 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Guidelines for Cerebrovascular Segmentation: Managing Imperfect Annotations in the context of Semi-Supervised Learning
Apr 02, 2024
Segmentation in medical imaging is an essential and often preliminary task in the image processing chain, driving numerous efforts towards the design of robust segmentation algorithms. Supervised learning methods achieve excellent performances when fed with a sufficient amount of labeled data. However, such labels are typically highly time-consuming, error-prone and expensive to produce. Alternatively, semi-supervised learning approaches leverage both labeled and unlabeled data, and are very useful when only a small fraction of the dataset is labeled. They are particularly useful for cerebrovascular segmentation, given that labeling a single volume requires several hours for an expert. In addition to the challenge posed by insufficient annotations, there are concerns regarding annotation consistency. The task of annotating the cerebrovascular tree is inherently ambiguous. Due to the discrete nature of images, the borders and extremities of vessels are often unclear. Consequently, annotations heavily rely on the expert subjectivity and on the underlying clinical objective. These discrepancies significantly increase the complexity of the segmentation task for the model and consequently impair the results. Consequently, it becomes imperative to provide clinicians with precise guidelines to improve the annotation process and construct more uniform datasets. In this article, we investigate the data dependency of deep learning methods within the context of imperfect data and semi-supervised learning, for cerebrovascular segmentation. Specifically, this study compares various state-of-the-art semi-supervised methods based on unsupervised regularization and evaluates their performance in diverse quantity and quality data scenarios. Based on these experiments, we provide guidelines for the annotation and training of cerebrovascular segmentation models.
LayerDiff: Exploring Text-guided Multi-layered Composable Image Synthesis via Layer-Collaborative Diffusion Model
Mar 18, 2024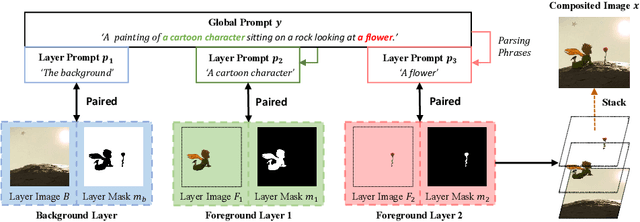
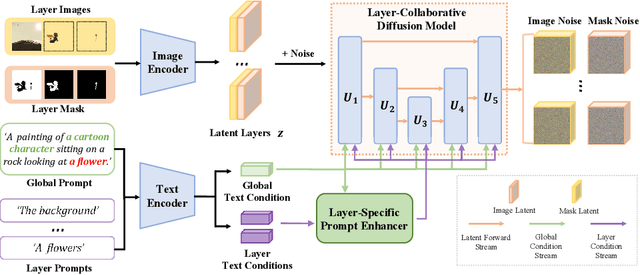

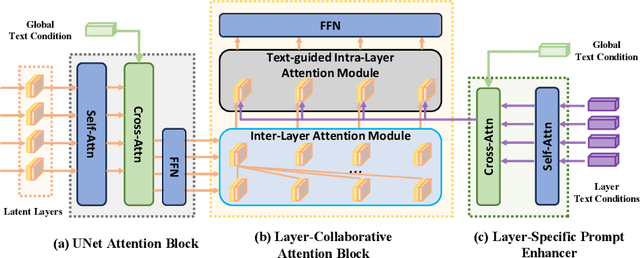
Despite the success of generating high-quality images given any text prompts by diffusion-based generative models, prior works directly generate the entire images, but cannot provide object-wise manipulation capability. To support wider real applications like professional graphic design and digital artistry, images are frequently created and manipulated in multiple layers to offer greater flexibility and control. Therefore in this paper, we propose a layer-collaborative diffusion model, named LayerDiff, specifically designed for text-guided, multi-layered, composable image synthesis. The composable image consists of a background layer, a set of foreground layers, and associated mask layers for each foreground element. To enable this, LayerDiff introduces a layer-based generation paradigm incorporating multiple layer-collaborative attention modules to capture inter-layer patterns. Specifically, an inter-layer attention module is designed to encourage information exchange and learning between layers, while a text-guided intra-layer attention module incorporates layer-specific prompts to direct the specific-content generation for each layer. A layer-specific prompt-enhanced module better captures detailed textual cues from the global prompt. Additionally, a self-mask guidance sampling strategy further unleashes the model's ability to generate multi-layered images. We also present a pipeline that integrates existing perceptual and generative models to produce a large dataset of high-quality, text-prompted, multi-layered images. Extensive experiments demonstrate that our LayerDiff model can generate high-quality multi-layered images with performance comparable to conventional whole-image generation methods. Moreover, LayerDiff enables a broader range of controllable generative applications, including layer-specific image editing and style transfer.
Generative Medical Segmentation
Mar 27, 2024Rapid advancements in medical image segmentation performance have been significantly driven by the development of Convolutional Neural Networks (CNNs) and Vision Transformers (ViTs). However, these models introduce high computational demands and often have limited ability to generalize across diverse medical imaging datasets. In this manuscript, we introduce Generative Medical Segmentation (GMS), a novel approach leveraging a generative model for image segmentation. Concretely, GMS employs a robust pre-trained Variational Autoencoder (VAE) to derive latent representations of both images and masks, followed by a mapping model that learns the transition from image to mask in the latent space. This process culminates in generating a precise segmentation mask within the image space using the pre-trained VAE decoder. The design of GMS leads to fewer learnable parameters in the model, resulting in a reduced computational burden and enhanced generalization capability. Our extensive experimental analysis across five public datasets in different medical imaging domains demonstrates GMS outperforms existing discriminative segmentation models and has remarkable domain generalization. Our experiments suggest GMS could set a new benchmark for medical image segmentation, offering a scalable and effective solution. GMS implementation and model weights are available at https://github.com/King-HAW/GMS.
Toward Interactive Regional Understanding in Vision-Large Language Models
Mar 27, 2024Recent Vision-Language Pre-training (VLP) models have demonstrated significant advancements. Nevertheless, these models heavily rely on image-text pairs that capture only coarse and global information of an image, leading to a limitation in their regional understanding ability. In this work, we introduce \textbf{RegionVLM}, equipped with explicit regional modeling capabilities, allowing them to understand user-indicated image regions. To achieve this, we design a simple yet innovative architecture, requiring no modifications to the model architecture or objective function. Additionally, we leverage a dataset that contains a novel source of information, namely Localized Narratives, which has been overlooked in previous VLP research. Our experiments demonstrate that our single generalist model not only achieves an interactive dialogue system but also exhibits superior performance on various zero-shot region understanding tasks, without compromising its ability for global image understanding.
Model Reprogramming Outperforms Fine-tuning on Out-of-distribution Data in Text-Image Encoders
Mar 29, 2024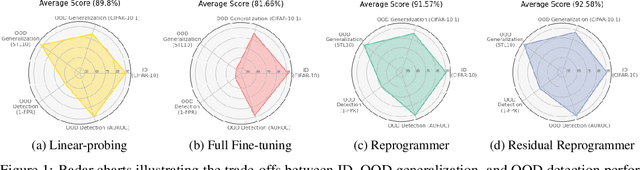
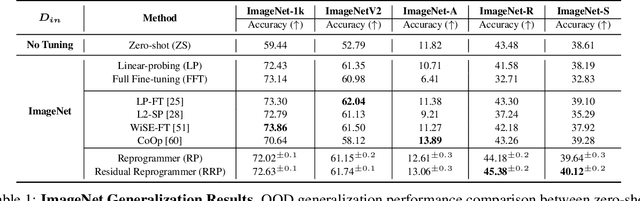
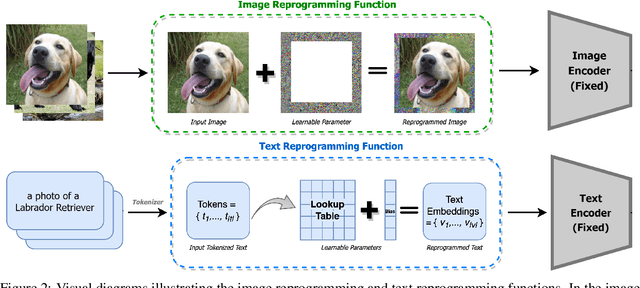
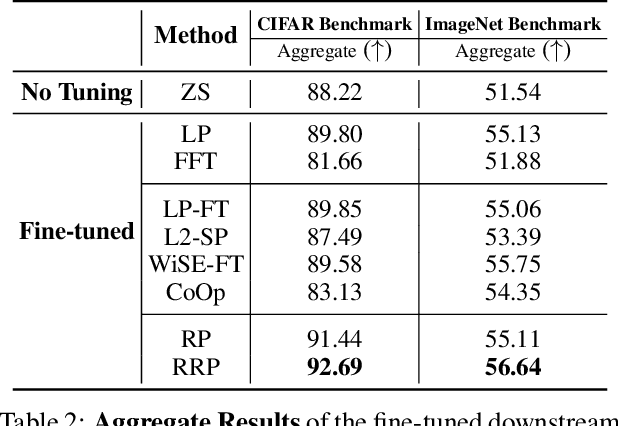
When evaluating the performance of a pre-trained model transferred to a downstream task, it is imperative to assess not only the in-distribution (ID) accuracy of the downstream model but also its capacity to generalize and identify out-of-distribution (OOD) samples. In this paper, we unveil the hidden costs associated with intrusive fine-tuning techniques. Specifically, we demonstrate that commonly used fine-tuning methods not only distort the representations necessary for generalizing to covariate-shifted OOD samples (OOD generalization) but also distort the representations necessary for detecting semantically-shifted OOD samples (OOD detection). To address these challenges, we introduce a new model reprogramming approach for fine-tuning, which we name Reprogrammer. Reprogrammer aims to improve the holistic performance of the downstream model across ID, OOD generalization, and OOD detection tasks. Our empirical evidence reveals that Reprogrammer is less intrusive and yields superior downstream models. Furthermore, we demonstrate that by appending an additional representation residual connection to Reprogrammer, we can further preserve pre-training representations, resulting in an even more safe and robust downstream model capable of excelling in many ID classification, OOD generalization, and OOD detection settings.
SynerMix: Synergistic Mixup Solution for Enhanced Intra-Class Cohesion and Inter-Class Separability in Image Classification
Mar 24, 2024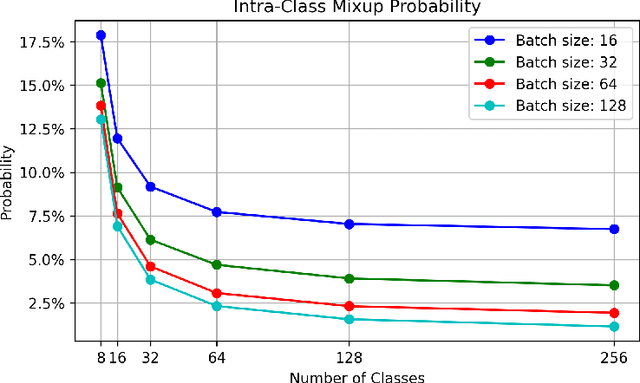

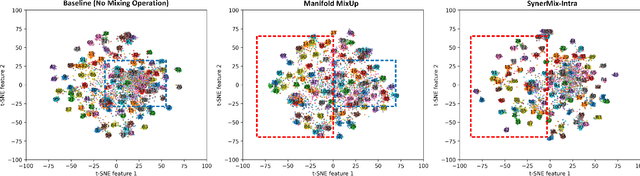
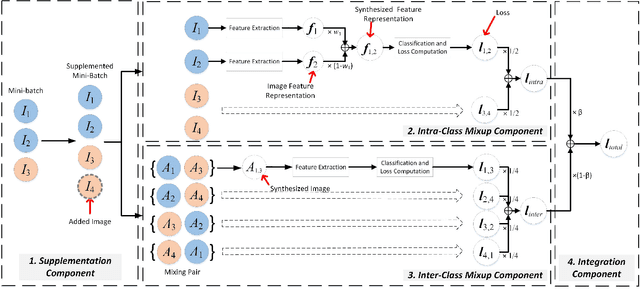
To address the issues of MixUp and its variants (e.g., Manifold MixUp) in image classification tasks-namely, their neglect of mixing within the same class (intra-class mixup) and their inadequacy in enhancing intra-class cohesion through their mixing operations-we propose a novel mixup method named SynerMix-Intra and, building upon this, introduce a synergistic mixup solution named SynerMix. SynerMix-Intra specifically targets intra-class mixup to bolster intra-class cohesion, a feature not addressed by current mixup methods. For each mini-batch, it leverages feature representations of unaugmented original images from each class to generate a synthesized feature representation through random linear interpolation. All synthesized representations are then fed into the classification and loss layers to calculate an average classification loss that significantly enhances intra-class cohesion. Furthermore, SynerMix combines SynerMix-Intra with an existing mixup approach (e.g., MixUp, Manifold MixUp), which primarily focuses on inter-class mixup and has the benefit of enhancing inter-class separability. In doing so, it integrates both inter- and intra-class mixup in a balanced way while concurrently improving intra-class cohesion and inter-class separability. Experimental results on six datasets show that SynerMix achieves a 0.1% to 3.43% higher accuracy than the best of either MixUp or SynerMix-Intra alone, averaging a 1.16% gain. It also surpasses the top-performer of either Manifold MixUp or SynerMix-Intra by 0.12% to 5.16%, with an average gain of 1.11%. Given that SynerMix is model-agnostic, it holds significant potential for application in other domains where mixup methods have shown promise, such as speech and text classification. Our code is publicly available at: https://github.com/wxitxy/synermix.git.
Uncertainty Driven Active Learning for Image Segmentation in Underwater Inspection
Mar 20, 2024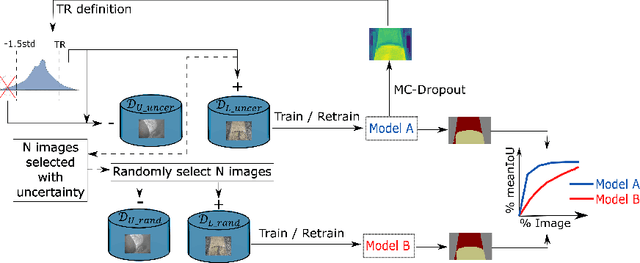
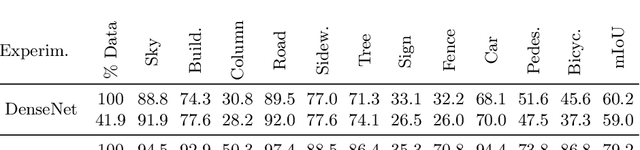


Active learning aims to select the minimum amount of data to train a model that performs similarly to a model trained with the entire dataset. We study the potential of active learning for image segmentation in underwater infrastructure inspection tasks, where large amounts of data are typically collected. The pipeline inspection images are usually semantically repetitive but with great variations in quality. We use mutual information as the acquisition function, calculated using Monte Carlo dropout. To assess the effectiveness of the framework, DenseNet and HyperSeg are trained with the CamVid dataset using active learning. In addition, HyperSeg is trained with a pipeline inspection dataset of over 50,000 images. For the pipeline dataset, HyperSeg with active learning achieved 67.5% meanIoU using 12.5% of the data, and 61.4% with the same amount of randomly selected images. This shows that using active learning for segmentation models in underwater inspection tasks can lower the cost significantly.
Implicit Image-to-Image Schrodinger Bridge for CT Super-Resolution and Denoising
Mar 10, 2024
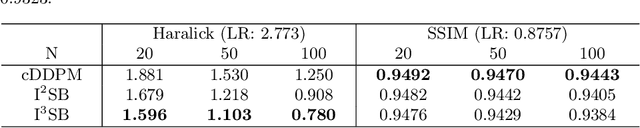
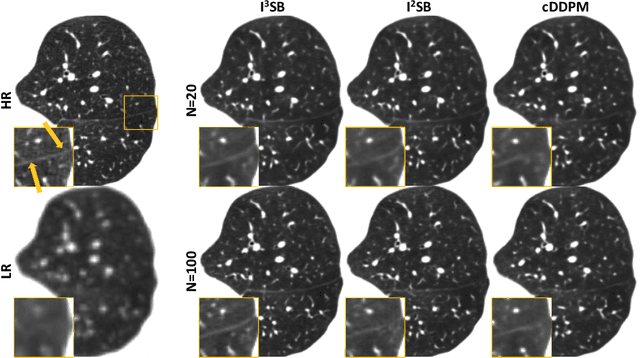

Conditional diffusion models have gained recognition for their effectiveness in image restoration tasks, yet their iterative denoising process, starting from Gaussian noise, often leads to slow inference speeds. As a promising alternative, the Image-to-Image Schr\"odinger Bridge (I2SB) initializes the generative process from corrupted images and integrates training techniques from conditional diffusion models. In this study, we extended the I2SB method by introducing the Implicit Image-to-Image Schrodinger Bridge (I3SB), transitioning its generative process to a non-Markovian process by incorporating corrupted images in each generative step. This enhancement empowers I3SB to generate images with better texture restoration using a small number of generative steps. The proposed method was validated on CT super-resolution and denoising tasks and outperformed existing methods, including the conditional denoising diffusion probabilistic model (cDDPM) and I2SB, in both visual quality and quantitative metrics. These findings underscore the potential of I3SB in improving medical image restoration by providing fast and accurate generative modeling.
Intensity-based 3D motion correction for cardiac MR images
Mar 31, 2024Cardiac magnetic resonance (CMR) image acquisition requires subjects to hold their breath while 2D cine images are acquired. This process assumes that the heart remains in the same position across all slices. However, differences in breathhold positions or patient motion introduce 3D slice misalignments. In this work, we propose an algorithm that simultaneously aligns all SA and LA slices by maximizing the pair-wise intensity agreement between their intersections. Unlike previous works, our approach is formulated as a subject-specific optimization problem and requires no prior knowledge of the underlying anatomy. We quantitatively demonstrate that the proposed method is robust against a large range of rotations and translations by synthetically misaligning 10 motion-free datasets and aligning them back using the proposed method.
A Quantum Fuzzy-based Approach for Real-Time Detection of Solar Coronal Holes
Mar 27, 2024The detection and analysis of the solar coronal holes (CHs) is an important field of study in the domain of solar physics. Mainly, it is required for the proper prediction of the geomagnetic storms which directly or indirectly affect various space and ground-based systems. For the detection of CHs till date, the solar scientist depends on manual hand-drawn approaches. However, with the advancement of image processing technologies, some automated image segmentation methods have been used for the detection of CHs. In-spite of this, fast and accurate detection of CHs are till a major issues. Here in this work, a novel quantum computing-based fast fuzzy c-mean technique has been developed for fast detection of the CHs region. The task has been carried out in two stages, in first stage the solar image has been segmented using a quantum computing based fast fuzzy c-mean (QCFFCM) and in the later stage the CHs has been extracted out from the segmented image based on image morphological operation. In the work, quantum computing has been used to optimize the cost function of the fast fuzzy c-mean (FFCM) algorithm, where quantum approximate optimization algorithm (QAOA) has been used to optimize the quadratic part of the cost function. The proposed method has been tested for 193 \AA{} SDO/AIA full-disk solar image datasets and has been compared with the existing techniques. The outcome shows the comparable performance of the proposed method with the existing one within a very lesser time.