 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
LiT-4-RSVQA: Lightweight Transformer-based Visual Question Answering in Remote Sensing
Jun 02, 2023
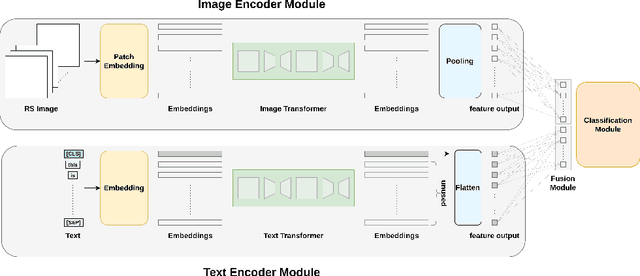
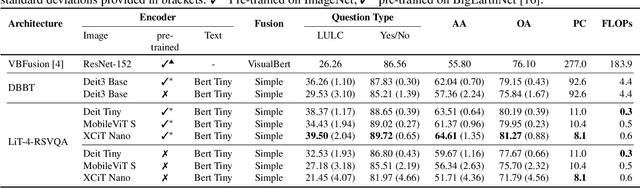
Visual question answering (VQA) methods in remote sensing (RS) aim to answer natural language questions with respect to an RS image. Most of the existing methods require a large amount of computational resources, which limits their application in operational scenarios in RS. To address this issue, in this paper we present an effective lightweight transformer-based VQA in RS (LiT-4-RSVQA) architecture for efficient and accurate VQA in RS. Our architecture consists of: i) a lightweight text encoder module; ii) a lightweight image encoder module; iii) a fusion module; and iv) a classification module. The experimental results obtained on a VQA benchmark dataset demonstrate that our proposed LiT-4-RSVQA architecture provides accurate VQA results while significantly reducing the computational requirements on the executing hardware. Our code is publicly available at https://git.tu-berlin.de/rsim/lit4rsvqa.
Generative Adversarial Networks for Brain Images Synthesis: A Review
May 16, 2023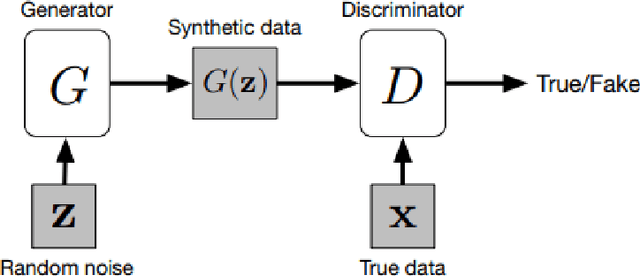
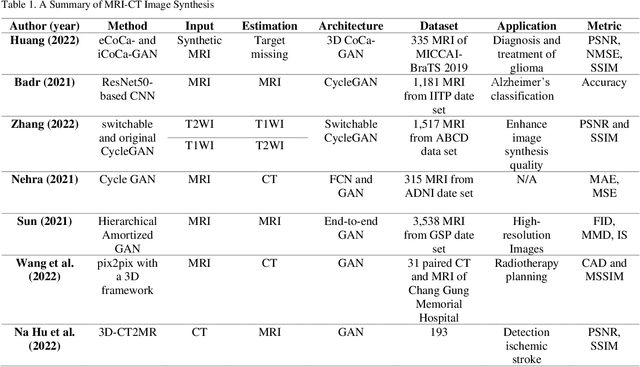
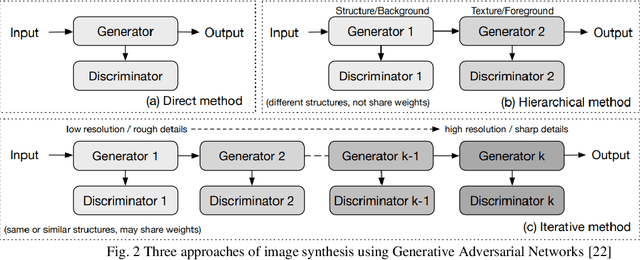
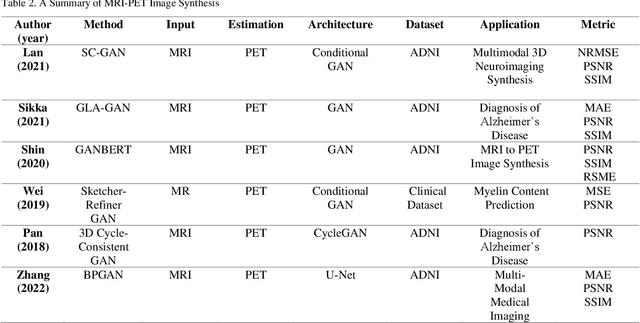
In medical imaging, image synthesis is the estimation process of one image (sequence, modality) from another image (sequence, modality). Since images with different modalities provide diverse biomarkers and capture various features, multi-modality imaging is crucial in medicine. While multi-screening is expensive, costly, and time-consuming to report by radiologists, image synthesis methods are capable of artificially generating missing modalities. Deep learning models can automatically capture and extract the high dimensional features. Especially, generative adversarial network (GAN) as one of the most popular generative-based deep learning methods, uses convolutional networks as generators, and estimated images are discriminated as true or false based on a discriminator network. This review provides brain image synthesis via GANs. We summarized the recent developments of GANs for cross-modality brain image synthesis including CT to PET, CT to MRI, MRI to PET, and vice versa.
Quality-aware Pre-trained Models for Blind Image Quality Assessment
Mar 01, 2023


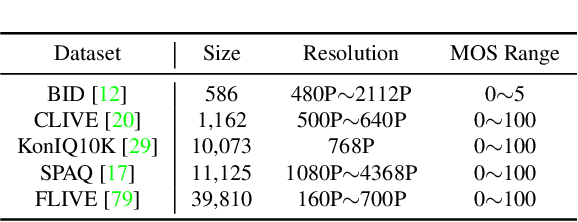
Blind image quality assessment (BIQA) aims to automatically evaluate the perceived quality of a single image, whose performance has been improved by deep learning-based methods in recent years. However, the paucity of labeled data somewhat restrains deep learning-based BIQA methods from unleashing their full potential. In this paper, we propose to solve the problem by a pretext task customized for BIQA in a self-supervised learning manner, which enables learning representations from orders of magnitude more data. To constrain the learning process, we propose a quality-aware contrastive loss based on a simple assumption: the quality of patches from a distorted image should be similar, but vary from patches from the same image with different degradations and patches from different images. Further, we improve the existing degradation process and form a degradation space with the size of roughly $2\times10^7$. After pre-trained on ImageNet using our method, models are more sensitive to image quality and perform significantly better on downstream BIQA tasks. Experimental results show that our method obtains remarkable improvements on popular BIQA datasets.
Enhancing Vision-Language Pre-Training with Jointly Learned Questioner and Dense Captioner
May 19, 2023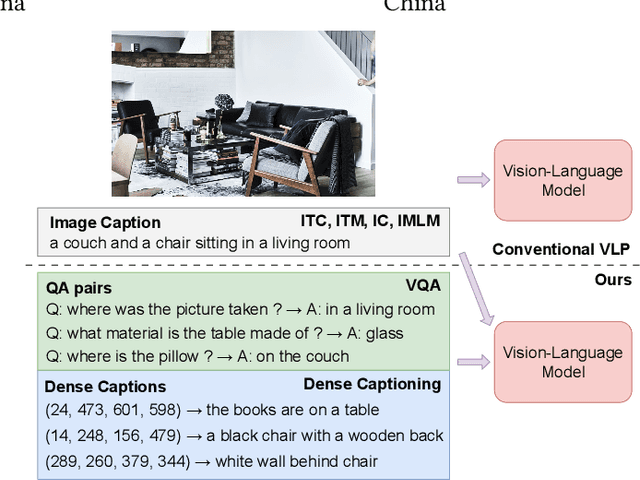
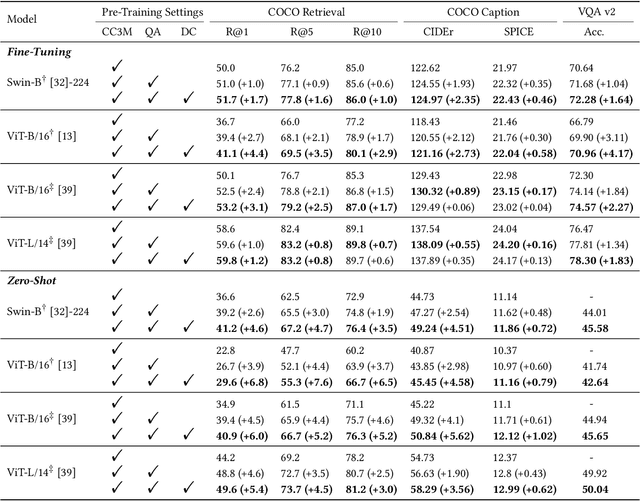
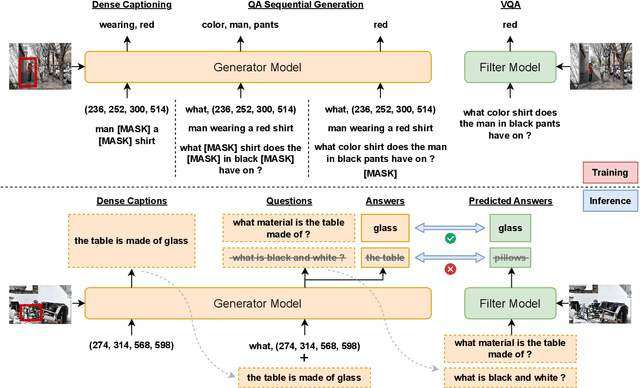
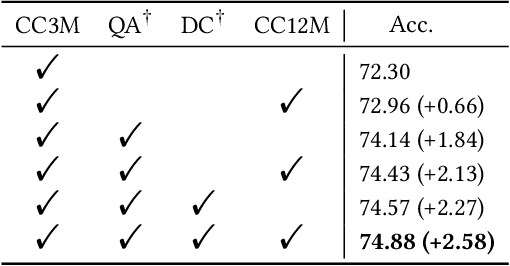
Large pre-trained multimodal models have demonstrated significant success in a range of downstream tasks, including image captioning, image-text retrieval, visual question answering (VQA), etc. However, many of these methods rely on image-text pairs collected from the web as pre-training data and unfortunately overlook the need for fine-grained feature alignment between vision and language modalities, which requires detailed understanding of images and language expressions. While integrating VQA and dense captioning (DC) into pre-training can address this issue, acquiring image-question-answer as well as image-location-caption triplets is challenging and time-consuming. Additionally, publicly available datasets for VQA and dense captioning are typically limited in scale due to manual data collection and labeling efforts. In this paper, we propose a novel method called Joint QA and DC GEneration (JADE), which utilizes a pre-trained multimodal model and easily-crawled image-text pairs to automatically generate and filter large-scale VQA and dense captioning datasets. We apply this method to the Conceptual Caption (CC3M) dataset to generate a new dataset called CC3M-QA-DC. Experiments show that when used for pre-training in a multi-task manner, CC3M-QA-DC can improve the performance with various backbones on various downstream tasks. Furthermore, our generated CC3M-QA-DC can be combined with larger image-text datasets (e.g., CC15M) and achieve competitive results compared with models using much more data. Code and dataset will be released.
To Fold or Not to Fold: Graph Regularized Tensor Train for Visual Data Completion
Jun 19, 2023
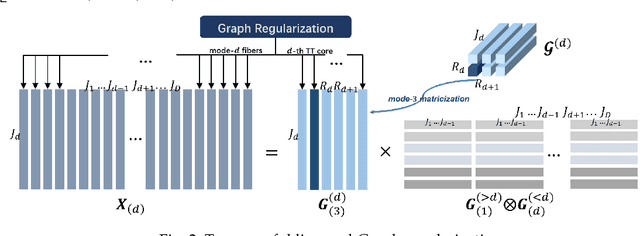
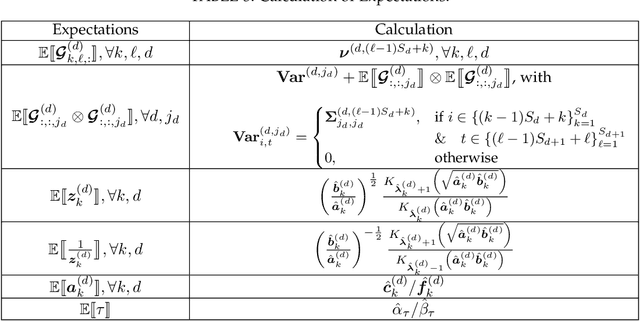
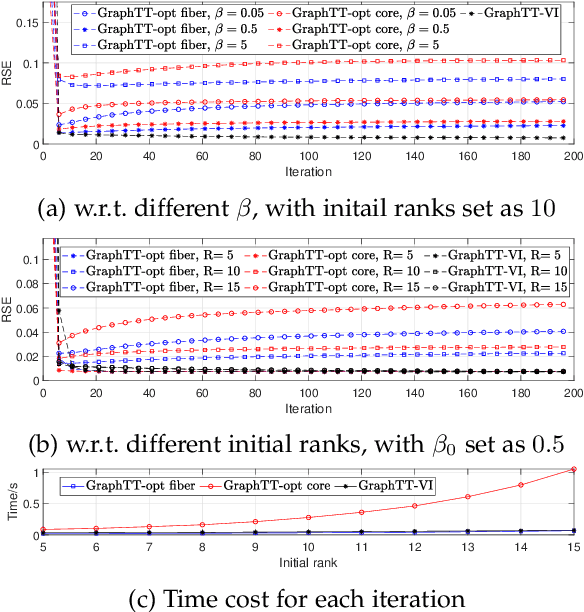
Tensor train (TT) representation has achieved tremendous success in visual data completion tasks, especially when it is combined with tensor folding. However, folding an image or video tensor breaks the original data structure, leading to local information loss as nearby pixels may be assigned into different dimensions and become far away from each other. In this paper, to fully preserve the local information of the original visual data, we explore not folding the data tensor, and at the same time adopt graph information to regularize local similarity between nearby entries. To overcome the high computational complexity introduced by the graph-based regularization in the TT completion problem, we propose to break the original problem into multiple sub-problems with respect to each TT core fiber, instead of each TT core as in traditional methods. Furthermore, to avoid heavy parameter tuning, a sparsity promoting probabilistic model is built based on the generalized inverse Gaussian (GIG) prior, and an inference algorithm is derived under the mean-field approximation. Experiments on both synthetic data and real-world visual data show the superiority of the proposed methods.
Understanding the Effect of the Long Tail on Neural Network Compression
Jun 19, 2023
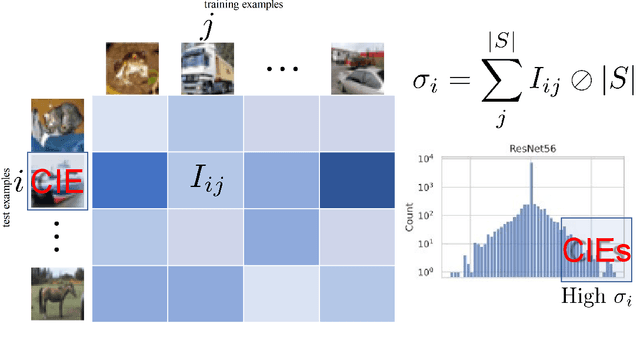
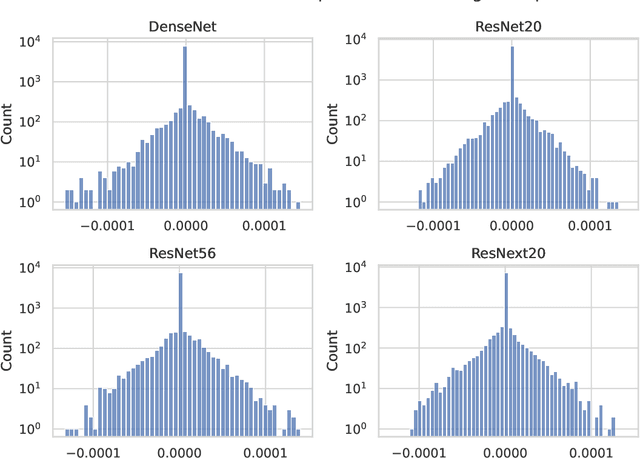
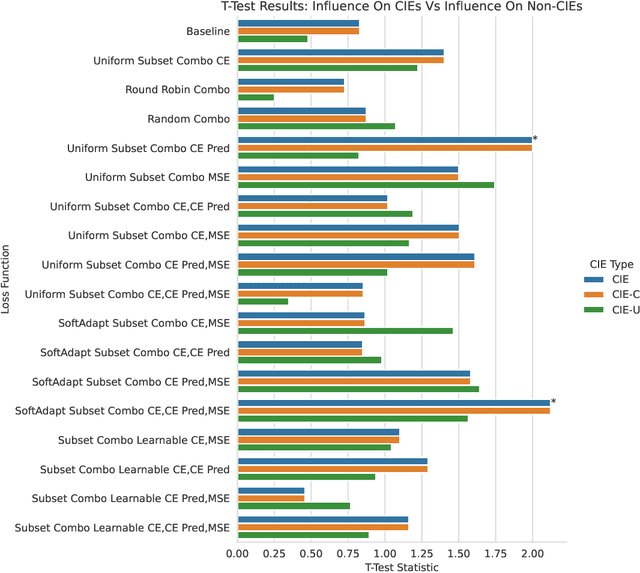
Network compression is now a mature sub-field of neural network research: over the last decade, significant progress has been made towards reducing the size of models and speeding up inference, while maintaining the classification accuracy. However, many works have observed that focusing on just the overall accuracy can be misguided. E.g., it has been shown that mismatches between the full and compressed models can be biased towards under-represented classes. This raises the important research question, \emph{can we achieve network compression while maintaining ``semantic equivalence'' with the original network?} In this work, we study this question in the context of the ``long tail'' phenomenon in computer vision datasets observed by Feldman, et al. They argue that \emph{memorization} of certain inputs (appropriately defined) is essential to achieving good generalization. As compression limits the capacity of a network (and hence also its ability to memorize), we study the question: are mismatches between the full and compressed models correlated with the memorized training data? We present positive evidence in this direction for image classification tasks, by considering different base architectures and compression schemes.
Context-Based Trit-Plane Coding for Progressive Image Compression
Mar 13, 2023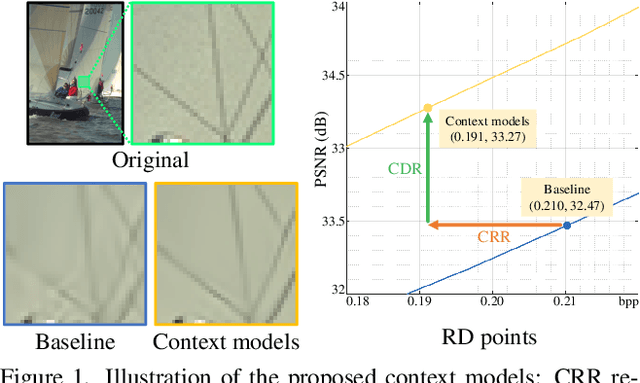
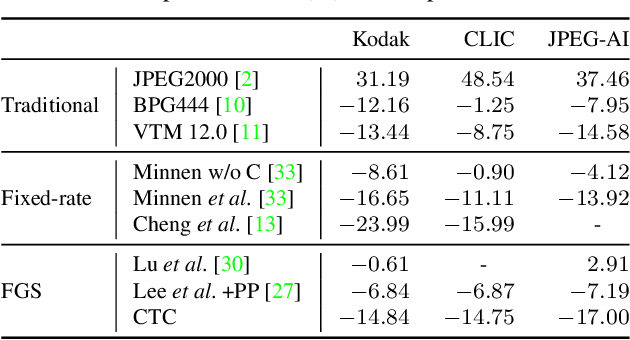
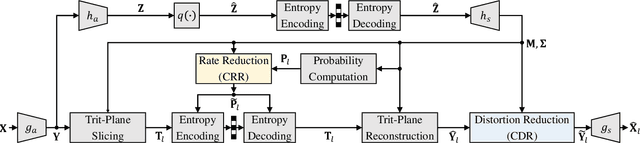
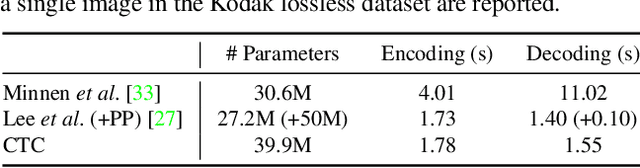
Trit-plane coding enables deep progressive image compression, but it cannot use autoregressive context models. In this paper, we propose the context-based trit-plane coding (CTC) algorithm to achieve progressive compression more compactly. First, we develop the context-based rate reduction module to estimate trit probabilities of latent elements accurately and thus encode the trit-planes compactly. Second, we develop the context-based distortion reduction module to refine partial latent tensors from the trit-planes and improve the reconstructed image quality. Third, we propose a retraining scheme for the decoder to attain better rate-distortion tradeoffs. Extensive experiments show that CTC outperforms the baseline trit-plane codec significantly in BD-rate on the Kodak lossless dataset, while increasing the time complexity only marginally. Our codes are available at https://github.com/seungminjeon-github/CTC.
MultiDiffusion: Fusing Diffusion Paths for Controlled Image Generation
Feb 16, 2023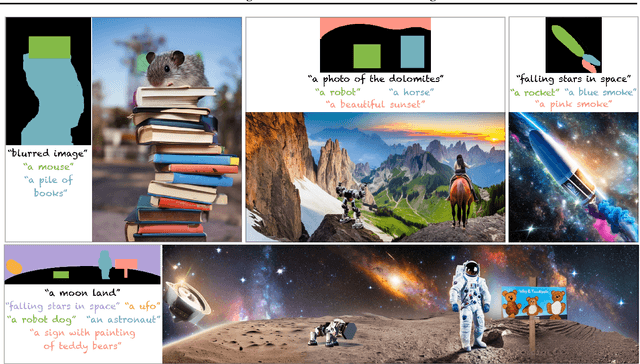
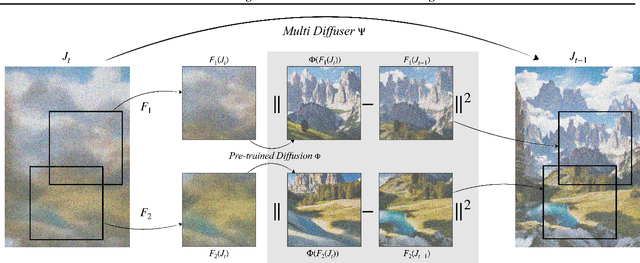


Recent advances in text-to-image generation with diffusion models present transformative capabilities in image quality. However, user controllability of the generated image, and fast adaptation to new tasks still remains an open challenge, currently mostly addressed by costly and long re-training and fine-tuning or ad-hoc adaptations to specific image generation tasks. In this work, we present MultiDiffusion, a unified framework that enables versatile and controllable image generation, using a pre-trained text-to-image diffusion model, without any further training or finetuning. At the center of our approach is a new generation process, based on an optimization task that binds together multiple diffusion generation processes with a shared set of parameters or constraints. We show that MultiDiffusion can be readily applied to generate high quality and diverse images that adhere to user-provided controls, such as desired aspect ratio (e.g., panorama), and spatial guiding signals, ranging from tight segmentation masks to bounding boxes. Project webpage: https://multidiffusion.github.io
Single Image Depth Prediction Made Better: A Multivariate Gaussian Take
Apr 18, 2023
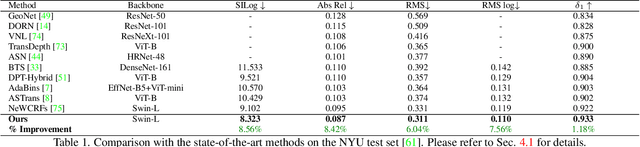
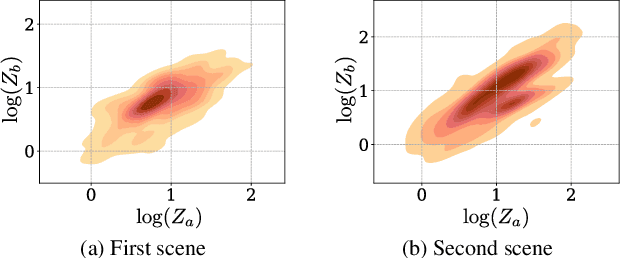
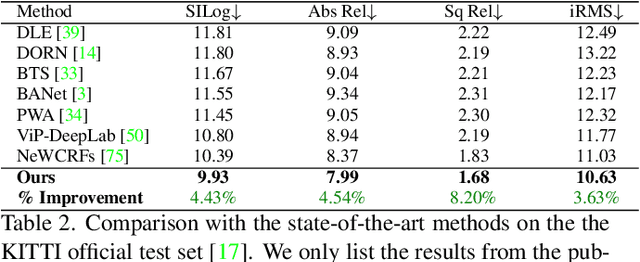
Neural-network-based single image depth prediction (SIDP) is a challenging task where the goal is to predict the scene's per-pixel depth at test time. Since the problem, by definition, is ill-posed, the fundamental goal is to come up with an approach that can reliably model the scene depth from a set of training examples. In the pursuit of perfect depth estimation, most existing state-of-the-art learning techniques predict a single scalar depth value per-pixel. Yet, it is well-known that the trained model has accuracy limits and can predict imprecise depth. Therefore, an SIDP approach must be mindful of the expected depth variations in the model's prediction at test time. Accordingly, we introduce an approach that performs continuous modeling of per-pixel depth, where we can predict and reason about the per-pixel depth and its distribution. To this end, we model per-pixel scene depth using a multivariate Gaussian distribution. Moreover, contrary to the existing uncertainty modeling methods -- in the same spirit, where per-pixel depth is assumed to be independent, we introduce per-pixel covariance modeling that encodes its depth dependency w.r.t all the scene points. Unfortunately, per-pixel depth covariance modeling leads to a computationally expensive continuous loss function, which we solve efficiently using the learned low-rank approximation of the overall covariance matrix. Notably, when tested on benchmark datasets such as KITTI, NYU, and SUN-RGB-D, the SIDP model obtained by optimizing our loss function shows state-of-the-art results. Our method's accuracy (named MG) is among the top on the KITTI depth-prediction benchmark leaderboard.
Locality Preserving Multiview Graph Hashing for Large Scale Remote Sensing Image Search
Apr 10, 2023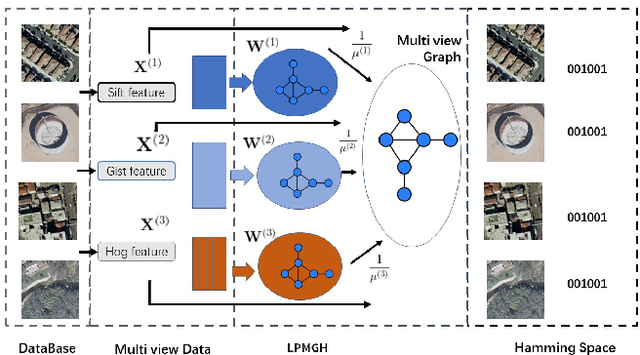

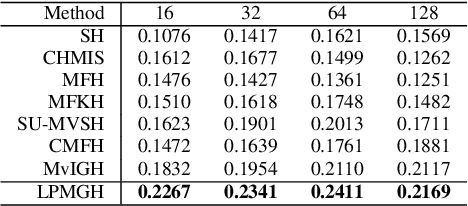
Hashing is very popular for remote sensing image search. This article proposes a multiview hashing with learnable parameters to retrieve the queried images for a large-scale remote sensing dataset. Existing methods always neglect that real-world remote sensing data lies on a low-dimensional manifold embedded in high-dimensional ambient space. Unlike previous methods, this article proposes to learn the consensus compact codes in a view-specific low-dimensional subspace. Furthermore, we have added a hyperparameter learnable module to avoid complex parameter tuning. In order to prove the effectiveness of our method, we carried out experiments on three widely used remote sensing data sets and compared them with seven state-of-the-art methods. Extensive experiments show that the proposed method can achieve competitive results compared to the other method.