 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
SkyGPT: Probabilistic Short-term Solar Forecasting Using Synthetic Sky Videos from Physics-constrained VideoGPT
Jun 20, 2023
In recent years, deep learning-based solar forecasting using all-sky images has emerged as a promising approach for alleviating uncertainty in PV power generation. However, the stochastic nature of cloud movement remains a major challenge for accurate and reliable solar forecasting. With the recent advances in generative artificial intelligence, the synthesis of visually plausible yet diversified sky videos has potential for aiding in forecasts. In this study, we introduce \emph{SkyGPT}, a physics-informed stochastic video prediction model that is able to generate multiple possible future images of the sky with diverse cloud motion patterns, by using past sky image sequences as input. Extensive experiments and comparison with benchmark video prediction models demonstrate the effectiveness of the proposed model in capturing cloud dynamics and generating future sky images with high realism and diversity. Furthermore, we feed the generated future sky images from the video prediction models for 15-minute-ahead probabilistic solar forecasting for a 30-kW roof-top PV system, and compare it with an end-to-end deep learning baseline model SUNSET and a smart persistence model. Better PV output prediction reliability and sharpness is observed by using the predicted sky images generated with SkyGPT compared with other benchmark models, achieving a continuous ranked probability score (CRPS) of 2.81 (13\% better than SUNSET and 23\% better than smart persistence) and a Winkler score of 26.70 for the test set. Although an arbitrary number of futures can be generated from a historical sky image sequence, the results suggest that 10 future scenarios is a good choice that balances probabilistic solar forecasting performance and computational cost.
VisText: A Benchmark for Semantically Rich Chart Captioning
Jun 28, 2023
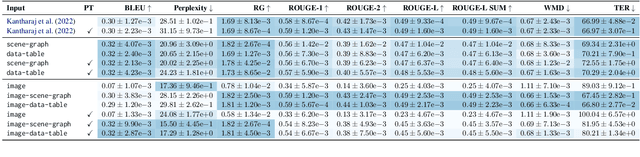
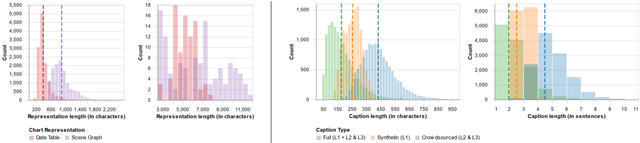
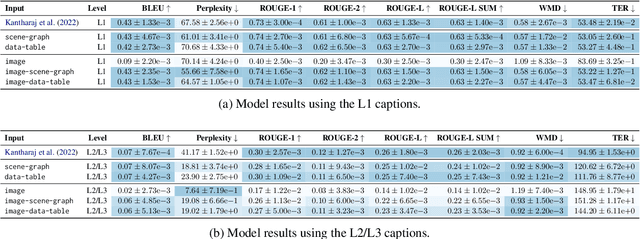
Captions that describe or explain charts help improve recall and comprehension of the depicted data and provide a more accessible medium for people with visual disabilities. However, current approaches for automatically generating such captions struggle to articulate the perceptual or cognitive features that are the hallmark of charts (e.g., complex trends and patterns). In response, we introduce VisText: a dataset of 12,441 pairs of charts and captions that describe the charts' construction, report key statistics, and identify perceptual and cognitive phenomena. In VisText, a chart is available as three representations: a rasterized image, a backing data table, and a scene graph -- a hierarchical representation of a chart's visual elements akin to a web page's Document Object Model (DOM). To evaluate the impact of VisText, we fine-tune state-of-the-art language models on our chart captioning task and apply prefix-tuning to produce captions that vary the semantic content they convey. Our models generate coherent, semantically rich captions and perform on par with state-of-the-art chart captioning models across machine translation and text generation metrics. Through qualitative analysis, we identify six broad categories of errors that our models make that can inform future work.
Theater Aid System for the Visually Impaired Through Transfer Learning of Spatio-Temporal Graph Convolution Networks
Jun 28, 2023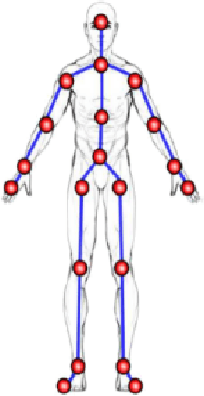
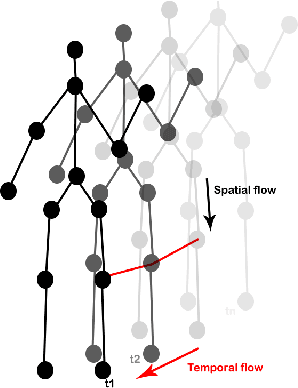

The aim of this research is to recognize human actions performed on stage to aid visually impaired and blind individuals. To achieve this, we have created a theatre human action recognition system that uses skeleton data captured by depth image as input. We collected new samples of human actions in a theatre environment, and then tested the transfer learning technique with three pre-trained Spatio-Temporal Graph Convolution Networks for skeleton-based human action recognition: the spatio-temporal graph convolution network, the two-stream adaptive graph convolution network, and the multi-scale disentangled unified graph convolution network. We selected the NTU-RGBD human action benchmark as the source domain and used our collected dataset as the target domain. We analyzed the transferability of the pre-trained models and proposed two configurations to apply and adapt the transfer learning technique to the diversity between the source and target domains. The use of transfer learning helped to improve the performance of the human action system within the context of theatre. The results indicate that Spatio-Temporal Graph Convolution Networks is positively transferred, and there was an improvement in performance compared to the baseline without transfer learning.
RQAT-INR: Improved Implicit Neural Image Compression
Mar 06, 2023
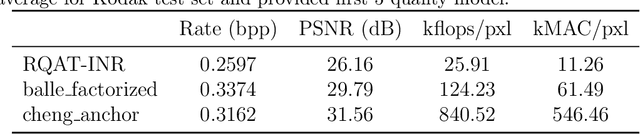
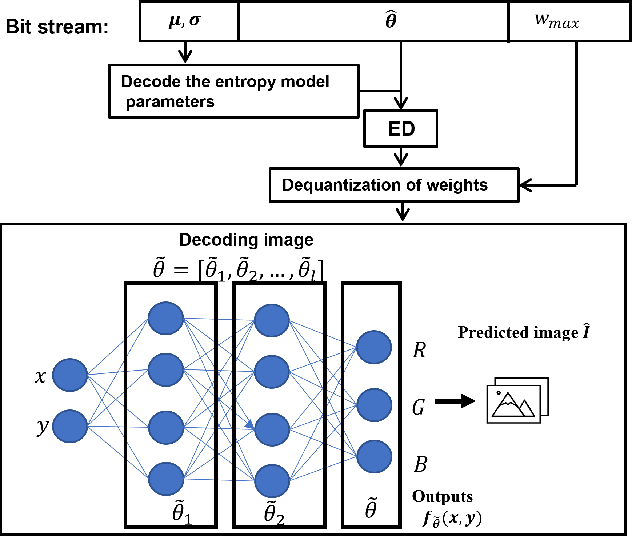
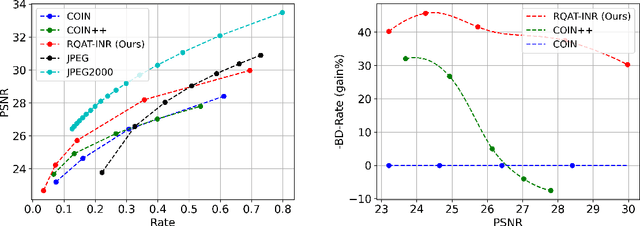
Deep variational autoencoders for image and video compression have gained significant attraction in the recent years, due to their potential to offer competitive or better compression rates compared to the decades long traditional codecs such as AVC, HEVC or VVC. However, because of complexity and energy consumption, these approaches are still far away from practical usage in industry. More recently, implicit neural representation (INR) based codecs have emerged, and have lower complexity and energy usage to classical approaches at decoding. However, their performances are not in par at the moment with state-of-the-art methods. In this research, we first show that INR based image codec has a lower complexity than VAE based approaches, then we propose several improvements for INR-based image codec and outperformed baseline model by a large margin.
Global and Local Semantic Completion Learning for Vision-Language Pre-training
Jun 12, 2023
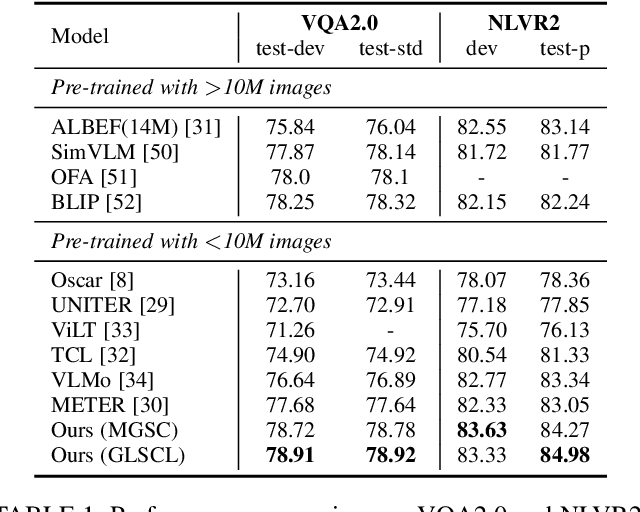
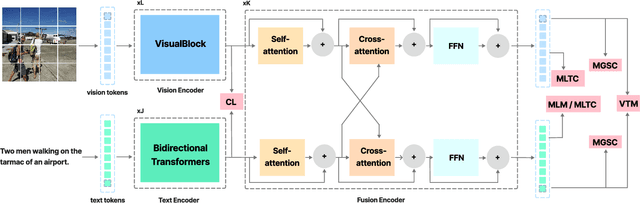
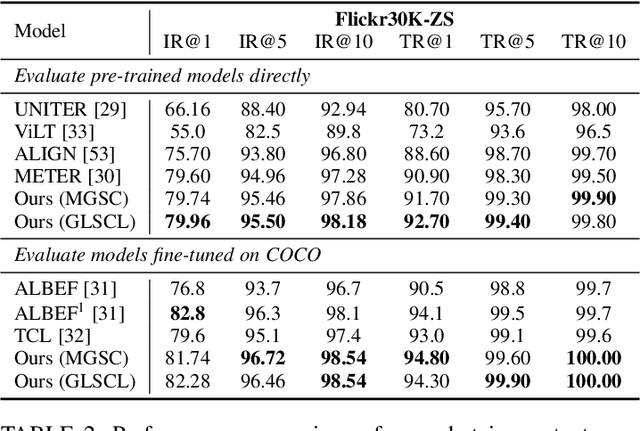
Cross-modal alignment plays a crucial role in vision-language pre-training (VLP) models, enabling them to capture meaningful associations across different modalities. For this purpose, inspired by the success of masked language modeling (MLM) tasks in the NLP pre-training area, numerous masked modeling tasks have been proposed for VLP to further promote cross-modal interactions. The core idea of previous masked modeling tasks is to focus on reconstructing the masked tokens based on visible context for learning local-local alignment, i.e., associations between image patches and text tokens. However, most of them pay little attention to the global semantic features generated for the masked data, resulting in a limited cross-modal alignment ability of global representations to local features of the other modality. Therefore, in this paper, we propose a novel Global and Local Semantic Completion Learning (GLSCL) task to facilitate global-local alignment and local-local alignment simultaneously. Specifically, the GLSCL task complements the missing semantics of masked data and recovers global and local features by cross-modal interactions. Our GLSCL consists of masked global semantic completion (MGSC) and masked local token completion (MLTC). MGSC promotes learning more representative global features which have a great impact on the performance of downstream tasks, and MLTC can further enhance accurate comprehension on multimodal data. Moreover, we present a flexible vision encoder, enabling our model to simultaneously perform image-text and video-text multimodal tasks. Experimental results show that our proposed method obtains state-of-the-art performance on various vision-language benchmarks, such as visual question answering, image-text retrieval, and video-text retrieval.
Ablating Concepts in Text-to-Image Diffusion Models
Mar 23, 2023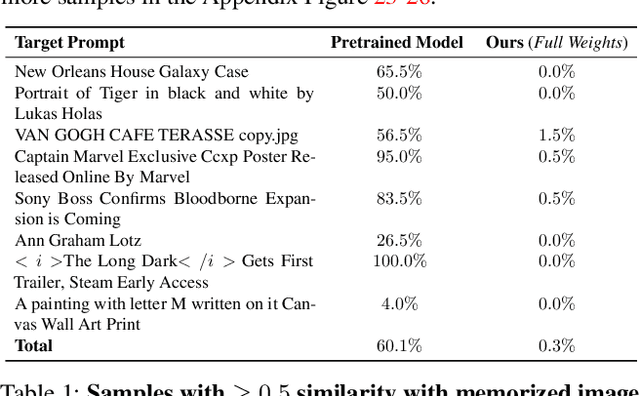
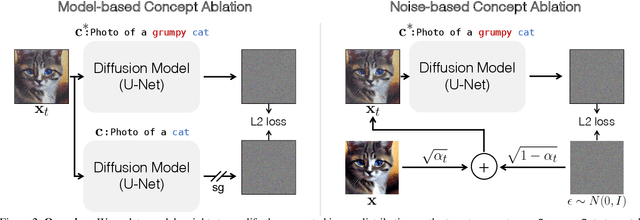

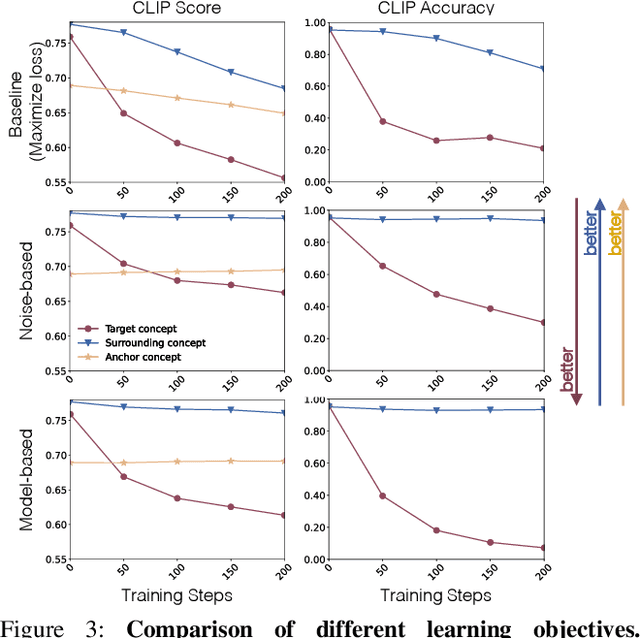
Large-scale text-to-image diffusion models can generate high-fidelity images with powerful compositional ability. However, these models are typically trained on an enormous amount of Internet data, often containing copyrighted material, licensed images, and personal photos. Furthermore, they have been found to replicate the style of various living artists or memorize exact training samples. How can we remove such copyrighted concepts or images without retraining the model from scratch? To achieve this goal, we propose an efficient method of ablating concepts in the pretrained model, i.e., preventing the generation of a target concept. Our algorithm learns to match the image distribution for a target style, instance, or text prompt we wish to ablate to the distribution corresponding to an anchor concept. This prevents the model from generating target concepts given its text condition. Extensive experiments show that our method can successfully prevent the generation of the ablated concept while preserving closely related concepts in the model.
NeuroCLIP: Neuromorphic Data Understanding by CLIP and SNN
Jun 21, 2023
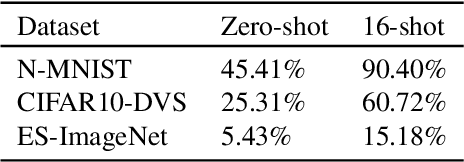
Recently, the neuromorphic vision sensor has received more and more interest. However, the neuromorphic data consists of asynchronous event spikes, which is not natural and difficult to construct a benchmark, thus limiting the neuromorphic data understanding for "unseen" objects by deep learning. Zero-shot and few-shot learning via Contrastive Vision-Language Pre-training (CLIP) have shown inspirational performance in 2D frame image recognition. To handle "unseen" recognition for the neuromorphic data, in this paper, we propose NeuroCLIP, which transfers the CLIP's 2D pre-trained knowledge to event spikes. To improve the few-shot performance, we also provide an inter-timestep adapter based on a spiking neural network. Our code is open-sourced at https://github.com/yfguo91/NeuroCLIP.git.
Instruct-Video2Avatar: Video-to-Avatar Generation with Instructions
Jun 05, 2023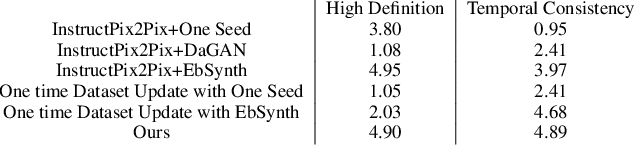
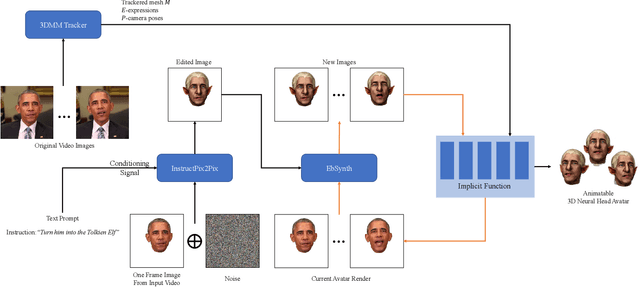


We propose a method for synthesizing edited photo-realistic digital avatars with text instructions. Given a short monocular RGB video and text instructions, our method uses an image-conditioned diffusion model to edit one head image and uses the video stylization method to accomplish the editing of other head images. Through iterative training and update (three times or more), our method synthesizes edited photo-realistic animatable 3D neural head avatars with a deformable neural radiance field head synthesis method. In quantitative and qualitative studies on various subjects, our method outperforms state-of-the-art methods.
StrucTexTv2: Masked Visual-Textual Prediction for Document Image Pre-training
Mar 01, 2023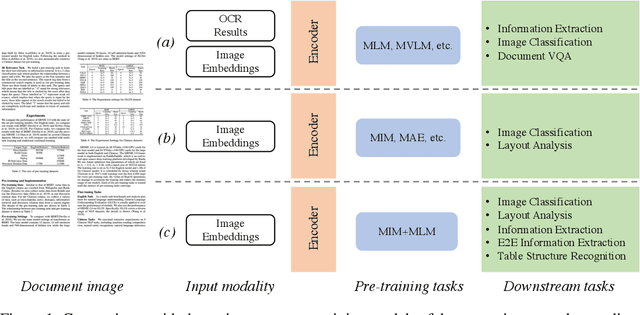
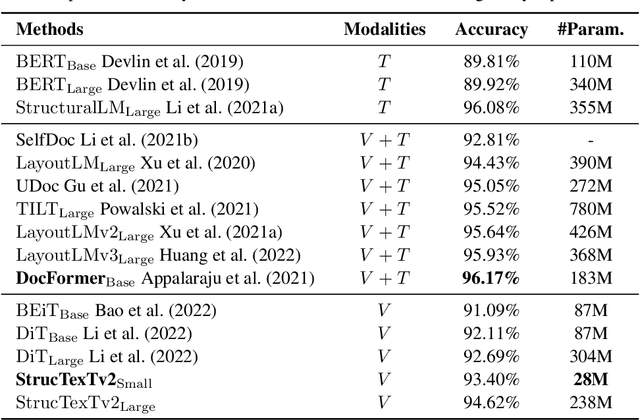


In this paper, we present StrucTexTv2, an effective document image pre-training framework, by performing masked visual-textual prediction. It consists of two self-supervised pre-training tasks: masked image modeling and masked language modeling, based on text region-level image masking. The proposed method randomly masks some image regions according to the bounding box coordinates of text words. The objectives of our pre-training tasks are reconstructing the pixels of masked image regions and the corresponding masked tokens simultaneously. Hence the pre-trained encoder can capture more textual semantics in comparison to the masked image modeling that usually predicts the masked image patches. Compared to the masked multi-modal modeling methods for document image understanding that rely on both the image and text modalities, StrucTexTv2 models image-only input and potentially deals with more application scenarios free from OCR pre-processing. Extensive experiments on mainstream benchmarks of document image understanding demonstrate the effectiveness of StrucTexTv2. It achieves competitive or even new state-of-the-art performance in various downstream tasks such as image classification, layout analysis, table structure recognition, document OCR, and information extraction under the end-to-end scenario.
Highly Personalized Text Embedding for Image Manipulation by Stable Diffusion
Mar 15, 2023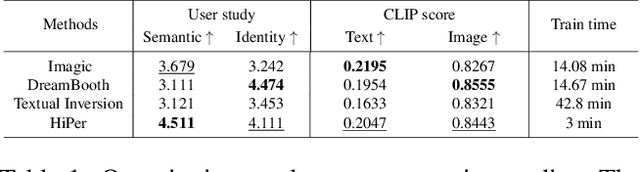

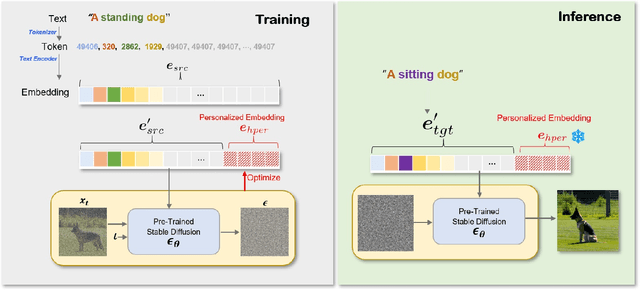

Diffusion models have shown superior performance in image generation and manipulation, but the inherent stochasticity presents challenges in preserving and manipulating image content and identity. While previous approaches like DreamBooth and Textual Inversion have proposed model or latent representation personalization to maintain the content, their reliance on multiple reference images and complex training limits their practicality. In this paper, we present a simple yet highly effective approach to personalization using highly personalized (HiPer) text embedding by decomposing the CLIP embedding space for personalization and content manipulation. Our method does not require model fine-tuning or identifiers, yet still enables manipulation of background, texture, and motion with just a single image and target text. Through experiments on diverse target texts, we demonstrate that our approach produces highly personalized and complex semantic image edits across a wide range of tasks. We believe that the novel understanding of the text embedding space presented in this work has the potential to inspire further research across various tasks.