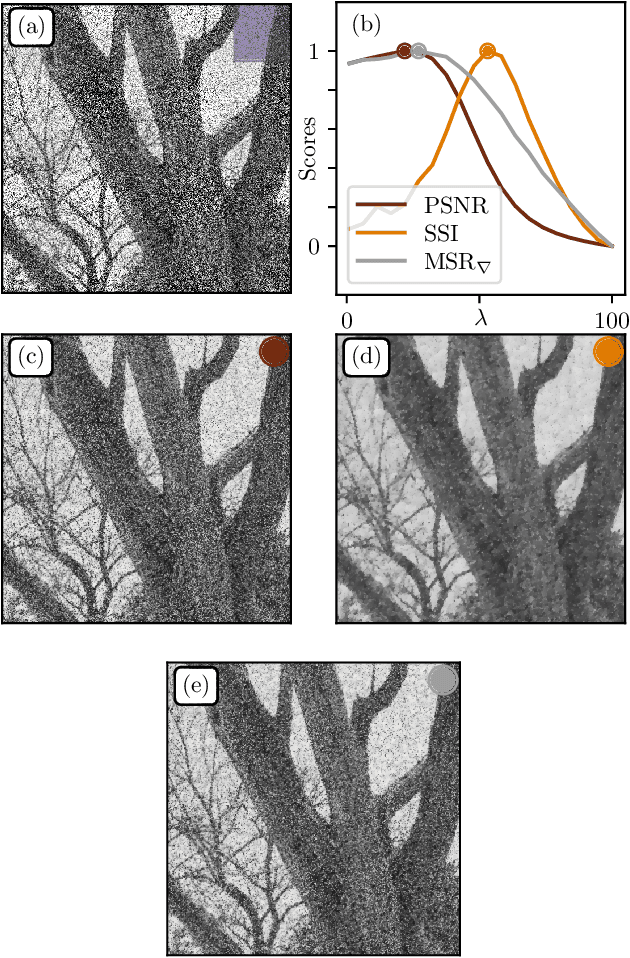

We use an agnostic information-theoretic approach to investigate the statistical properties of natural images. We introduce the Multiscale Relevance (MSR) measure to assess the robustness of images to compression at all scales. Starting in a controlled environment, we characterize the MSR of synthetic random textures as function of image roughness H and other relevant parameters. We then extend the analysis to natural images and find striking similarities with critical (H = 0) random textures. We show that the MSR is more robust and informative of image content than classical methods such as power spectrum analysis. Finally, we confront the MSR to classical measures for the calibration of common procedures such as color mapping and denoising. Overall, the MSR approach appears to be a good candidate for advanced image analysis and image processing, while providing a good level of physical interpretability.
Fine-grained Image Editing by Pixel-wise Guidance Using Diffusion Models
Dec 08, 2022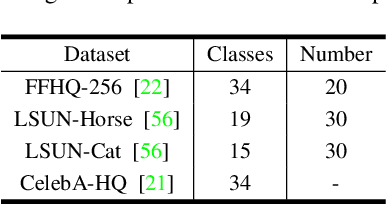
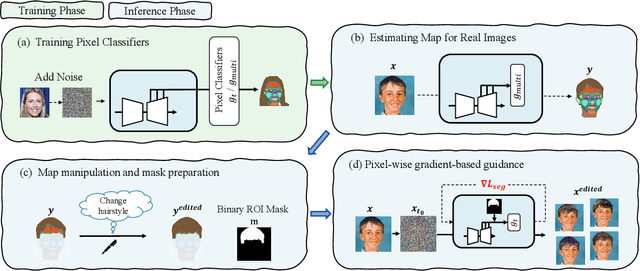
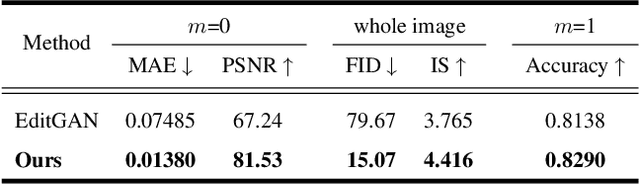
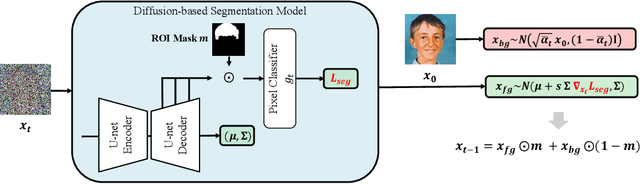
Generative models, particularly GANs, have been utilized for image editing. Although GAN-based methods perform well on generating reasonable contents aligned with the user's intentions, they struggle to strictly preserve the contents outside the editing region. To address this issue, we use diffusion models instead of GANs and propose a novel image-editing method, based on pixel-wise guidance. Specifically, we first train pixel-classifiers with few annotated data and then estimate the semantic segmentation map of a target image. Users then manipulate the map to instruct how the image is to be edited. The diffusion model generates an edited image via guidance by pixel-wise classifiers, such that the resultant image aligns with the manipulated map. As the guidance is conducted pixel-wise, the proposed method can create reasonable contents in the editing region while preserving the contents outside this region. The experimental results validate the advantages of the proposed method both quantitatively and qualitatively.
SMAE: Few-shot Learning for HDR Deghosting with Saturation-Aware Masked Autoencoders
Apr 14, 2023
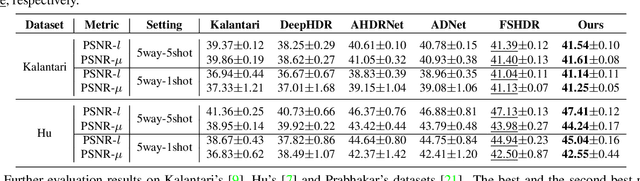
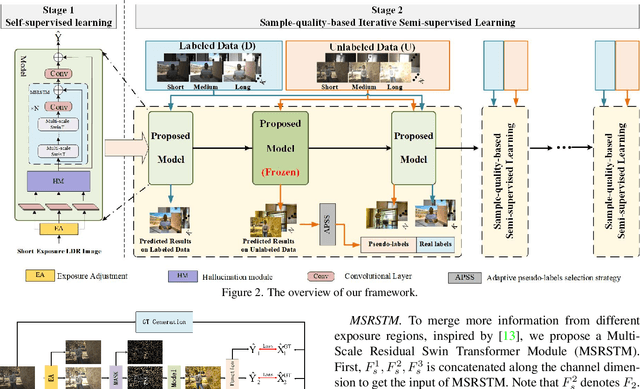
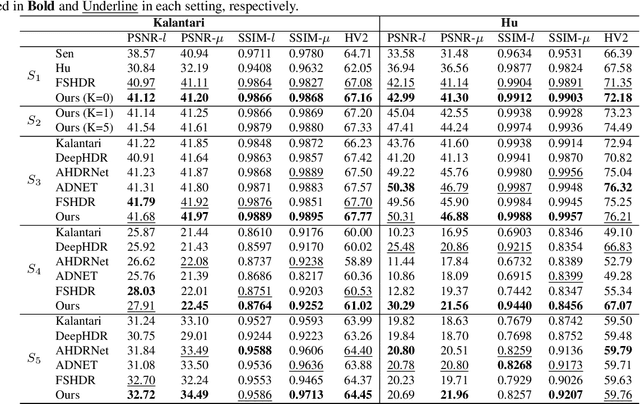
Generating a high-quality High Dynamic Range (HDR) image from dynamic scenes has recently been extensively studied by exploiting Deep Neural Networks (DNNs). Most DNNs-based methods require a large amount of training data with ground truth, requiring tedious and time-consuming work. Few-shot HDR imaging aims to generate satisfactory images with limited data. However, it is difficult for modern DNNs to avoid overfitting when trained on only a few images. In this work, we propose a novel semi-supervised approach to realize few-shot HDR imaging via two stages of training, called SSHDR. Unlikely previous methods, directly recovering content and removing ghosts simultaneously, which is hard to achieve optimum, we first generate content of saturated regions with a self-supervised mechanism and then address ghosts via an iterative semi-supervised learning framework. Concretely, considering that saturated regions can be regarded as masking Low Dynamic Range (LDR) input regions, we design a Saturated Mask AutoEncoder (SMAE) to learn a robust feature representation and reconstruct a non-saturated HDR image. We also propose an adaptive pseudo-label selection strategy to pick high-quality HDR pseudo-labels in the second stage to avoid the effect of mislabeled samples. Experiments demonstrate that SSHDR outperforms state-of-the-art methods quantitatively and qualitatively within and across different datasets, achieving appealing HDR visualization with few labeled samples.
Generative modeling of living cells with SO(3)-equivariant implicit neural representations
Apr 18, 2023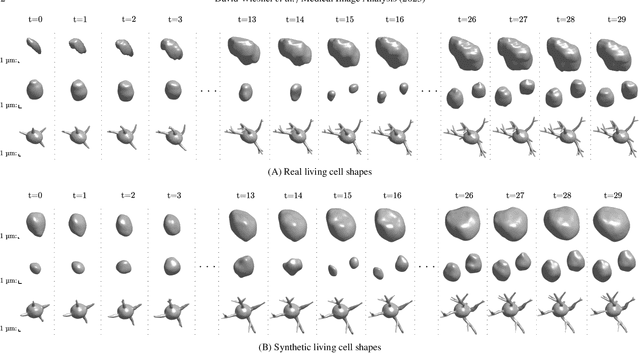
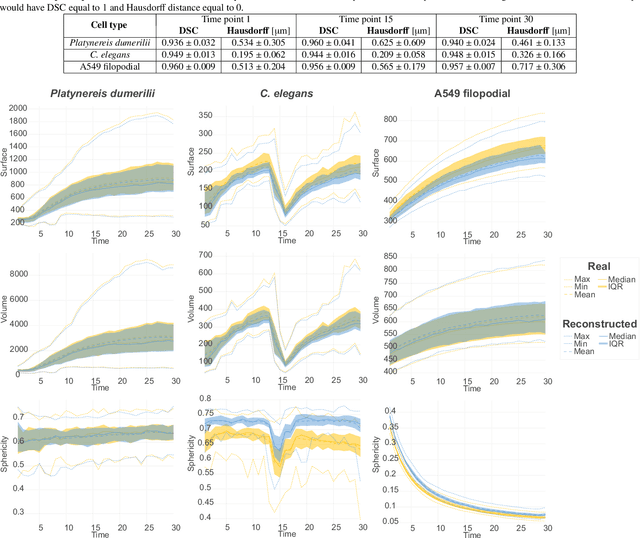
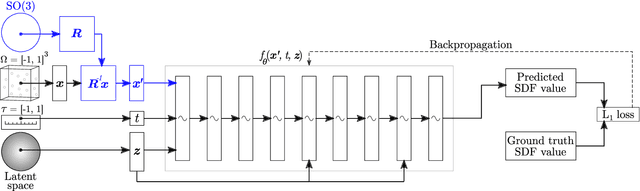
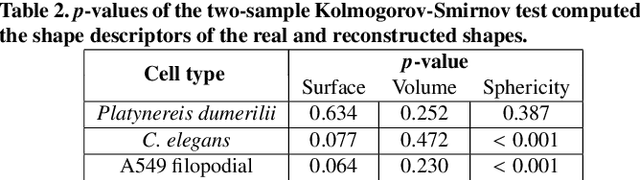
Data-driven cell tracking and segmentation methods in biomedical imaging require diverse and information-rich training data. In cases where the number of training samples is limited, synthetic computer-generated data sets can be used to improve these methods. This requires the synthesis of cell shapes as well as corresponding microscopy images using generative models. To synthesize realistic living cell shapes, the shape representation used by the generative model should be able to accurately represent fine details and changes in topology, which are common in cells. These requirements are not met by 3D voxel masks, which are restricted in resolution, and polygon meshes, which do not easily model processes like cell growth and mitosis. In this work, we propose to represent living cell shapes as level sets of signed distance functions (SDFs) which are estimated by neural networks. We optimize a fully-connected neural network to provide an implicit representation of the SDF value at any point in a 3D+time domain, conditioned on a learned latent code that is disentangled from the rotation of the cell shape. We demonstrate the effectiveness of this approach on cells that exhibit rapid deformations (Platynereis dumerilii), cells that grow and divide (C. elegans), and cells that have growing and branching filopodial protrusions (A549 human lung carcinoma cells). A quantitative evaluation using shape features, Hausdorff distance, and Dice similarity coefficients of real and synthetic cell shapes shows that our model can generate topologically plausible complex cell shapes in 3D+time with high similarity to real living cell shapes. Finally, we show how microscopy images of living cells that correspond to our generated cell shapes can be synthesized using an image-to-image model.
Black Box Few-Shot Adaptation for Vision-Language models
Apr 04, 2023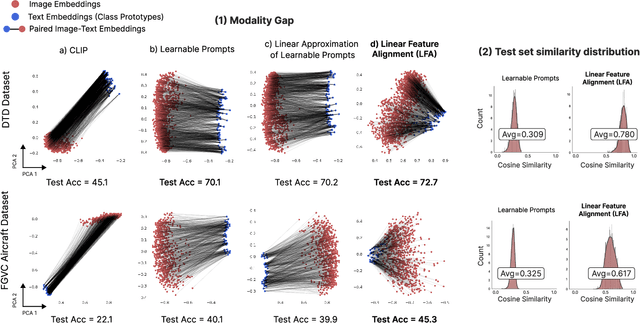
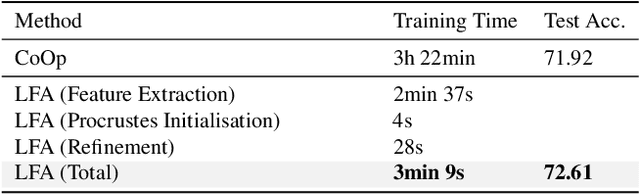
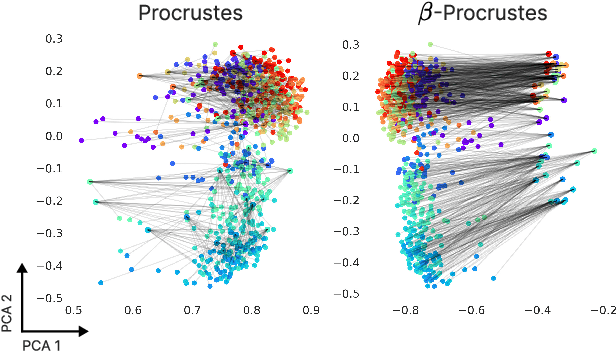
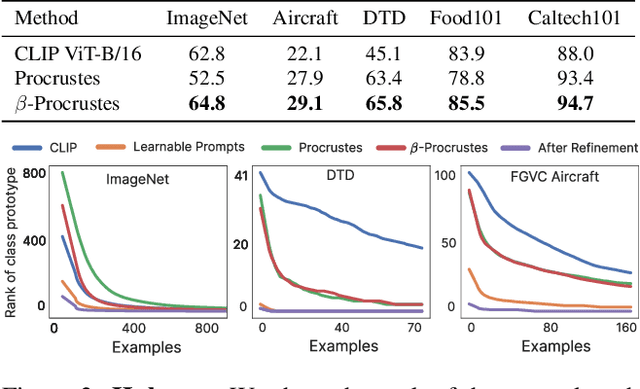
Vision-Language (V-L) models trained with contrastive learning to align the visual and language modalities have been shown to be strong few-shot learners. Soft prompt learning is the method of choice for few-shot downstream adaption aiming to bridge the modality gap caused by the distribution shift induced by the new domain. While parameter-efficient, prompt learning still requires access to the model weights and can be computationally infeasible for large models with billions of parameters. To address these shortcomings, in this work, we describe a black-box method for V-L few-shot adaptation that (a) operates on pre-computed image and text features and hence works without access to the model's weights, (b) it is orders of magnitude faster at training time, (c) it is amenable to both supervised and unsupervised training, and (d) it can be even used to align image and text features computed from uni-modal models. To achieve this, we propose Linear Feature Alignment (LFA), a simple linear approach for V-L re-alignment in the target domain. LFA is initialized from a closed-form solution to a least-squares problem and then it is iteratively updated by minimizing a re-ranking loss. Despite its simplicity, our approach can even surpass soft-prompt learning methods as shown by extensive experiments on 11 image and 2 video datasets.
Detecting Backdoors in Pre-trained Encoders
Mar 23, 2023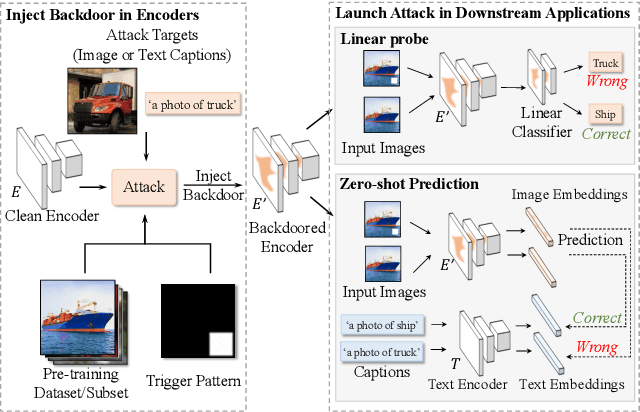

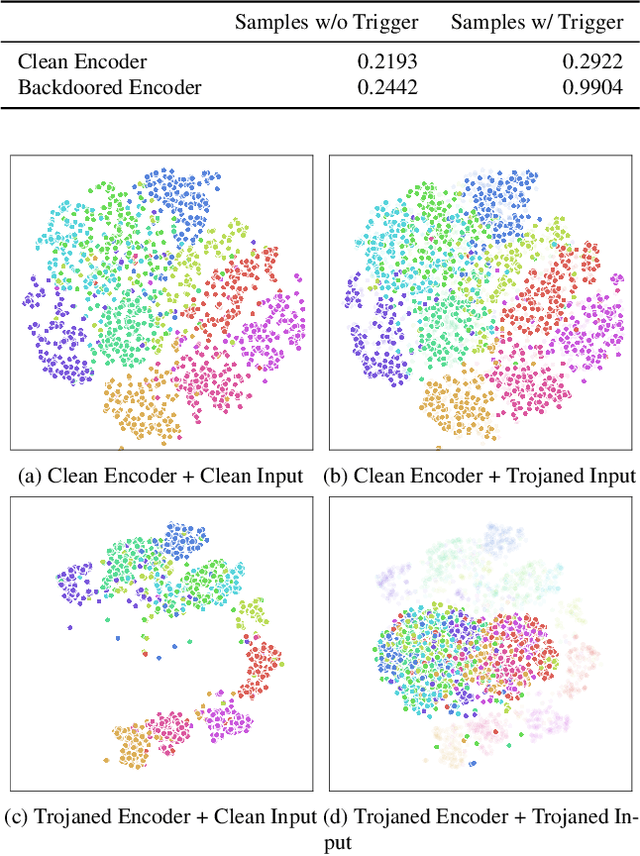
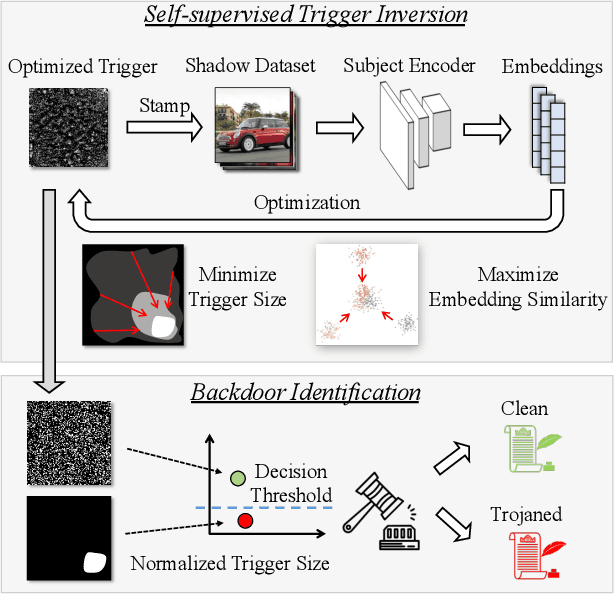
Self-supervised learning in computer vision trains on unlabeled data, such as images or (image, text) pairs, to obtain an image encoder that learns high-quality embeddings for input data. Emerging backdoor attacks towards encoders expose crucial vulnerabilities of self-supervised learning, since downstream classifiers (even further trained on clean data) may inherit backdoor behaviors from encoders. Existing backdoor detection methods mainly focus on supervised learning settings and cannot handle pre-trained encoders especially when input labels are not available. In this paper, we propose DECREE, the first backdoor detection approach for pre-trained encoders, requiring neither classifier headers nor input labels. We evaluate DECREE on over 400 encoders trojaned under 3 paradigms. We show the effectiveness of our method on image encoders pre-trained on ImageNet and OpenAI's CLIP 400 million image-text pairs. Our method consistently has a high detection accuracy even if we have only limited or no access to the pre-training dataset.
FSID: Fully Synthetic Image Denoising via Procedural Scene Generation
Dec 07, 2022

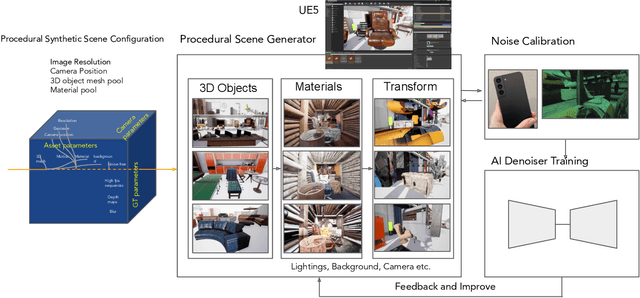

For low-level computer vision and image processing ML tasks, training on large datasets is critical for generalization. However, the standard practice of relying on real-world images primarily from the Internet comes with image quality, scalability, and privacy issues, especially in commercial contexts. To address this, we have developed a procedural synthetic data generation pipeline and dataset tailored to low-level vision tasks. Our Unreal engine-based synthetic data pipeline populates large scenes algorithmically with a combination of random 3D objects, materials, and geometric transformations. Then, we calibrate the camera noise profiles to synthesize the noisy images. From this pipeline, we generated a fully synthetic image denoising dataset (FSID) which consists of 175,000 noisy/clean image pairs. We then trained and validated a CNN-based denoising model, and demonstrated that the model trained on this synthetic data alone can achieve competitive denoising results when evaluated on real-world noisy images captured with smartphone cameras.
Learned Disentangled Latent Representations for Scalable Image Coding for Humans and Machines
Jan 10, 2023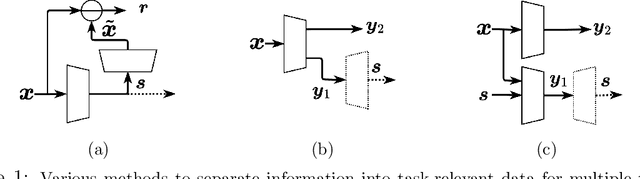

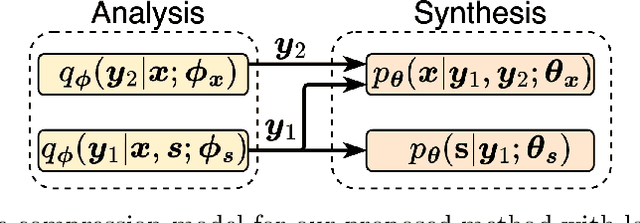
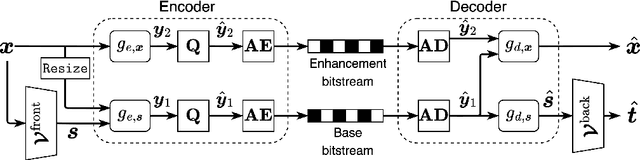
As an increasing amount of image and video content will be analyzed by machines, there is demand for a new codec paradigm that is capable of compressing visual input primarily for the purpose of computer vision inference, while secondarily supporting input reconstruction. In this work, we propose a learned compression architecture that can be used to build such a codec. We introduce a novel variational formulation that explicitly takes feature data relevant to the desired inference task as input at the encoder side. As such, our learned scalable image codec encodes and transmits two disentangled latent representations for object detection and input reconstruction. We note that compared to relevant benchmarks, our proposed scheme yields a more compact latent representation that is specialized for the inference task. Our experiments show that our proposed system achieves a bit rate savings of 40.6% on the primary object detection task compared to the current state-of-the-art, albeit with some degradation in performance for the secondary input reconstruction task.