 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVISion On Request: Enhanced VLLM efficiency with sparse, dynamically selected, vision-language interactions
Mar 24, 2026Existing approaches for improving the efficiency of Large Vision-Language Models (LVLMs) are largely based on the concept of visual token reduction. This approach, however, creates an information bottleneck that impairs performance, especially on challenging tasks that require fine-grained understanding and reasoning. In this work, we challenge this paradigm by introducing VISion On Request (VISOR), a method that reduces inference cost without discarding visual information. Instead of compressing the image, VISOR improves efficiency by sparsifying the interaction between image and text tokens. Specifically, the language model attends to the full set of high-resolution visual tokens through a small, strategically placed set of attention layers: general visual context is provided by efficient cross-attention between text-image, while a few well-placed and dynamically selected self-attention layers refine the visual representations themselves, enabling complex, high-resolution reasoning when needed. Based on this principle, we first train a single universal network on a range of computational budgets by varying the number of self-attention layers, and then introduce a lightweight policy mechanism that dynamically allocates visual computation based on per-sample complexity. Extensive experiments show that VISOR drastically reduces computational cost while matching or exceeding state-of-the-art results across a diverse suite of benchmarks, and excels in challenging tasks that require detailed visual understanding.
Fwd2Bot: LVLM Visual Token Compression with Double Forward Bottleneck
Mar 27, 2025



In this work, we aim to compress the vision tokens of a Large Vision Language Model (LVLM) into a representation that is simultaneously suitable for (a) generative and (b) discriminative tasks, (c) is nearly lossless, and (d) is storage-efficient. We propose a novel compression approach, called Fwd2Bot, that uses the LVLM itself to compress the visual information in a task-agnostic manner. At the core of Fwd2bot there exists a "double-forward pass" training strategy, whereby, during the first forward pass, the LLM (of the LVLM) creates a bottleneck by condensing the visual information into a small number of summary tokens. Then, using the same LLM, the second forward pass processes the language instruction(s) alongside the summary tokens, used as a direct replacement for the image ones. The training signal is provided by two losses: an autoregressive one applied after the second pass that provides a direct optimization objective for compression, and a contrastive loss, applied after the first pass, that further boosts the representation strength, especially for discriminative tasks. The training is further enhanced by stage-specific adapters. We accompany the proposed method by an in-depth ablation study. Overall, Fwd2Bot results in highly-informative compressed representations suitable for both generative and discriminative tasks. For generative tasks, we offer a 2x higher compression rate without compromising the generative capabilities, setting a new state-of-the-art result. For discriminative tasks, we set a new state-of-the-art on image retrieval and compositionality.
Discriminative Fine-tuning of LVLMs
Dec 05, 2024



Contrastively-trained Vision-Language Models (VLMs) like CLIP have become the de facto approach for discriminative vision-language representation learning. However, these models have limited language understanding, often exhibiting a "bag of words" behavior. At the same time, Large Vision-Language Models (LVLMs), which combine vision encoders with LLMs, have been shown capable of detailed vision-language reasoning, yet their autoregressive nature renders them less suitable for discriminative tasks. In this work, we propose to combine "the best of both worlds": a new training approach for discriminative fine-tuning of LVLMs that results in strong discriminative and compositional capabilities. Essentially, our approach converts a generative LVLM into a discriminative one, unlocking its capability for powerful image-text discrimination combined with enhanced language understanding. Our contributions include: (1) A carefully designed training/optimization framework that utilizes image-text pairs of variable length and granularity for training the model with both contrastive and next-token prediction losses. This is accompanied by ablation studies that justify the necessity of our framework's components. (2) A parameter-efficient adaptation method using a combination of soft prompting and LoRA adapters. (3) Significant improvements over state-of-the-art CLIP-like models of similar size, including standard image-text retrieval benchmarks and notable gains in compositionality.
CLIP-DPO: Vision-Language Models as a Source of Preference for Fixing Hallucinations in LVLMs
Aug 19, 2024



Despite recent successes, LVLMs or Large Vision Language Models are prone to hallucinating details like objects and their properties or relations, limiting their real-world deployment. To address this and improve their robustness, we present CLIP-DPO, a preference optimization method that leverages contrastively pre-trained Vision-Language (VL) embedding models, such as CLIP, for DPO-based optimization of LVLMs. Unlike prior works tackling LVLM hallucinations, our method does not rely on paid-for APIs, and does not require additional training data or the deployment of other external LVLMs. Instead, starting from the initial pool of supervised fine-tuning data, we generate a diverse set of predictions, which are ranked based on their CLIP image-text similarities, and then filtered using a robust rule-based approach to obtain a set of positive and negative pairs for DPO-based training. We applied CLIP-DPO fine-tuning to the MobileVLM-v2 family of models and to LlaVA-1.5, in all cases observing significant improvements in terms of hallucination reduction over baseline models. We also observe better performance for zero-shot classification, suggesting improved grounding capabilities, and verify that the original performance on standard LVLM benchmarks is overall preserved.
FFF: Fixing Flawed Foundations in contrastive pre-training results in very strong Vision-Language models
May 16, 2024



Despite noise and caption quality having been acknowledged as important factors impacting vision-language contrastive pre-training, in this paper, we show that the full potential of improving the training process by addressing such issues is yet to be realized. Specifically, we firstly study and analyze two issues affecting training: incorrect assignment of negative pairs, and low caption quality and diversity. Then, we devise effective solutions for addressing both problems, which essentially require training with multiple true positive pairs. Finally, we propose training with sigmoid loss to address such a requirement. We show very large gains over the current state-of-the-art for both image recognition ($\sim +6\%$ on average over 11 datasets) and image retrieval ($\sim +19\%$ on Flickr30k and $\sim +15\%$ on MSCOCO).
Black Box Few-Shot Adaptation for Vision-Language models
Apr 04, 2023



Vision-Language (V-L) models trained with contrastive learning to align the visual and language modalities have been shown to be strong few-shot learners. Soft prompt learning is the method of choice for few-shot downstream adaption aiming to bridge the modality gap caused by the distribution shift induced by the new domain. While parameter-efficient, prompt learning still requires access to the model weights and can be computationally infeasible for large models with billions of parameters. To address these shortcomings, in this work, we describe a black-box method for V-L few-shot adaptation that (a) operates on pre-computed image and text features and hence works without access to the model's weights, (b) it is orders of magnitude faster at training time, (c) it is amenable to both supervised and unsupervised training, and (d) it can be even used to align image and text features computed from uni-modal models. To achieve this, we propose Linear Feature Alignment (LFA), a simple linear approach for V-L re-alignment in the target domain. LFA is initialized from a closed-form solution to a least-squares problem and then it is iteratively updated by minimizing a re-ranking loss. Despite its simplicity, our approach can even surpass soft-prompt learning methods as shown by extensive experiments on 11 image and 2 video datasets.
Spatial Contrastive Learning for Few-Shot Classification
Dec 26, 2020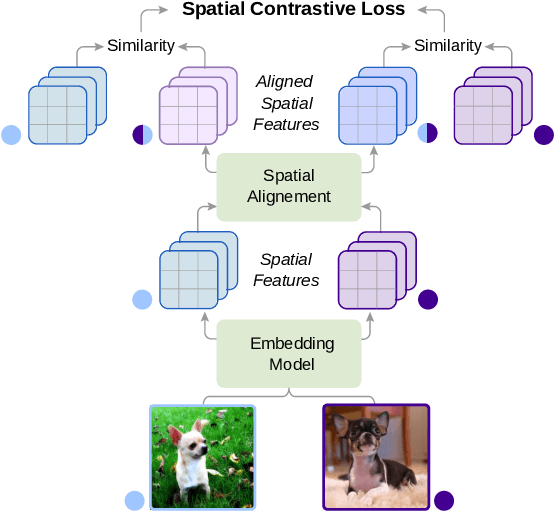
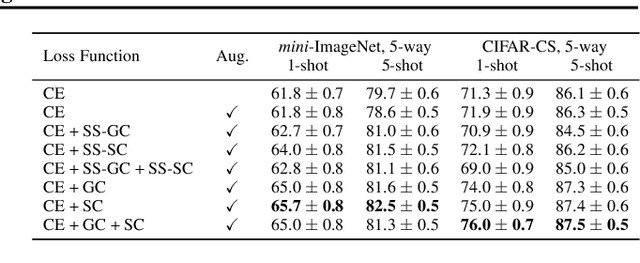
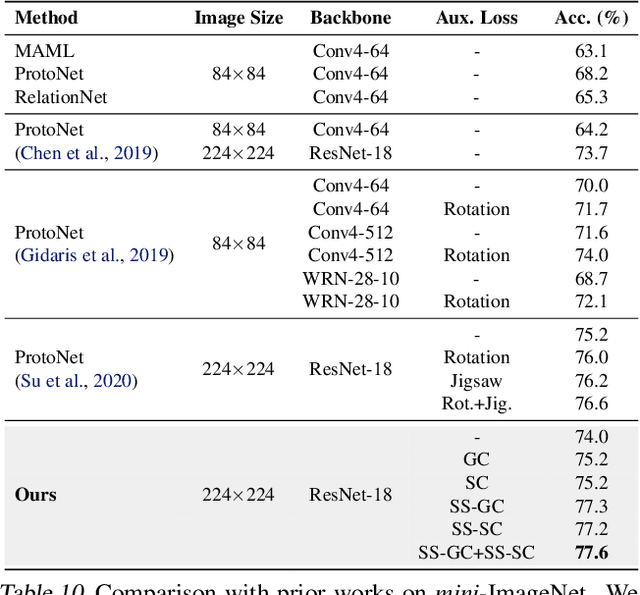

Existing few-shot classification methods rely to some degree on the cross-entropy (CE) loss to learn transferable representations that facilitate the test time adaptation to unseen classes with limited data. However, the CE loss has several shortcomings, e.g., inducing representations with excessive discrimination towards seen classes, which reduces their transferability to unseen classes and results in sub-optimal generalization. In this work, we explore contrastive learning as an additional auxiliary training objective, acting as a data-dependent regularizer to promote more general and transferable features. Instead of using the standard contrastive objective, which suppresses local discriminative features, we propose a novel attention-based spatial contrastive objective to learn locally discriminative and class-agnostic features. With extensive experiments, we show that the proposed method outperforms state-of-the-art approaches, confirming the importance of learning good and transferable embeddings for few-shot learning.
Autoregressive Unsupervised Image Segmentation
Jul 16, 2020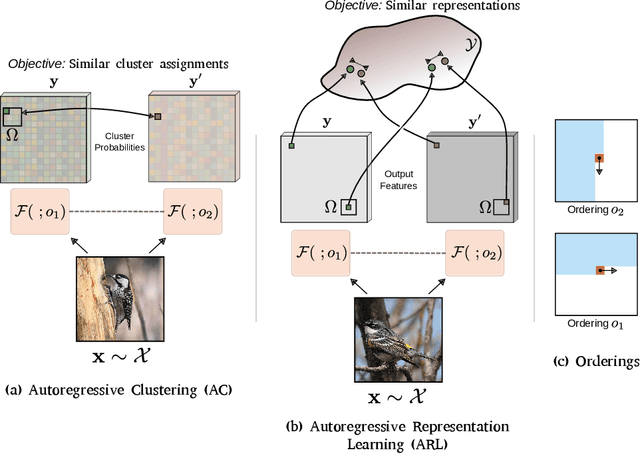
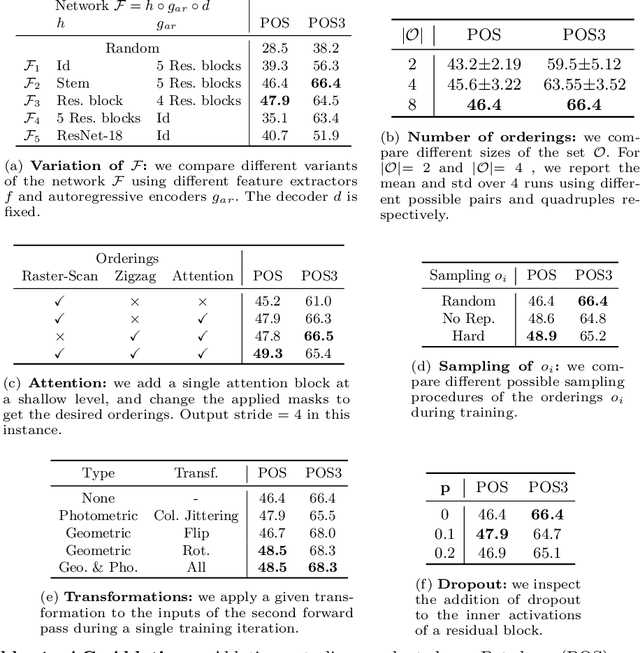

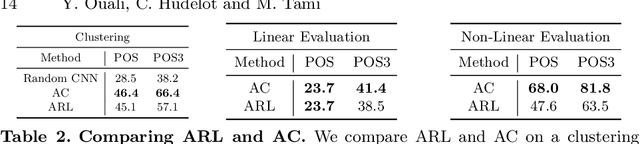
In this work, we propose a new unsupervised image segmentation approach based on mutual information maximization between different constructed views of the inputs. Taking inspiration from autoregressive generative models that predict the current pixel from past pixels in a raster-scan ordering created with masked convolutions, we propose to use different orderings over the inputs using various forms of masked convolutions to construct different views of the data. For a given input, the model produces a pair of predictions with two valid orderings, and is then trained to maximize the mutual information between the two outputs. These outputs can either be low-dimensional features for representation learning or output clusters corresponding to semantic labels for clustering. While masked convolutions are used during training, in inference, no masking is applied and we fall back to the standard convolution where the model has access to the full input. The proposed method outperforms current state-of-the-art on unsupervised image segmentation. It is simple and easy to implement, and can be extended to other visual tasks and integrated seamlessly into existing unsupervised learning methods requiring different views of the data.
An Overview of Deep Semi-Supervised Learning
Jul 06, 2020
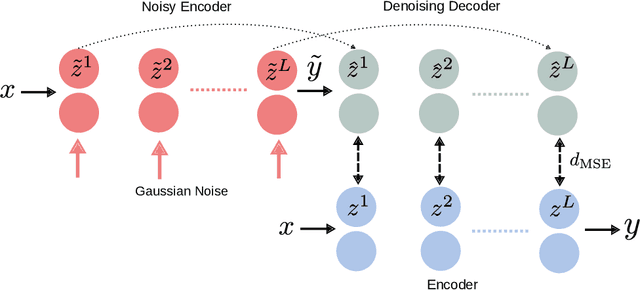

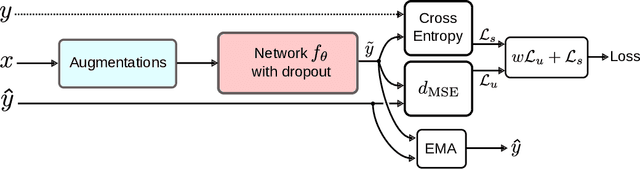
Deep neural networks demonstrated their ability to provide remarkable performances on a wide range of supervised learning tasks (e.g., image classification) when trained on extensive collections of labeled data (e.g., ImageNet). However, creating such large datasets requires a considerable amount of resources, time, and effort. Such resources may not be available in many practical cases, limiting the adoption and the application of many deep learning methods. In a search for more data-efficient deep learning methods to overcome the need for large annotated datasets, there is a rising research interest in semi-supervised learning and its applications to deep neural networks to reduce the amount of labeled data required, by either developing novel methods or adopting existing semi-supervised learning frameworks for a deep learning setting. In this paper, we provide a comprehensive overview of deep semi-supervised learning, starting with an introduction to the field, followed by a summarization of the dominant semi-supervised approaches in deep learning.
Target Consistency for Domain Adaptation: when Robustness meets Transferability
Jun 30, 2020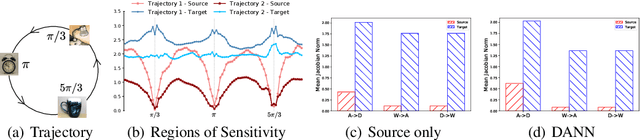
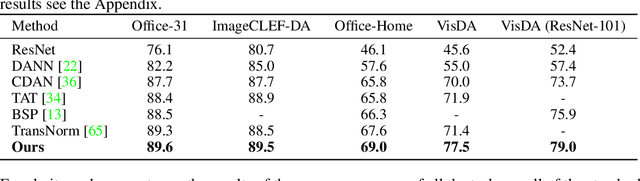

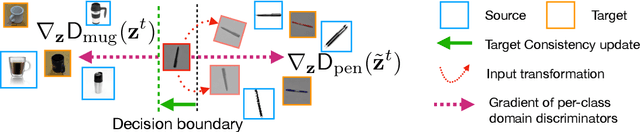
Learning Invariant Representations has been successfully applied for reconciling a source and a target domain for Unsupervised Domain Adaptation. By investigating the robustness of such methods under the prism of the cluster assumption, we bring new evidence that invariance with a low source risk does not guarantee a well-performing target classifier. More precisely, we show that the cluster assumption is violated in the target domain despite being maintained in the source domain, indicating a lack of robustness of the target classifier. To address this problem, we demonstrate the importance of enforcing the cluster assumption in the target domain, named Target Consistency (TC), especially when paired with Class-Level InVariance (CLIV). Our new approach results in a significant improvement, on both image classification and segmentation benchmarks, over state-of-the-art methods based on invariant representations. Importantly, our method is flexible and easy to implement, making it a complementary technique to existing approaches for improving transferability of representations.