 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Single-Stage 3D Geometry-Preserving Depth Estimation Model Training on Dataset Mixtures with Uncalibrated Stereo Data
Jun 05, 2023
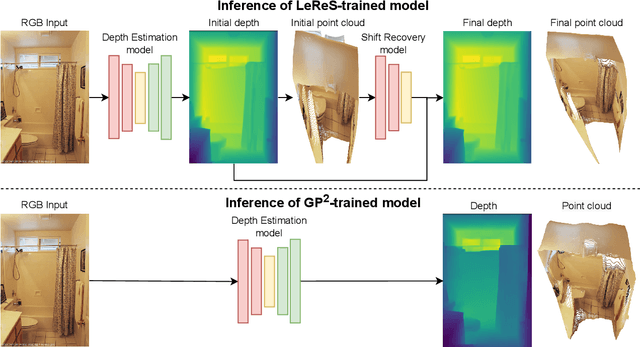
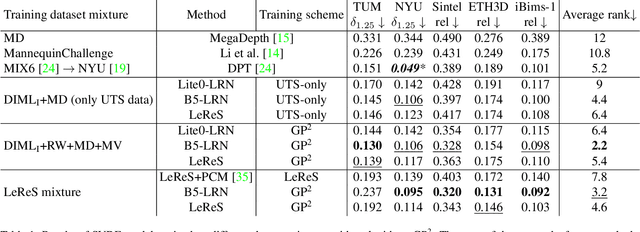
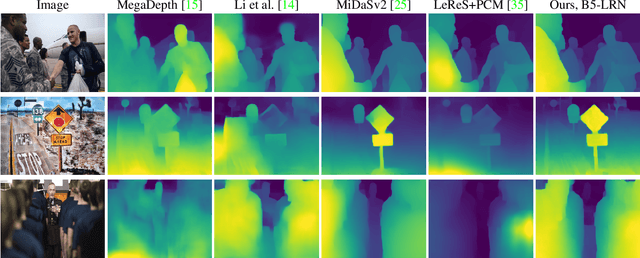

Nowadays, robotics, AR, and 3D modeling applications attract considerable attention to single-view depth estimation (SVDE) as it allows estimating scene geometry from a single RGB image. Recent works have demonstrated that the accuracy of an SVDE method hugely depends on the diversity and volume of the training data. However, RGB-D datasets obtained via depth capturing or 3D reconstruction are typically small, synthetic datasets are not photorealistic enough, and all these datasets lack diversity. The large-scale and diverse data can be sourced from stereo images or stereo videos from the web. Typically being uncalibrated, stereo data provides disparities up to unknown shift (geometrically incomplete data), so stereo-trained SVDE methods cannot recover 3D geometry. It was recently shown that the distorted point clouds obtained with a stereo-trained SVDE method can be corrected with additional point cloud modules (PCM) separately trained on the geometrically complete data. On the contrary, we propose GP$^{2}$, General-Purpose and Geometry-Preserving training scheme, and show that conventional SVDE models can learn correct shifts themselves without any post-processing, benefiting from using stereo data even in the geometry-preserving setting. Through experiments on different dataset mixtures, we prove that GP$^{2}$-trained models outperform methods relying on PCM in both accuracy and speed, and report the state-of-the-art results in the general-purpose geometry-preserving SVDE. Moreover, we show that SVDE models can learn to predict geometrically correct depth even when geometrically complete data comprises the minor part of the training set.
LowDINO -- A Low Parameter Self Supervised Learning Model
May 28, 2023
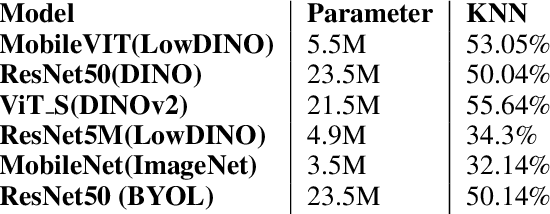

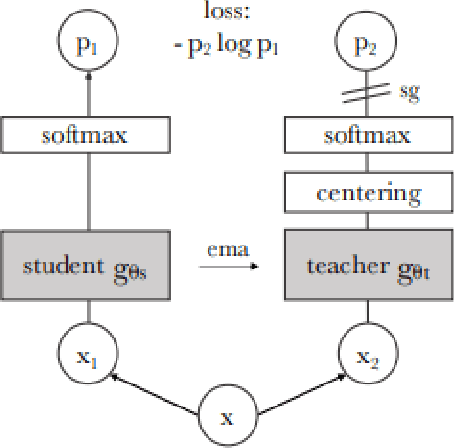
This research aims to explore the possibility of designing a neural network architecture that allows for small networks to adopt the properties of huge networks, which have shown success in self-supervised learning (SSL), for all the downstream tasks like image classification, segmentation, etc. Previous studies have shown that using convolutional neural networks (ConvNets) can provide inherent inductive bias, which is crucial for learning representations in deep learning models. To reduce the number of parameters, attention mechanisms are utilized through the usage of MobileViT blocks, resulting in a model with less than 5 million parameters. The model is trained using self-distillation with momentum encoder and a student-teacher architecture is also employed, where the teacher weights use vision transformers (ViTs) from recent SOTA SSL models. The model is trained on the ImageNet1k dataset. This research provides an approach for designing smaller, more efficient neural network architectures that can perform SSL tasks comparable to heavy models
SimpSON: Simplifying Photo Cleanup with Single-Click Distracting Object Segmentation Network
May 28, 2023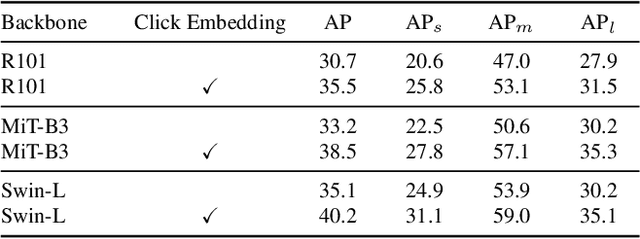
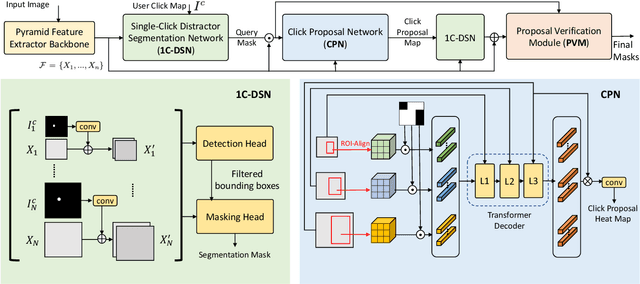
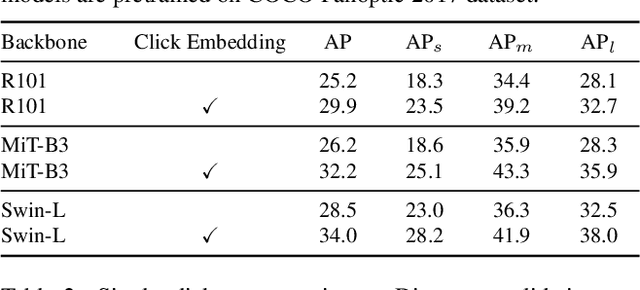
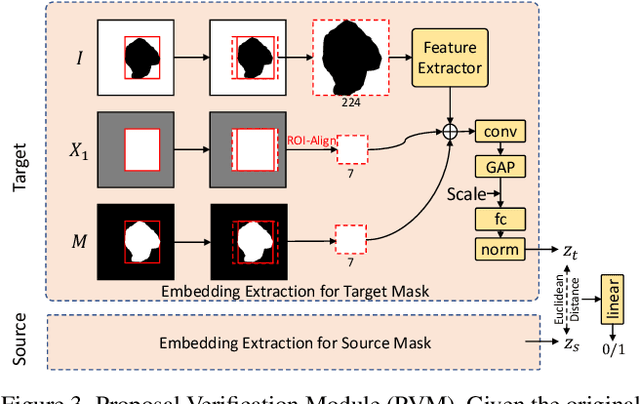
In photo editing, it is common practice to remove visual distractions to improve the overall image quality and highlight the primary subject. However, manually selecting and removing these small and dense distracting regions can be a laborious and time-consuming task. In this paper, we propose an interactive distractor selection method that is optimized to achieve the task with just a single click. Our method surpasses the precision and recall achieved by the traditional method of running panoptic segmentation and then selecting the segments containing the clicks. We also showcase how a transformer-based module can be used to identify more distracting regions similar to the user's click position. Our experiments demonstrate that the model can effectively and accurately segment unknown distracting objects interactively and in groups. By significantly simplifying the photo cleaning and retouching process, our proposed model provides inspiration for exploring rare object segmentation and group selection with a single click.
Lighting and Rotation Invariant Real-time Vehicle Wheel Detector based on YOLOv5
May 28, 2023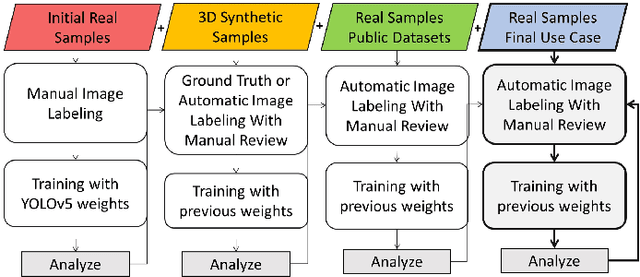
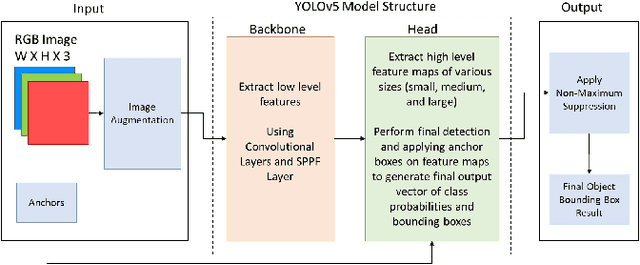
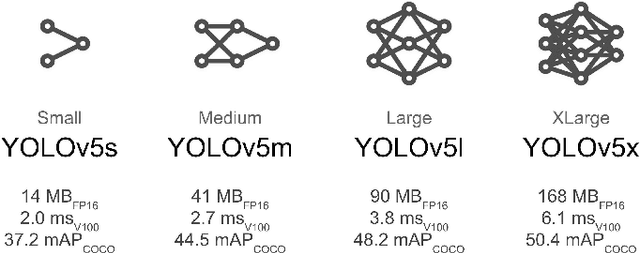

Creating an object detector, in computer vision, has some common challenges when initially developed based on Convolutional Neural Network (CNN) architecture. These challenges are more apparent when creating model that needs to adapt to images captured by various camera orientations, lighting conditions, and environmental changes. The availability of the initial training samples to cover all these conditions can be an enormous challenge with a time and cost burden. While the problem can exist when creating any type of object detection, some types are less common and have no pre-labeled image datasets that exists publicly. Sometime public datasets are not reliable nor comprehensive for a rare object type. Vehicle wheel is one of those example that been chosen to demonstrate the approach of creating a lighting and rotation invariant real-time detector based on YOLOv5 architecture. The objective is to provide a simple approach that could be used as a reference for developing other types of real-time object detectors.
A Vision Transformer Approach for Efficient Near-Field Irregular SAR Super-Resolution
May 03, 2023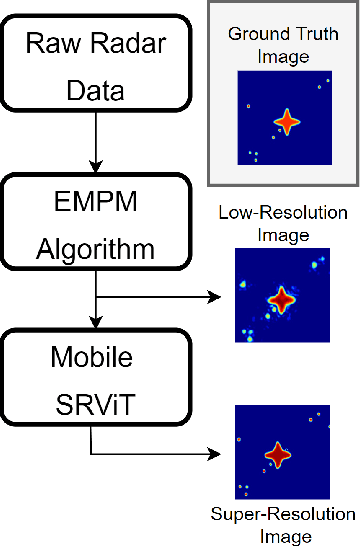

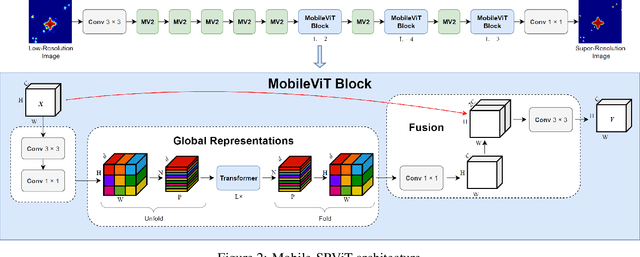
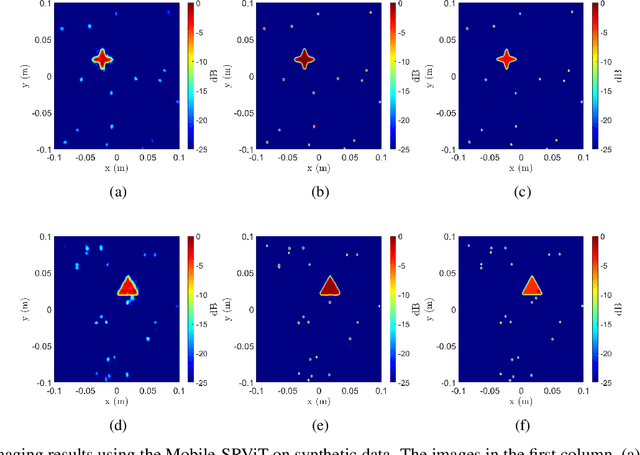
In this paper, we develop a novel super-resolution algorithm for near-field synthetic-aperture radar (SAR) under irregular scanning geometries. As fifth-generation (5G) millimeter-wave (mmWave) devices are becoming increasingly affordable and available, high-resolution SAR imaging is feasible for end-user applications and non-laboratory environments. Emerging applications such freehand imaging, wherein a handheld radar is scanned throughout space by a user, unmanned aerial vehicle (UAV) imaging, and automotive SAR face several unique challenges for high-resolution imaging. First, recovering a SAR image requires knowledge of the array positions throughout the scan. While recent work has introduced camera-based positioning systems capable of adequately estimating the position, recovering the algorithm efficiently is a requirement to enable edge and Internet of Things (IoT) technologies. Efficient algorithms for non-cooperative near-field SAR sampling have been explored in recent work, but suffer image defocusing under position estimation error and can only produce medium-fidelity images. In this paper, we introduce a mobile-friend vision transformer (ViT) architecture to address position estimation error and perform SAR image super-resolution (SR) under irregular sampling geometries. The proposed algorithm, Mobile-SRViT, is the first to employ a ViT approach for SAR image enhancement and is validated in simulation and via empirical studies.
Representing Noisy Image Without Denoising
Jan 18, 2023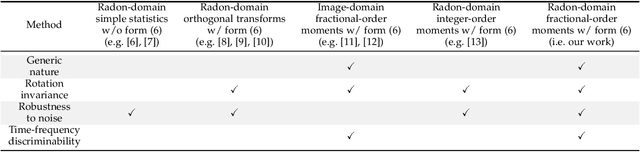
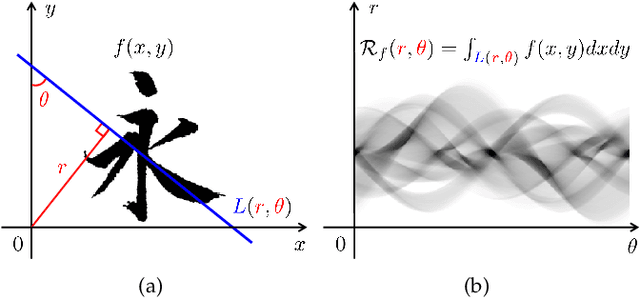
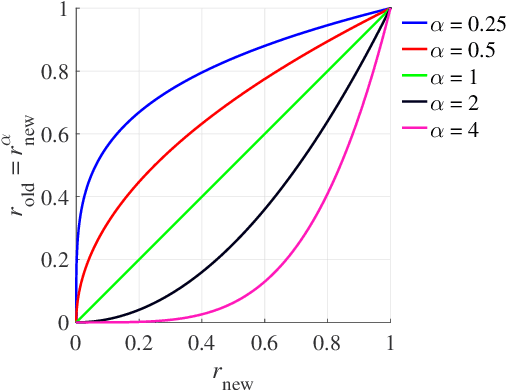
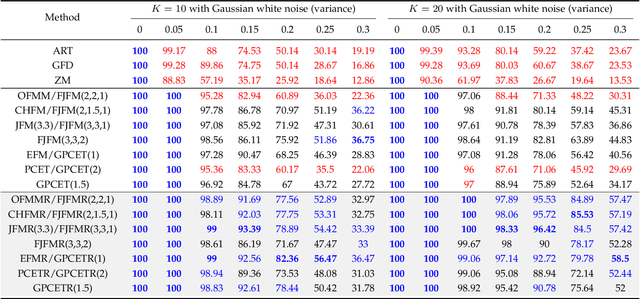
A long-standing topic in artificial intelligence is the effective recognition of patterns from noisy images. In this regard, the recent data-driven paradigm considers 1) improving the representation robustness by adding noisy samples in training phase (i.e., data augmentation) or 2) pre-processing the noisy image by learning to solve the inverse problem (i.e., image denoising). However, such methods generally exhibit inefficient process and unstable result, limiting their practical applications. In this paper, we explore a non-learning paradigm that aims to derive robust representation directly from noisy images, without the denoising as pre-processing. Here, the noise-robust representation is designed as Fractional-order Moments in Radon space (FMR), with also beneficial properties of orthogonality and rotation invariance. Unlike earlier integer-order methods, our work is a more generic design taking such classical methods as special cases, and the introduced fractional-order parameter offers time-frequency analysis capability that is not available in classical methods. Formally, both implicit and explicit paths for constructing the FMR are discussed in detail. Extensive simulation experiments and an image security application are provided to demonstrate the uniqueness and usefulness of our FMR, especially for noise robustness, rotation invariance, and time-frequency discriminability.
HAISTA-NET: Human Assisted Instance Segmentation Through Attention
May 12, 2023
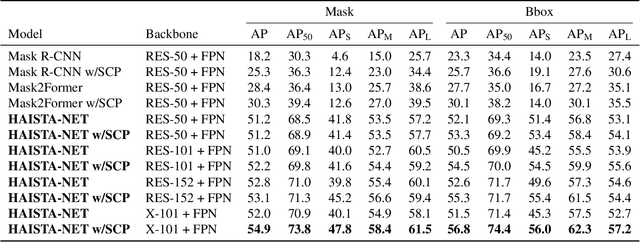

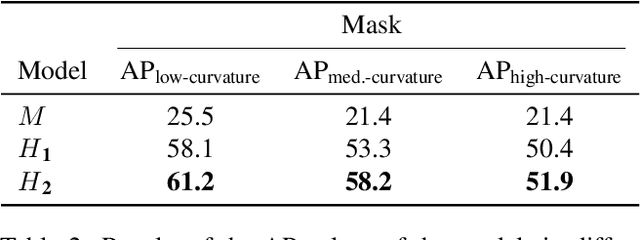
Instance segmentation is a form of image detection which has a range of applications, such as object refinement, medical image analysis, and image/video editing, all of which demand a high degree of accuracy. However, this precision is often beyond the reach of what even state-of-the-art, fully automated instance segmentation algorithms can deliver. The performance gap becomes particularly prohibitive for small and complex objects. Practitioners typically resort to fully manual annotation, which can be a laborious process. In order to overcome this problem, we propose a novel approach to enable more precise predictions and generate higher-quality segmentation masks for high-curvature, complex and small-scale objects. Our human-assisted segmentation model, HAISTA-NET, augments the existing Strong Mask R-CNN network to incorporate human-specified partial boundaries. We also present a dataset of hand-drawn partial object boundaries, which we refer to as human attention maps. In addition, the Partial Sketch Object Boundaries (PSOB) dataset contains hand-drawn partial object boundaries which represent curvatures of an object's ground truth mask with several pixels. Through extensive evaluation using the PSOB dataset, we show that HAISTA-NET outperforms state-of-the art methods such as Mask R-CNN, Strong Mask R-CNN, and Mask2Former, achieving respective increases of +36.7, +29.6, and +26.5 points in AP-Mask metrics for these three models. We hope that our novel approach will set a baseline for future human-aided deep learning models by combining fully automated and interactive instance segmentation architectures.
Unsupervised Anomaly Detection in Medical Images Using Masked Diffusion Model
May 31, 2023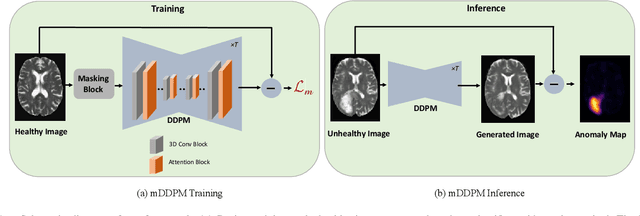
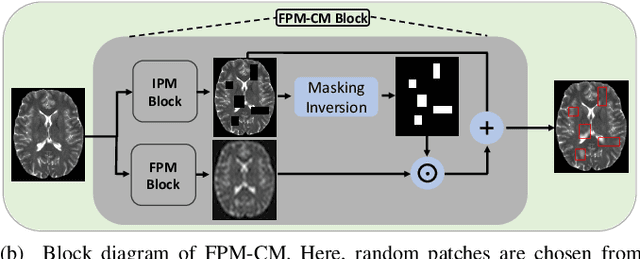
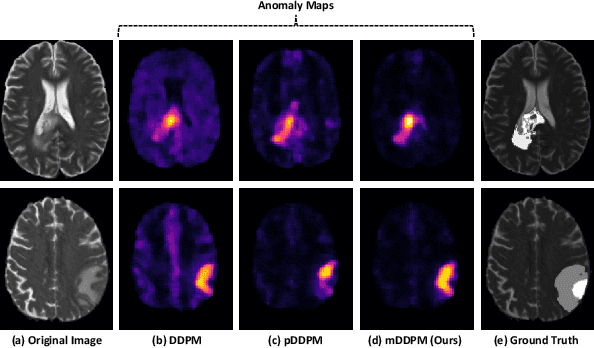
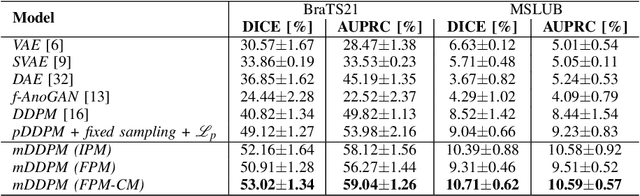
It can be challenging to identify brain MRI anomalies using supervised deep-learning techniques due to anatomical heterogeneity and the requirement for pixel-level labeling. Unsupervised anomaly detection approaches provide an alternative solution by relying only on sample-level labels of healthy brains to generate a desired representation to identify abnormalities at the pixel level. Although, generative models are crucial for generating such anatomically consistent representations of healthy brains, accurately generating the intricate anatomy of the human brain remains a challenge. In this study, we present a method called masked-DDPM (mDPPM), which introduces masking-based regularization to reframe the generation task of diffusion models. Specifically, we introduce Masked Image Modeling (MIM) and Masked Frequency Modeling (MFM) in our self-supervised approach that enables models to learn visual representations from unlabeled data. To the best of our knowledge, this is the first attempt to apply MFM in DPPM models for medical applications. We evaluate our approach on datasets containing tumors and numerous sclerosis lesions and exhibit the superior performance of our unsupervised method as compared to the existing fully/weakly supervised baselines. Code is available at https://github.com/hasan1292/mDDPM.
Probabilistic Uncertainty Quantification of Prediction Models with Application to Visual Localization
May 31, 2023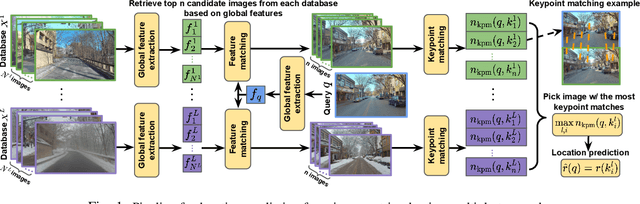
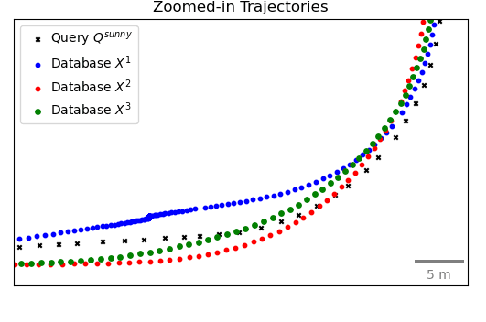
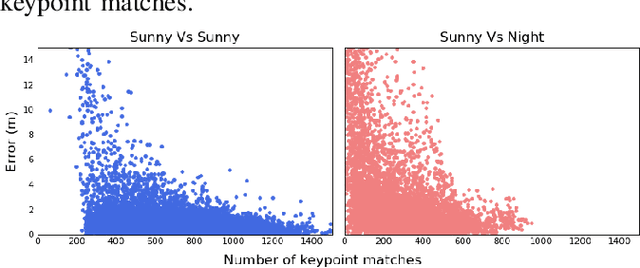
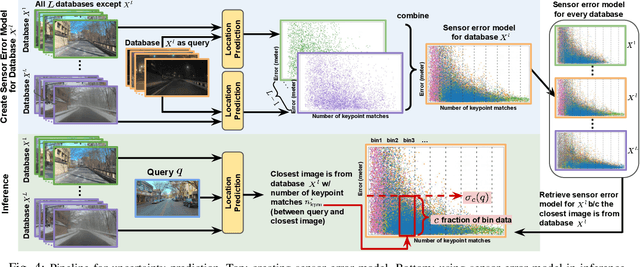
The uncertainty quantification of prediction models (e.g., neural networks) is crucial for their adoption in many robotics applications. This is arguably as important as making accurate predictions, especially for safety-critical applications such as self-driving cars. This paper proposes our approach to uncertainty quantification in the context of visual localization for autonomous driving, where we predict locations from images. Our proposed framework estimates probabilistic uncertainty by creating a sensor error model that maps an internal output of the prediction model to the uncertainty. The sensor error model is created using multiple image databases of visual localization, each with ground-truth location. We demonstrate the accuracy of our uncertainty prediction framework using the Ithaca365 dataset, which includes variations in lighting, weather (sunny, snowy, night), and alignment errors between databases. We analyze both the predicted uncertainty and its incorporation into a Kalman-based localization filter. Our results show that prediction error variations increase with poor weather and lighting condition, leading to greater uncertainty and outliers, which can be predicted by our proposed uncertainty model. Additionally, our probabilistic error model enables the filter to remove ad hoc sensor gating, as the uncertainty automatically adjusts the model to the input data
STAIR: Learning Sparse Text and Image Representation in Grounded Tokens
Jan 30, 2023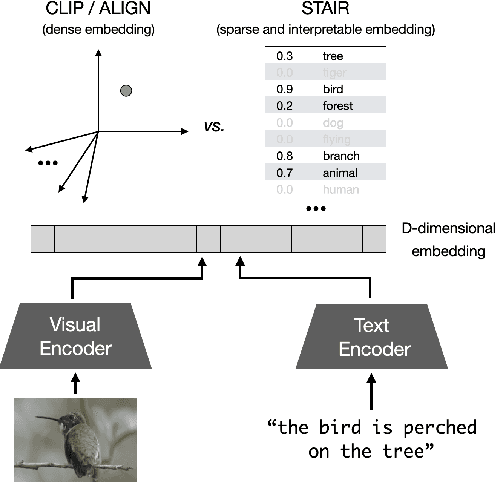

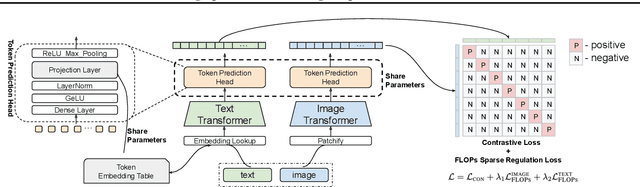

Image and text retrieval is one of the foundational tasks in the vision and language domain with multiple real-world applications. State-of-the-art approaches, e.g. CLIP, ALIGN, represent images and texts as dense embeddings and calculate the similarity in the dense embedding space as the matching score. On the other hand, sparse semantic features like bag-of-words models are more interpretable, but believed to suffer from inferior accuracy than dense representations. In this work, we show that it is possible to build a sparse semantic representation that is as powerful as, or even better than, dense presentations. We extend the CLIP model and build a sparse text and image representation (STAIR), where the image and text are mapped to a sparse token space. Each token in the space is a (sub-)word in the vocabulary, which is not only interpretable but also easy to integrate with existing information retrieval systems. STAIR model significantly outperforms a CLIP model with +$4.9\%$ and +$4.3\%$ absolute Recall@1 improvement on COCO-5k text$\rightarrow$image and image$\rightarrow$text retrieval respectively. It also achieved better performance on both of ImageNet zero-shot and linear probing compared to CLIP.