 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinual Learning Beyond Experience Rehearsal and Full Model Surrogates
May 28, 2025



Continual learning (CL) has remained a significant challenge for deep neural networks as learning new tasks erases previously acquired knowledge, either partially or completely. Existing solutions often rely on experience rehearsal or full model surrogates to mitigate CF. While effective, these approaches introduce substantial memory and computational overhead, limiting their scalability and applicability in real-world scenarios. To address this, we propose SPARC, a scalable CL approach that eliminates the need for experience rehearsal and full-model surrogates. By effectively combining task-specific working memories and task-agnostic semantic memory for cross-task knowledge consolidation, SPARC results in a remarkable parameter efficiency, using only 6% of the parameters required by full-model surrogates. Despite its lightweight design, SPARC achieves superior performance on Seq-TinyImageNet and matches rehearsal-based methods on various CL benchmarks. Additionally, weight re-normalization in the classification layer mitigates task-specific biases, establishing SPARC as a practical and scalable solution for CL under stringent efficiency constraints.
Mitigating Interference in the Knowledge Continuum through Attention-Guided Incremental Learning
May 22, 2024Continual learning (CL) remains a significant challenge for deep neural networks, as it is prone to forgetting previously acquired knowledge. Several approaches have been proposed in the literature, such as experience rehearsal, regularization, and parameter isolation, to address this problem. Although almost zero forgetting can be achieved in task-incremental learning, class-incremental learning remains highly challenging due to the problem of inter-task class separation. Limited access to previous task data makes it difficult to discriminate between classes of current and previous tasks. To address this issue, we propose `Attention-Guided Incremental Learning' (AGILE), a novel rehearsal-based CL approach that incorporates compact task attention to effectively reduce interference between tasks. AGILE utilizes lightweight, learnable task projection vectors to transform the latent representations of a shared task attention module toward task distribution. Through extensive empirical evaluation, we show that AGILE significantly improves generalization performance by mitigating task interference and outperforming rehearsal-based approaches in several CL scenarios. Furthermore, AGILE can scale well to a large number of tasks with minimal overhead while remaining well-calibrated with reduced task-recency bias.
IMEX-Reg: Implicit-Explicit Regularization in the Function Space for Continual Learning
Apr 28, 2024Continual learning (CL) remains one of the long-standing challenges for deep neural networks due to catastrophic forgetting of previously acquired knowledge. Although rehearsal-based approaches have been fairly successful in mitigating catastrophic forgetting, they suffer from overfitting on buffered samples and prior information loss, hindering generalization under low-buffer regimes. Inspired by how humans learn using strong inductive biases, we propose IMEX-Reg to improve the generalization performance of experience rehearsal in CL under low buffer regimes. Specifically, we employ a two-pronged implicit-explicit regularization approach using contrastive representation learning (CRL) and consistency regularization. To further leverage the global relationship between representations learned using CRL, we propose a regularization strategy to guide the classifier toward the activation correlations in the unit hypersphere of the CRL. Our results show that IMEX-Reg significantly improves generalization performance and outperforms rehearsal-based approaches in several CL scenarios. It is also robust to natural and adversarial corruptions with less task-recency bias. Additionally, we provide theoretical insights to support our design decisions further.
TriRE: A Multi-Mechanism Learning Paradigm for Continual Knowledge Retention and Promotion
Oct 12, 2023Continual learning (CL) has remained a persistent challenge for deep neural networks due to catastrophic forgetting (CF) of previously learned tasks. Several techniques such as weight regularization, experience rehearsal, and parameter isolation have been proposed to alleviate CF. Despite their relative success, these research directions have predominantly remained orthogonal and suffer from several shortcomings, while missing out on the advantages of competing strategies. On the contrary, the brain continually learns, accommodates, and transfers knowledge across tasks by simultaneously leveraging several neurophysiological processes, including neurogenesis, active forgetting, neuromodulation, metaplasticity, experience rehearsal, and context-dependent gating, rarely resulting in CF. Inspired by how the brain exploits multiple mechanisms concurrently, we propose TriRE, a novel CL paradigm that encompasses retaining the most prominent neurons for each task, revising and solidifying the extracted knowledge of current and past tasks, and actively promoting less active neurons for subsequent tasks through rewinding and relearning. Across CL settings, TriRE significantly reduces task interference and surpasses different CL approaches considered in isolation.
BiRT: Bio-inspired Replay in Vision Transformers for Continual Learning
May 08, 2023The ability of deep neural networks to continually learn and adapt to a sequence of tasks has remained challenging due to catastrophic forgetting of previously learned tasks. Humans, on the other hand, have a remarkable ability to acquire, assimilate, and transfer knowledge across tasks throughout their lifetime without catastrophic forgetting. The versatility of the brain can be attributed to the rehearsal of abstract experiences through a complementary learning system. However, representation rehearsal in vision transformers lacks diversity, resulting in overfitting and consequently, performance drops significantly compared to raw image rehearsal. Therefore, we propose BiRT, a novel representation rehearsal-based continual learning approach using vision transformers. Specifically, we introduce constructive noises at various stages of the vision transformer and enforce consistency in predictions with respect to an exponential moving average of the working model. Our method provides consistent performance gain over raw image and vanilla representation rehearsal on several challenging CL benchmarks, while being memory efficient and robust to natural and adversarial corruptions.
Task-Aware Information Routing from Common Representation Space in Lifelong Learning
Feb 14, 2023Intelligent systems deployed in the real world suffer from catastrophic forgetting when exposed to a sequence of tasks. Humans, on the other hand, acquire, consolidate, and transfer knowledge between tasks that rarely interfere with the consolidated knowledge. Accompanied by self-regulated neurogenesis, continual learning in the brain is governed by a rich set of neurophysiological processes that harbor different types of knowledge, which are then integrated by conscious processing. Thus, inspired by the Global Workspace Theory of conscious information access in the brain, we propose TAMiL, a continual learning method that entails task-attention modules to capture task-specific information from the common representation space. We employ simple, undercomplete autoencoders to create a communication bottleneck between the common representation space and the global workspace, allowing only the task-relevant information to the global workspace, thus greatly reducing task interference. Experimental results show that our method outperforms state-of-the-art rehearsal-based and dynamic sparse approaches and bridges the gap between fixed capacity and parameter isolation approaches while being scalable. We also show that our method effectively mitigates catastrophic forgetting while being well-calibrated with reduced task-recency bias.
Task Agnostic Representation Consolidation: a Self-supervised based Continual Learning Approach
Jul 13, 2022



Continual learning (CL) over non-stationary data streams remains one of the long-standing challenges in deep neural networks (DNNs) as they are prone to catastrophic forgetting. CL models can benefit from self-supervised pre-training as it enables learning more generalizable task-agnostic features. However, the effect of self-supervised pre-training diminishes as the length of task sequences increases. Furthermore, the domain shift between pre-training data distribution and the task distribution reduces the generalizability of the learned representations. To address these limitations, we propose Task Agnostic Representation Consolidation (TARC), a two-stage training paradigm for CL that intertwines task-agnostic and task-specific learning whereby self-supervised training is followed by supervised learning for each task. To further restrict the deviation from the learned representations in the self-supervised stage, we employ a task-agnostic auxiliary loss during the supervised stage. We show that our training paradigm can be easily added to memory- or regularization-based approaches and provides consistent performance gain across more challenging CL settings. We further show that it leads to more robust and well-calibrated models.
Consistency is the key to further mitigating catastrophic forgetting in continual learning
Jul 11, 2022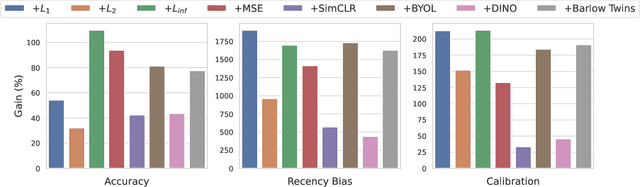
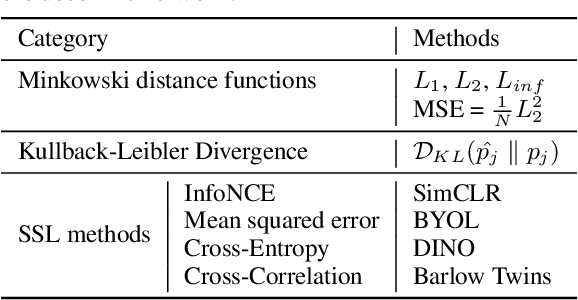

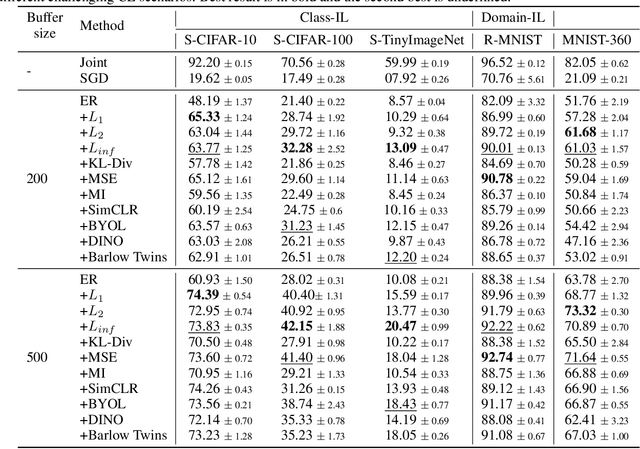
Deep neural networks struggle to continually learn multiple sequential tasks due to catastrophic forgetting of previously learned tasks. Rehearsal-based methods which explicitly store previous task samples in the buffer and interleave them with the current task samples have proven to be the most effective in mitigating forgetting. However, Experience Replay (ER) does not perform well under low-buffer regimes and longer task sequences as its performance is commensurate with the buffer size. Consistency in predictions of soft-targets can assist ER in preserving information pertaining to previous tasks better as soft-targets capture the rich similarity structure of the data. Therefore, we examine the role of consistency regularization in ER framework under various continual learning scenarios. We also propose to cast consistency regularization as a self-supervised pretext task thereby enabling the use of a wide variety of self-supervised learning methods as regularizers. While simultaneously enhancing model calibration and robustness to natural corruptions, regularizing consistency in predictions results in lesser forgetting across all continual learning scenarios. Among the different families of regularizers, we find that stricter consistency constraints preserve previous task information in ER better.
Distill on the Go: Online knowledge distillation in self-supervised learning
Apr 20, 2021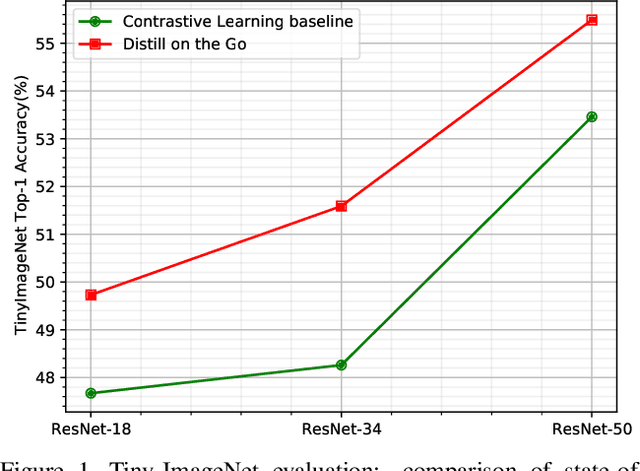
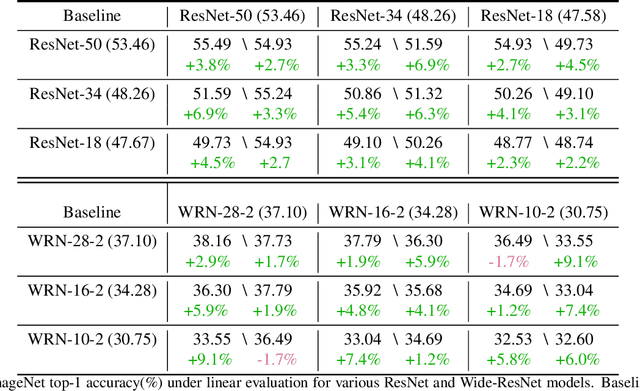
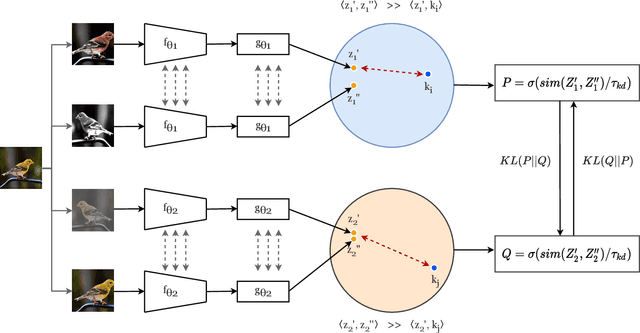
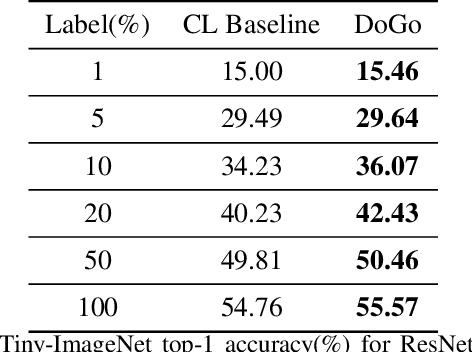
Self-supervised learning solves pretext prediction tasks that do not require annotations to learn feature representations. For vision tasks, pretext tasks such as predicting rotation, solving jigsaw are solely created from the input data. Yet, predicting this known information helps in learning representations useful for downstream tasks. However, recent works have shown that wider and deeper models benefit more from self-supervised learning than smaller models. To address the issue of self-supervised pre-training of smaller models, we propose Distill-on-the-Go (DoGo), a self-supervised learning paradigm using single-stage online knowledge distillation to improve the representation quality of the smaller models. We employ deep mutual learning strategy in which two models collaboratively learn from each other to improve one another. Specifically, each model is trained using self-supervised learning along with distillation that aligns each model's softmax probabilities of similarity scores with that of the peer model. We conduct extensive experiments on multiple benchmark datasets, learning objectives, and architectures to demonstrate the potential of our proposed method. Our results show significant performance gain in the presence of noisy and limited labels and generalization to out-of-distribution data.