 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Spatial and Modal Optimal Transport for Fast Cross-Modal MRI Reconstruction
May 04, 2023
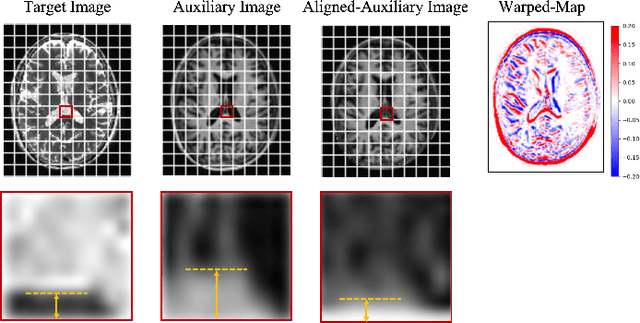
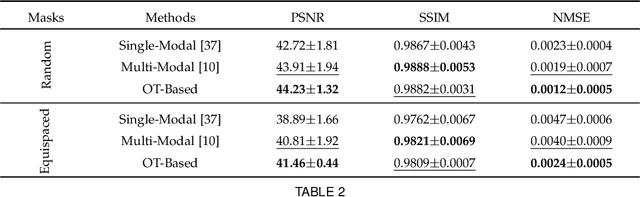
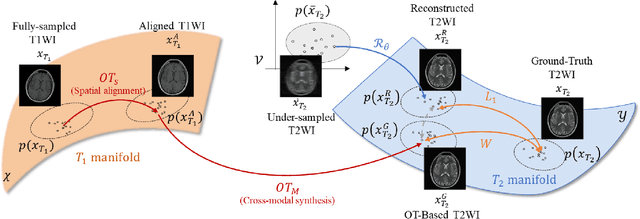
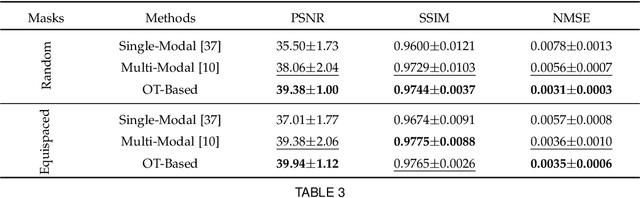
Multi-modal Magnetic Resonance Imaging (MRI) plays an important role in clinical medicine. However, the acquisitions of some modalities, such as the T2-weighted modality, need a long time and they are always accompanied by motion artifacts. On the other hand, the T1-weighted image (T1WI) shares the same underlying information with T2-weighted image (T2WI), which needs a shorter scanning time. Therefore, in this paper we accelerate the acquisition of the T2WI by introducing the auxiliary modality (T1WI). Concretely, we first reconstruct high-quality T2WIs with under-sampled T2WIs. Here, we realize fast T2WI reconstruction by reducing the sampling rate in the k-space. Second, we establish a cross-modal synthesis task to generate the synthetic T2WIs for guiding better T2WI reconstruction. Here, we obtain the synthetic T2WIs by decomposing the whole cross-modal generation mapping into two OT processes, the spatial alignment mapping on the T1 image manifold and the cross-modal synthesis mapping from aligned T1WIs to T2WIs. It overcomes the negative transfer caused by the spatial misalignment. Then, we prove the reconstruction and the synthesis tasks are well complementary. Finally, we compare it with state-of-the-art approaches on an open dataset FastMRI and an in-house dataset to testify the validity of the proposed method.
Robust Cross-domain CT Image Reconstruction via Bayesian Noise Uncertainty Alignment
Feb 26, 2023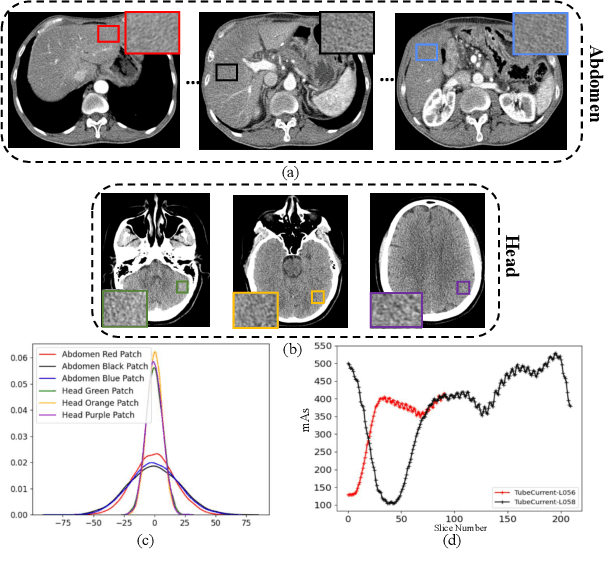
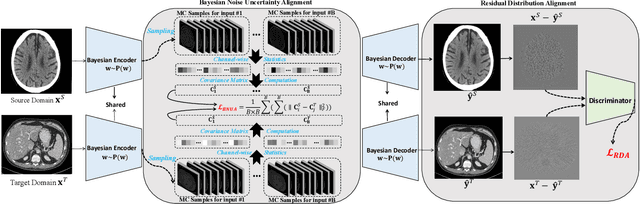
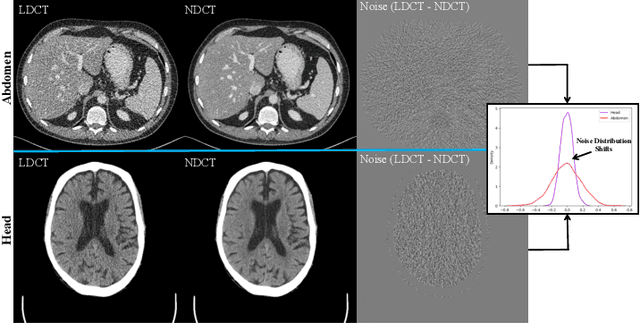
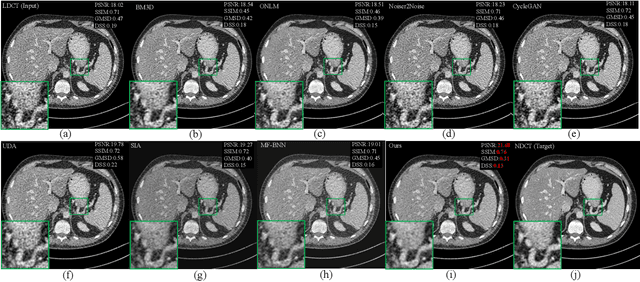
In this work, we tackle the problem of robust computed tomography (CT) reconstruction issue under a cross-domain scenario, i.e., the training CT data as the source domain and the testing CT data as the target domain are collected from different anatomical regions. Due to the mismatches of the scan region and corresponding scan protocols, there is usually a difference of noise distributions between source and target domains (a.k.a. noise distribution shifts), resulting in a catastrophic deterioration of the reconstruction performance on target domain. To render a robust cross-domain CT reconstruction performance, instead of using deterministic models (e.g., convolutional neural network), a Bayesian-endowed probabilistic framework is introduced into robust cross-domain CT reconstruction task due to its impressive robustness. Under this probabilistic framework, we propose to alleviate the noise distribution shifts between source and target domains via implicit noise modeling schemes in the latent space and image space, respectively. Specifically, a novel Bayesian noise uncertainty alignment (BNUA) method is proposed to conduct implicit noise distribution modeling and alignment in the latent space. Moreover, an adversarial learning manner is imposed to reduce the discrepancy of noise distribution between two domains in the image space via a novel residual distribution alignment (RDA). Extensive experiments on the head and abdomen scans show that our proposed method can achieve a better performance of robust cross-domain CT reconstruction than existing approaches in terms of both quantitative and qualitative results.
Multi-Task Self-Supervised Learning for Image Segmentation Task
Feb 05, 2023

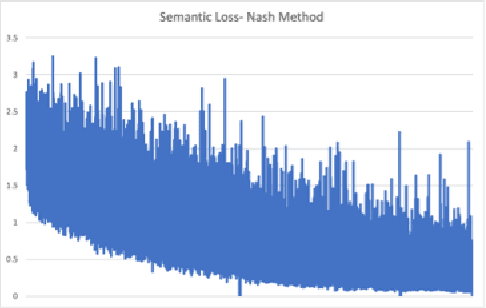

Thanks to breakthroughs in AI and Deep learning methodology, Computer vision techniques are rapidly improving. Most computer vision applications require sophisticated image segmentation to comprehend what is image and to make an analysis of each section easier. Training deep learning networks for semantic segmentation required a large amount of annotated data, which presents a major challenge in practice as it is expensive and labor-intensive to produce such data. The paper presents 1. Self-supervised techniques to boost semantic segmentation performance using multi-task learning with Depth prediction and Surface Normalization . 2. Performance evaluation of the different types of weighing techniques (UW, Nash-MTL) used for Multi-task learning. NY2D dataset was used for performance evaluation. According to our evaluation, the Nash-MTL method outperforms single task learning(Semantic Segmentation).
On enhancing the robustness of Vision Transformers: Defensive Diffusion
May 14, 2023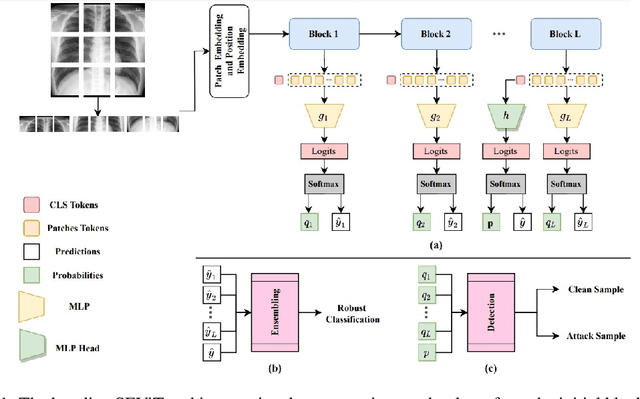
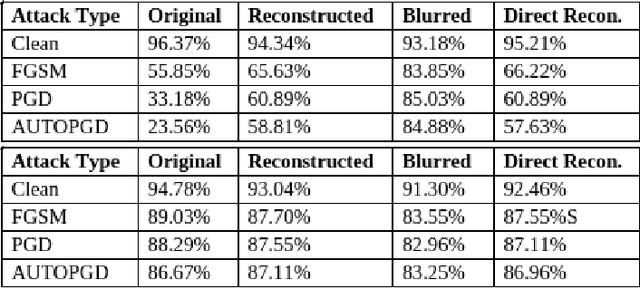
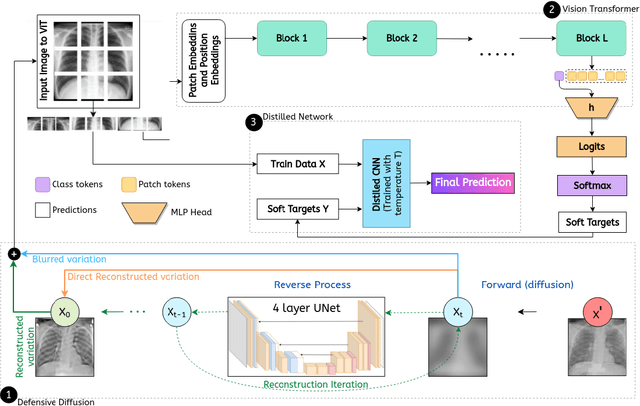
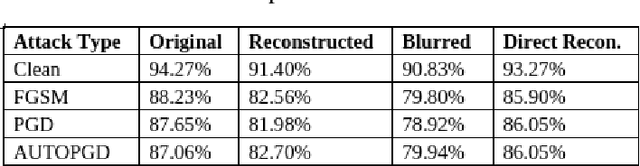
Privacy and confidentiality of medical data are of utmost importance in healthcare settings. ViTs, the SOTA vision model, rely on large amounts of patient data for training, which raises concerns about data security and the potential for unauthorized access. Adversaries may exploit vulnerabilities in ViTs to extract sensitive patient information and compromising patient privacy. This work address these vulnerabilities to ensure the trustworthiness and reliability of ViTs in medical applications. In this work, we introduced a defensive diffusion technique as an adversarial purifier to eliminate adversarial noise introduced by attackers in the original image. By utilizing the denoising capabilities of the diffusion model, we employ a reverse diffusion process to effectively eliminate the adversarial noise from the attack sample, resulting in a cleaner image that is then fed into the ViT blocks. Our findings demonstrate the effectiveness of the diffusion model in eliminating attack-agnostic adversarial noise from images. Additionally, we propose combining knowledge distillation with our framework to obtain a lightweight student model that is both computationally efficient and robust against gray box attacks. Comparison of our method with a SOTA baseline method, SEViT, shows that our work is able to outperform the baseline. Extensive experiments conducted on a publicly available Tuberculosis X-ray dataset validate the computational efficiency and improved robustness achieved by our proposed architecture.
Internal Diverse Image Completion
Dec 18, 2022
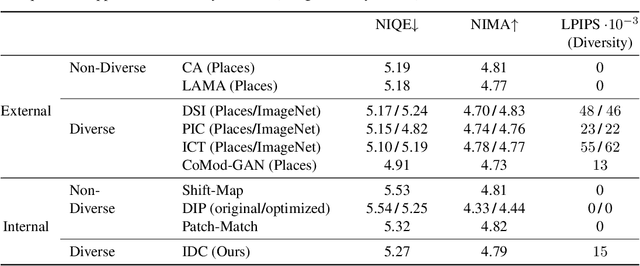
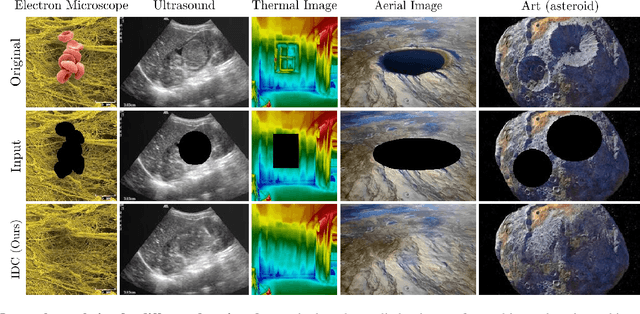
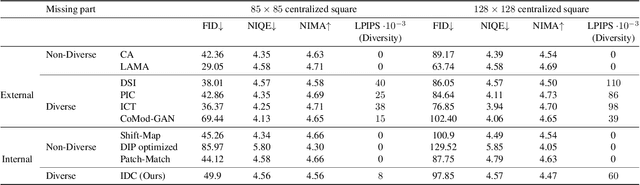
Image completion is widely used in photo restoration and editing applications, e.g. for object removal. Recently, there has been a surge of research on generating diverse completions for missing regions. However, existing methods require large training sets from a specific domain of interest, and often fail on general-content images. In this paper, we propose a diverse completion method that does not require a training set and can thus treat arbitrary images from any domain. Our internal diverse completion (IDC) approach draws inspiration from recent single-image generative models that are trained on multiple scales of a single image, adapting them to the extreme setting in which only a small portion of the image is available for training. We illustrate the strength of IDC on several datasets, using both user studies and quantitative comparisons.
Learning Self-Supervised Representations for Label Efficient Cross-Domain Knowledge Transfer on Diabetic Retinopathy Fundus Images
Apr 20, 2023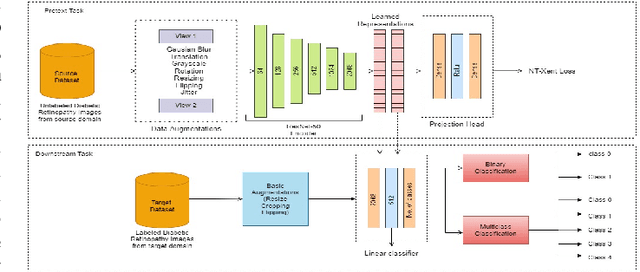
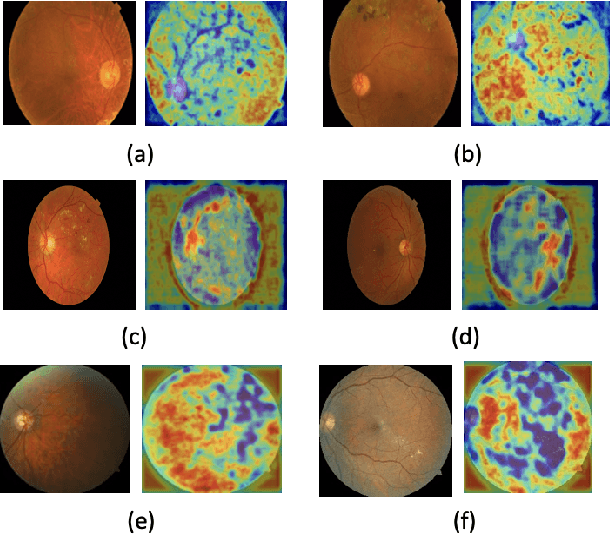
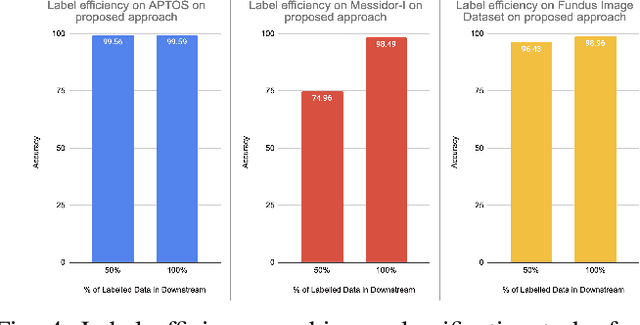
This work presents a novel label-efficient selfsupervised representation learning-based approach for classifying diabetic retinopathy (DR) images in cross-domain settings. Most of the existing DR image classification methods are based on supervised learning which requires a lot of time-consuming and expensive medical domain experts-annotated data for training. The proposed approach uses the prior learning from the source DR image dataset to classify images drawn from the target datasets. The image representations learned from the unlabeled source domain dataset through contrastive learning are used to classify DR images from the target domain dataset. Moreover, the proposed approach requires a few labeled images to perform successfully on DR image classification tasks in cross-domain settings. The proposed work experiments with four publicly available datasets: EyePACS, APTOS 2019, MESSIDOR-I, and Fundus Images for self-supervised representation learning-based DR image classification in cross-domain settings. The proposed method achieves state-of-the-art results on binary and multiclassification of DR images, even in cross-domain settings. The proposed method outperforms the existing DR image binary and multi-class classification methods proposed in the literature. The proposed method is also validated qualitatively using class activation maps, revealing that the method can learn explainable image representations. The source code and trained models are published on GitHub.
RSIR Transformer: Hierarchical Vision Transformer using Random Sampling Windows and Important Region Windows
Apr 27, 2023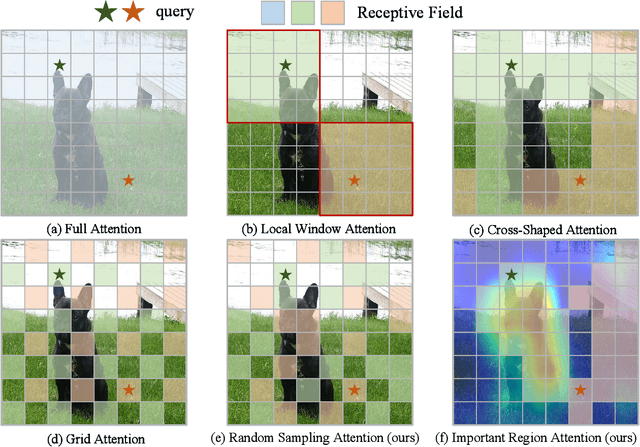
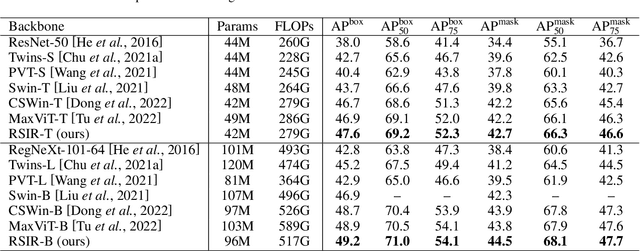
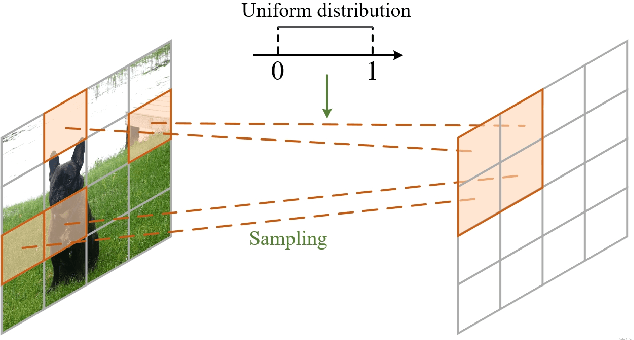
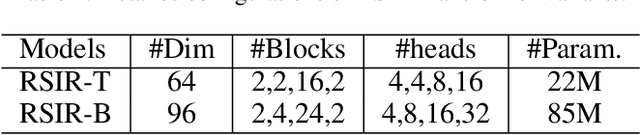
Recently, Transformers have shown promising performance in various vision tasks. However, the high costs of global self-attention remain challenging for Transformers, especially for high-resolution vision tasks. Local self-attention runs attention computation within a limited region for the sake of efficiency, resulting in insufficient context modeling as their receptive fields are small. In this work, we introduce two new attention modules to enhance the global modeling capability of the hierarchical vision transformer, namely, random sampling windows (RS-Win) and important region windows (IR-Win). Specifically, RS-Win sample random image patches to compose the window, following a uniform distribution, i.e., the patches in RS-Win can come from any position in the image. IR-Win composes the window according to the weights of the image patches in the attention map. Notably, RS-Win is able to capture global information throughout the entire model, even in earlier, high-resolution stages. IR-Win enables the self-attention module to focus on important regions of the image and capture more informative features. Incorporated with these designs, RSIR-Win Transformer demonstrates competitive performance on common vision tasks.
BiRT: Bio-inspired Replay in Vision Transformers for Continual Learning
May 08, 2023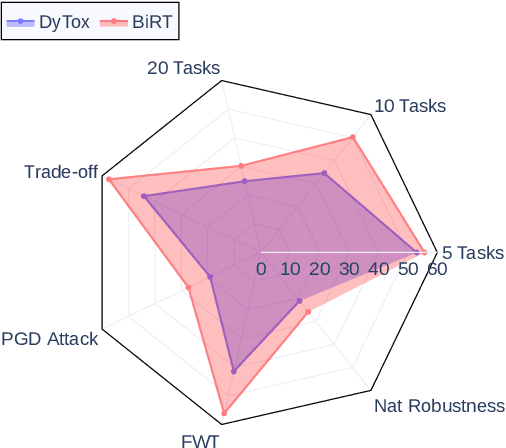
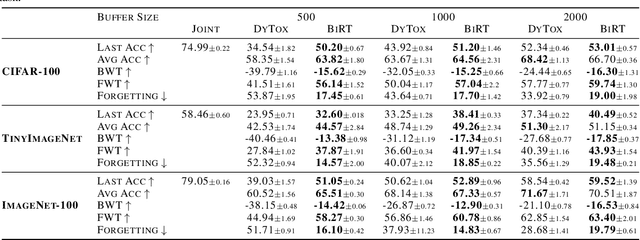
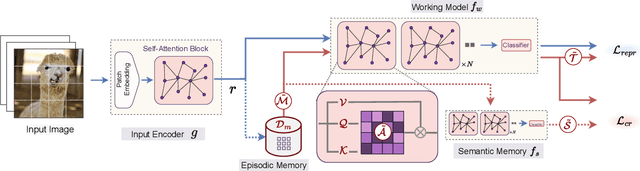
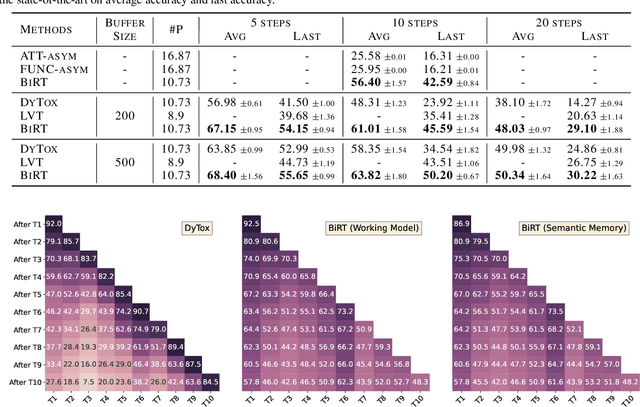
The ability of deep neural networks to continually learn and adapt to a sequence of tasks has remained challenging due to catastrophic forgetting of previously learned tasks. Humans, on the other hand, have a remarkable ability to acquire, assimilate, and transfer knowledge across tasks throughout their lifetime without catastrophic forgetting. The versatility of the brain can be attributed to the rehearsal of abstract experiences through a complementary learning system. However, representation rehearsal in vision transformers lacks diversity, resulting in overfitting and consequently, performance drops significantly compared to raw image rehearsal. Therefore, we propose BiRT, a novel representation rehearsal-based continual learning approach using vision transformers. Specifically, we introduce constructive noises at various stages of the vision transformer and enforce consistency in predictions with respect to an exponential moving average of the working model. Our method provides consistent performance gain over raw image and vanilla representation rehearsal on several challenging CL benchmarks, while being memory efficient and robust to natural and adversarial corruptions.
MixPro: Data Augmentation with MaskMix and Progressive Attention Labeling for Vision Transformer
Apr 24, 2023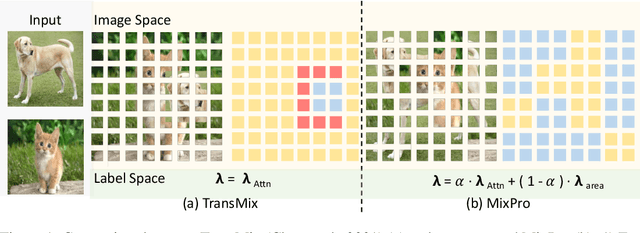
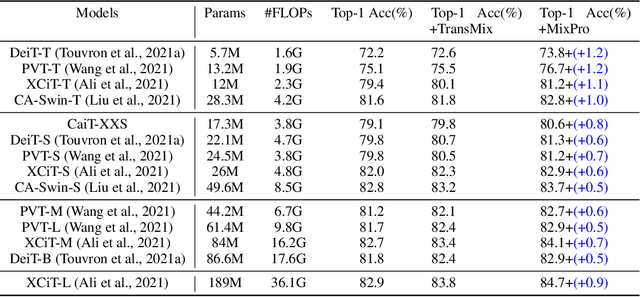
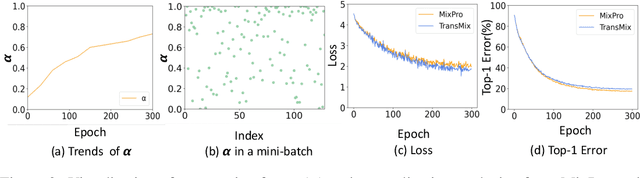
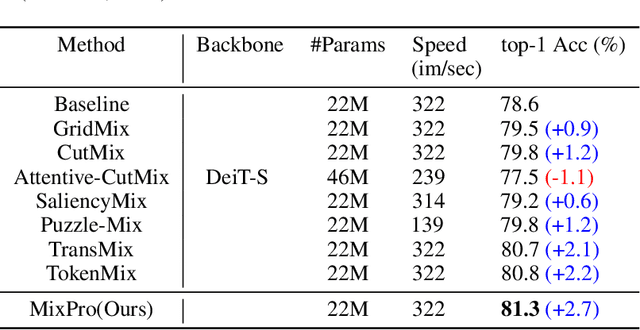
The recently proposed data augmentation TransMix employs attention labels to help visual transformers (ViT) achieve better robustness and performance. However, TransMix is deficient in two aspects: 1) The image cropping method of TransMix may not be suitable for vision transformer. 2) At the early stage of training, the model produces unreliable attention maps. TransMix uses unreliable attention maps to compute mixed attention labels that can affect the model. To address the aforementioned issues, we propose MaskMix and Progressive Attention Labeling (PAL) in image and label space, respectively. In detail, from the perspective of image space, we design MaskMix, which mixes two images based on a patch-like grid mask. In particular, the size of each mask patch is adjustable and is a multiple of the image patch size, which ensures each image patch comes from only one image and contains more global contents. From the perspective of label space, we design PAL, which utilizes a progressive factor to dynamically re-weight the attention weights of the mixed attention label. Finally, we combine MaskMix and Progressive Attention Labeling as our new data augmentation method, named MixPro. The experimental results show that our method can improve various ViT-based models at scales on ImageNet classification (73.8\% top-1 accuracy based on DeiT-T for 300 epochs). After being pre-trained with MixPro on ImageNet, the ViT-based models also demonstrate better transferability to semantic segmentation, object detection, and instance segmentation. Furthermore, compared to TransMix, MixPro also shows stronger robustness on several benchmarks. The code will be released at https://github.com/fistyee/MixPro.
Learning Thin-Plate Spline Motion and Seamless Composition for Parallax-Tolerant Unsupervised Deep Image Stitching
Feb 16, 2023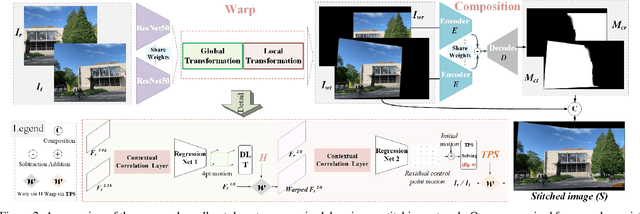
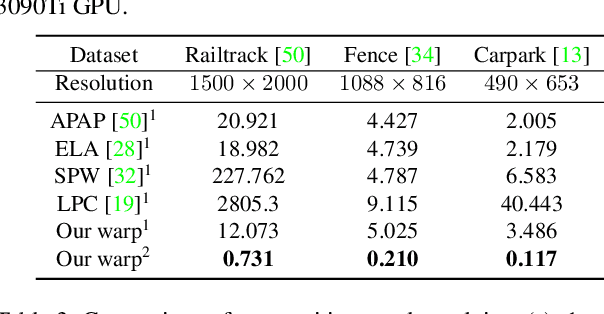

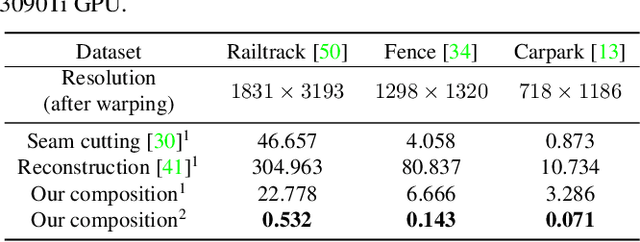
Traditional image stitching approaches tend to leverage increasingly complex geometric features (point, line, edge, etc.) for better performance. However, these hand-crafted features are only suitable for specific natural scenes with adequate geometric structures. In contrast, deep stitching schemes overcome the adverse conditions by adaptively learning robust semantic features, but they cannot handle large-parallax cases due to homography-based registration. To solve these issues, we propose UDIS++, a parallax-tolerant unsupervised deep image stitching technique. First, we propose a robust and flexible warp to model the image registration from global homography to local thin-plate spline motion. It provides accurate alignment for overlapping regions and shape preservation for non-overlapping regions by joint optimization concerning alignment and distortion. Subsequently, to improve the generalization capability, we design a simple but effective iterative strategy to enhance the warp adaption in cross-dataset and cross-resolution applications. Finally, to further eliminate the parallax artifacts, we propose to composite the stitched image seamlessly by unsupervised learning for seam-driven composition masks. Compared with existing methods, our solution is parallax-tolerant and free from laborious designs of complicated geometric features for specific scenes. Extensive experiments show our superiority over the SoTA methods, both quantitatively and qualitatively. The code will be available at https://github.com/nie-lang/UDIS2.