 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
ConceptBed: Evaluating Concept Learning Abilities of Text-to-Image Diffusion Models
Jun 07, 2023
The ability to understand visual concepts and replicate and compose these concepts from images is a central goal for computer vision. Recent advances in text-to-image (T2I) models have lead to high definition and realistic image quality generation by learning from large databases of images and their descriptions. However, the evaluation of T2I models has focused on photorealism and limited qualitative measures of visual understanding. To quantify the ability of T2I models in learning and synthesizing novel visual concepts, we introduce ConceptBed, a large-scale dataset that consists of 284 unique visual concepts, 5K unique concept compositions, and 33K composite text prompts. Along with the dataset, we propose an evaluation metric, Concept Confidence Deviation (CCD), that uses the confidence of oracle concept classifiers to measure the alignment between concepts generated by T2I generators and concepts contained in ground truth images. We evaluate visual concepts that are either objects, attributes, or styles, and also evaluate four dimensions of compositionality: counting, attributes, relations, and actions. Our human study shows that CCD is highly correlated with human understanding of concepts. Our results point to a trade-off between learning the concepts and preserving the compositionality which existing approaches struggle to overcome.
Benchmarking and Analyzing 3D-aware Image Synthesis with a Modularized Codebase
Jun 21, 2023Despite the rapid advance of 3D-aware image synthesis, existing studies usually adopt a mixture of techniques and tricks, leaving it unclear how each part contributes to the final performance in terms of generality. Following the most popular and effective paradigm in this field, which incorporates a neural radiance field (NeRF) into the generator of a generative adversarial network (GAN), we build a well-structured codebase, dubbed Carver, through modularizing the generation process. Such a design allows researchers to develop and replace each module independently, and hence offers an opportunity to fairly compare various approaches and recognize their contributions from the module perspective. The reproduction of a range of cutting-edge algorithms demonstrates the availability of our modularized codebase. We also perform a variety of in-depth analyses, such as the comparison across different types of point feature, the necessity of the tailing upsampler in the generator, the reliance on the camera pose prior, etc., which deepen our understanding of existing methods and point out some further directions of the research work. We release code and models at https://github.com/qiuyu96/Carver to facilitate the development and evaluation of this field.
Layout and Task Aware Instruction Prompt for Zero-shot Document Image Question Answering
Jun 01, 2023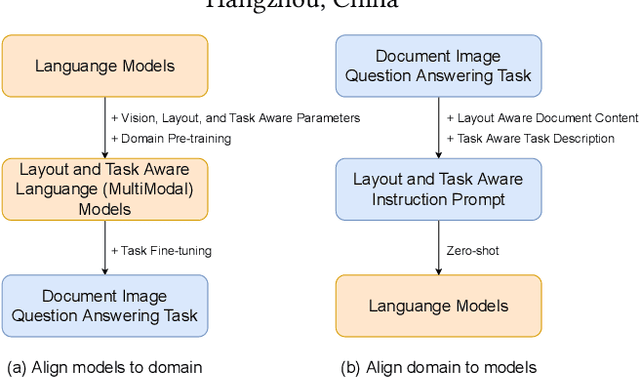

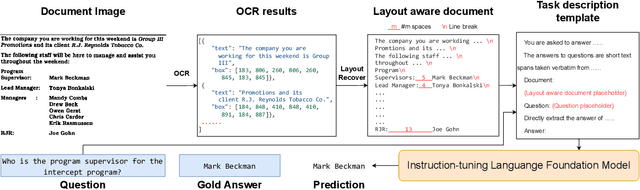

The pre-training-fine-tuning paradigm based on layout-aware multimodal pre-trained models has achieved significant progress on document image question answering. However, domain pre-training and task fine-tuning for additional visual, layout, and task modules prevent them from directly utilizing off-the-shelf instruction-tuning language foundation models, which have recently shown promising potential in zero-shot learning. Contrary to aligning language models to the domain of document image question answering, we align document image question answering to off-the-shell instruction-tuning language foundation models to utilize their zero-shot capability. Specifically, we propose layout and task aware instruction prompt called LATIN-Prompt, which consists of layout-aware document content and task-aware descriptions. The former recovers the layout information among text segments from OCR tools by appropriate spaces and line breaks. The latter ensures that the model generates answers that meet the requirements, especially format requirements, through a detailed description of task. Experimental results on three benchmarks show that LATIN-Prompt can improve the zero-shot performance of instruction-tuning language foundation models on document image question answering and help them achieve comparable levels to SOTAs based on the pre-training-fine-tuning paradigm. Quantitative analysis and qualitative analysis demonstrate the effectiveness of LATIN-Prompt. We provide the code in supplementary and will release the code to facilitate future research.
A Task-guided, Implicitly-searched and Meta-initialized Deep Model for Image Fusion
May 25, 2023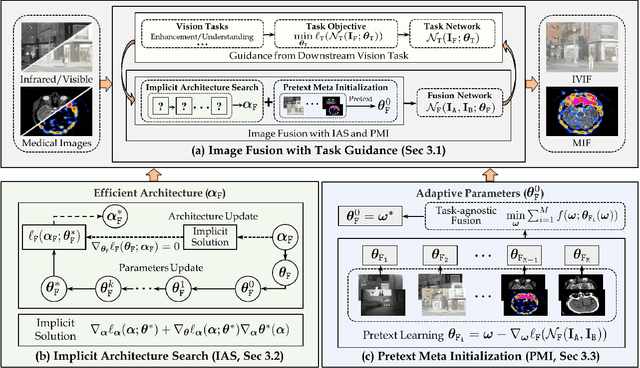



Image fusion plays a key role in a variety of multi-sensor-based vision systems, especially for enhancing visual quality and/or extracting aggregated features for perception. However, most existing methods just consider image fusion as an individual task, thus ignoring its underlying relationship with these downstream vision problems. Furthermore, designing proper fusion architectures often requires huge engineering labor. It also lacks mechanisms to improve the flexibility and generalization ability of current fusion approaches. To mitigate these issues, we establish a Task-guided, Implicit-searched and Meta-initialized (TIM) deep model to address the image fusion problem in a challenging real-world scenario. Specifically, we first propose a constrained strategy to incorporate information from downstream tasks to guide the unsupervised learning process of image fusion. Within this framework, we then design an implicit search scheme to automatically discover compact architectures for our fusion model with high efficiency. In addition, a pretext meta initialization technique is introduced to leverage divergence fusion data to support fast adaptation for different kinds of image fusion tasks. Qualitative and quantitative experimental results on different categories of image fusion problems and related downstream tasks (e.g., visual enhancement and semantic understanding) substantiate the flexibility and effectiveness of our TIM. The source code will be available at https://github.com/LiuZhu-CV/TIMFusion.
Explainable Multi-View Deep Networks Methodology for Experimental Physics
Aug 17, 2023Physical experiments often involve multiple imaging representations, such as X-ray scans and microscopic images. Deep learning models have been widely used for supervised analysis in these experiments. Combining different image representations is frequently required to analyze and make a decision properly. Consequently, multi-view data has emerged - datasets where each sample is described by views from different angles, sources, or modalities. These problems are addressed with the concept of multi-view learning. Understanding the decision-making process of deep learning models is essential for reliable and credible analysis. Hence, many explainability methods have been devised recently. Nonetheless, there is a lack of proper explainability in multi-view models, which are challenging to explain due to their architectures. In this paper, we suggest different multi-view architectures for the vision domain, each suited to another problem, and we also present a methodology for explaining these models. To demonstrate the effectiveness of our methodology, we focus on the domain of High Energy Density Physics (HEDP) experiments, where multiple imaging representations are used to assess the quality of foam samples. We apply our methodology to classify the foam samples quality using the suggested multi-view architectures. Through experimental results, we showcase the improvement of accurate architecture choice on both accuracy - 78% to 84% and AUC - 83% to 93% and present a trade-off between performance and explainability. Specifically, we demonstrate that our approach enables the explanation of individual one-view models, providing insights into the decision-making process of each view. This understanding enhances the interpretability of the overall multi-view model. The sources of this work are available at: https://github.com/Scientific-Computing-Lab-NRCN/Multi-View-Explainability.
Enhancing Detail Preservation for Customized Text-to-Image Generation: A Regularization-Free Approach
May 23, 2023
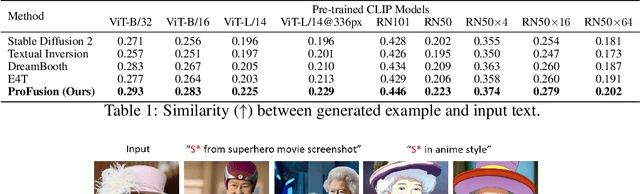
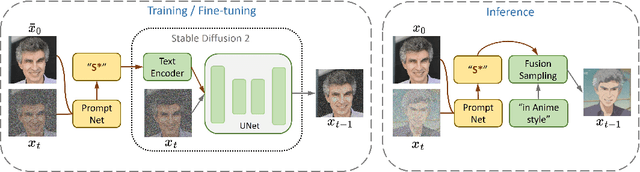
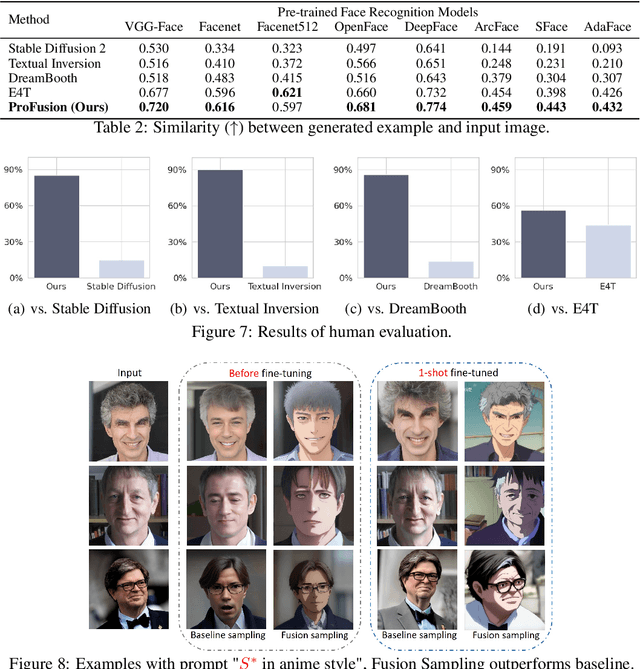
Recent text-to-image generation models have demonstrated impressive capability of generating text-aligned images with high fidelity. However, generating images of novel concept provided by the user input image is still a challenging task. To address this problem, researchers have been exploring various methods for customizing pre-trained text-to-image generation models. Currently, most existing methods for customizing pre-trained text-to-image generation models involve the use of regularization techniques to prevent over-fitting. While regularization will ease the challenge of customization and leads to successful content creation with respect to text guidance, it may restrict the model capability, resulting in the loss of detailed information and inferior performance. In this work, we propose a novel framework for customized text-to-image generation without the use of regularization. Specifically, our proposed framework consists of an encoder network and a novel sampling method which can tackle the over-fitting problem without the use of regularization. With the proposed framework, we are able to customize a large-scale text-to-image generation model within half a minute on single GPU, with only one image provided by the user. We demonstrate in experiments that our proposed framework outperforms existing methods, and preserves more fine-grained details.
iEdit: Localised Text-guided Image Editing with Weak Supervision
May 10, 2023

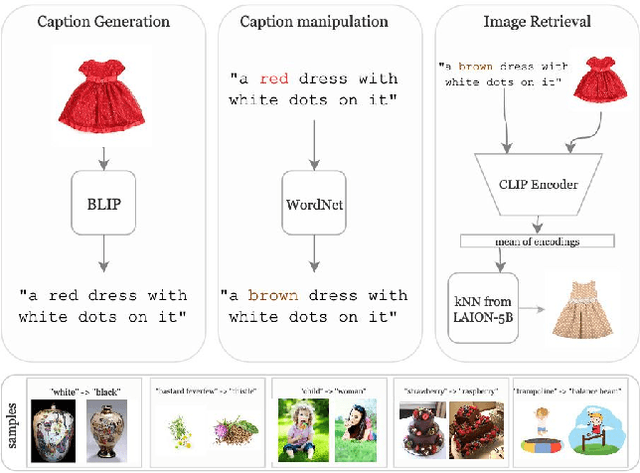

Diffusion models (DMs) can generate realistic images with text guidance using large-scale datasets. However, they demonstrate limited controllability in the output space of the generated images. We propose a novel learning method for text-guided image editing, namely \texttt{iEdit}, that generates images conditioned on a source image and a textual edit prompt. As a fully-annotated dataset with target images does not exist, previous approaches perform subject-specific fine-tuning at test time or adopt contrastive learning without a target image, leading to issues on preserving the fidelity of the source image. We propose to automatically construct a dataset derived from LAION-5B, containing pseudo-target images with their descriptive edit prompts given input image-caption pairs. This dataset gives us the flexibility of introducing a weakly-supervised loss function to generate the pseudo-target image from the latent noise of the source image conditioned on the edit prompt. To encourage localised editing and preserve or modify spatial structures in the image, we propose a loss function that uses segmentation masks to guide the editing during training and optionally at inference. Our model is trained on the constructed dataset with 200K samples and constrained GPU resources. It shows favourable results against its counterparts in terms of image fidelity, CLIP alignment score and qualitatively for editing both generated and real images.
Multiscale Augmented Normalizing Flows for Image Compression
May 09, 2023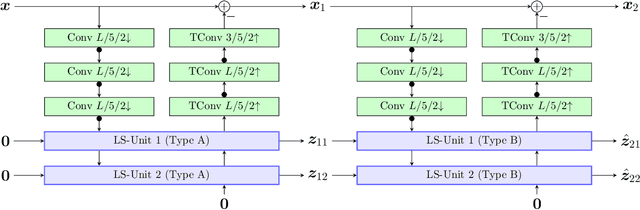
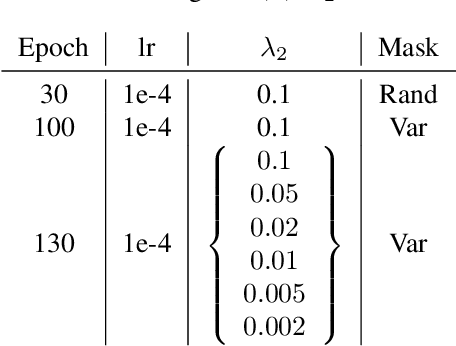
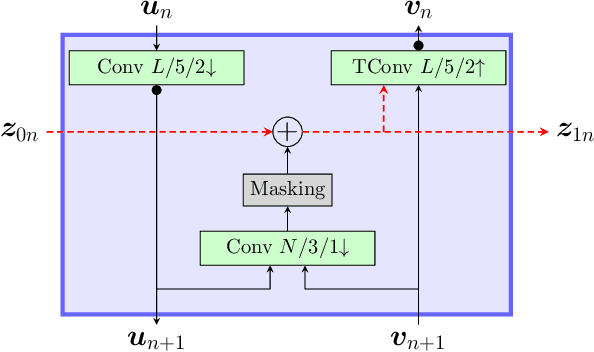
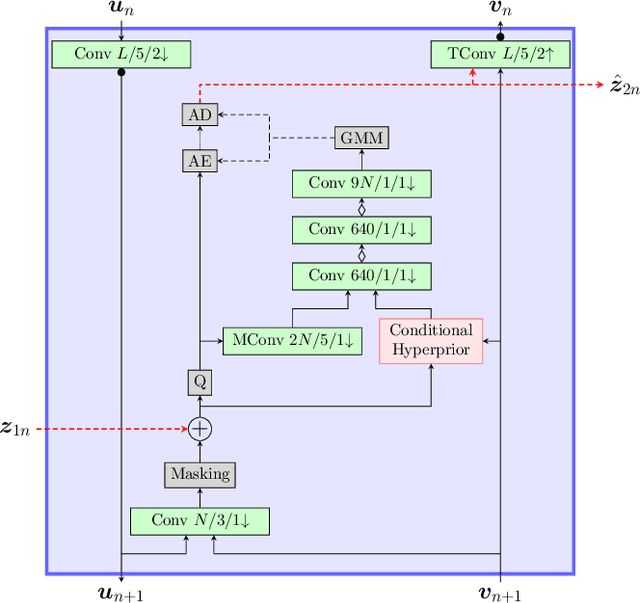
Most learning-based image compression methods lack efficiency for high image quality due to their non-invertible design. The decoding function of the frequently applied compressive autoencoder architecture is only an approximated inverse of the encoding transform. This issue can be resolved by using invertible latent variable models, which allow a perfect reconstruction if no quantization is performed. Furthermore, many traditional image and video coders apply dynamic block partitioning to vary the compression of certain image regions depending on their content. Inspired by this approach, hierarchical latent spaces have been applied to learning-based compression networks. In this paper, we present a novel concept, which adapts the hierarchical latent space for augmented normalizing flows, an invertible latent variable model. Our best performing model achieved average rate savings of more than 7% over comparable single-scale models.
Histogram-guided Video Colorization Structure with Spatial-Temporal Connection
Aug 09, 2023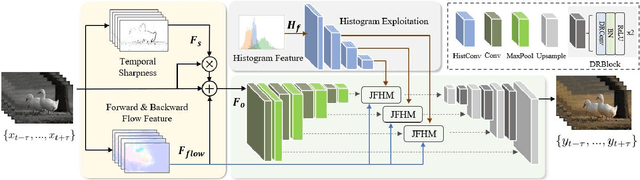
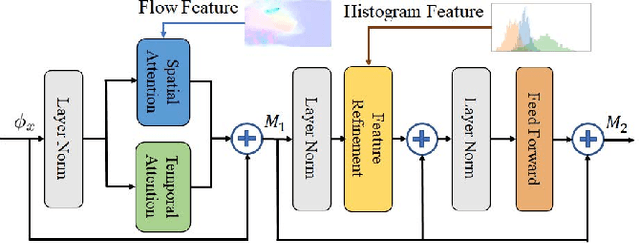

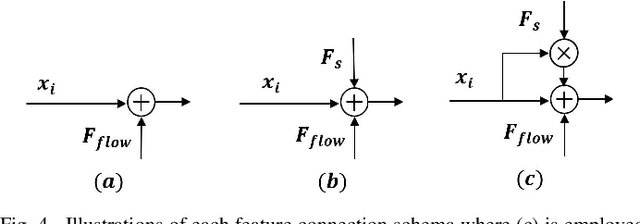
Video colorization, aiming at obtaining colorful and plausible results from grayish frames, has aroused a lot of interest recently. Nevertheless, how to maintain temporal consistency while keeping the quality of colorized results remains challenging. To tackle the above problems, we present a Histogram-guided Video Colorization with Spatial-Temporal connection structure (named ST-HVC). To fully exploit the chroma and motion information, the joint flow and histogram module is tailored to integrate the histogram and flow features. To manage the blurred and artifact, we design a combination scheme attending to temporal detail and flow feature combination. We further recombine the histogram, flow and sharpness features via a U-shape network. Extensive comparisons are conducted with several state-of-the-art image and video-based methods, demonstrating that the developed method achieves excellent performance both quantitatively and qualitatively in two video datasets.
Multi-Scale Memory Comparison for Zero-/Few-Shot Anomaly Detection
Aug 09, 2023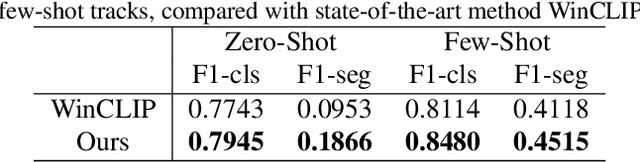
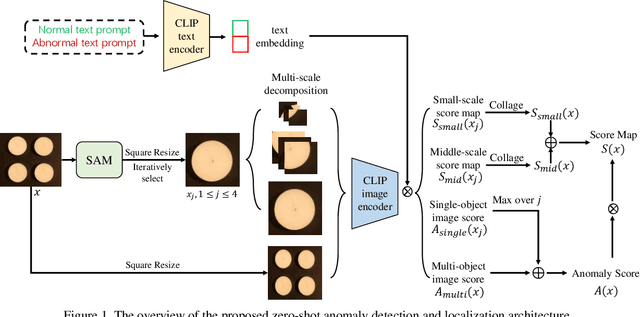
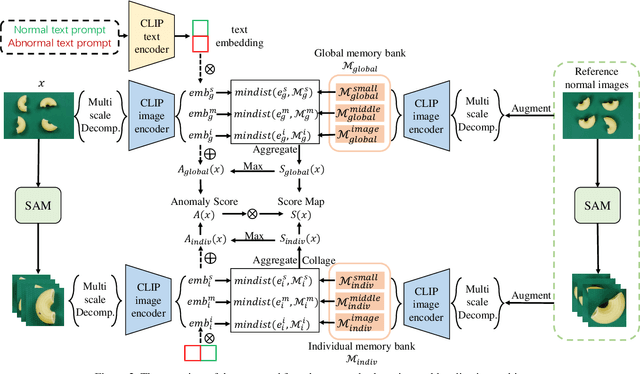

Anomaly detection has gained considerable attention due to its broad range of applications, particularly in industrial defect detection. To address the challenges of data collection, researchers have introduced zero-/few-shot anomaly detection techniques that require minimal normal images for each category. However, complex industrial scenarios often involve multiple objects, presenting a significant challenge. In light of this, we propose a straightforward yet powerful multi-scale memory comparison framework for zero-/few-shot anomaly detection. Our approach employs a global memory bank to capture features across the entire image, while an individual memory bank focuses on simplified scenes containing a single object. The efficacy of our method is validated by its remarkable achievement of 4th place in the zero-shot track and 2nd place in the few-shot track of the Visual Anomaly and Novelty Detection (VAND) competition.