 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInteractive Episodic Memory with User Feedback
Apr 27, 2026In episodic memory with natural language queries (EM-NLQ), a user may ask a question (e.g., "Where did I place the mug?") that requires searching a long egocentric video, captured from the user's perspective, to find the moment that answers it. However, queries can be ambiguous or incomplete, leading to incorrect responses. Current methods ignore this key aspect and address EM-NLQ in a one-shot setup, limiting their applicability in real-world scenarios. In this work, we address this gap and introduce the Episodic Memory with Questions and Feedback task (EM-QnF). Here, the user can provide feedback on the model's initial prediction or add more information (e.g., "Before this. I'm looking for the big blue mug not the white one"), helping the model refine its predictions interactively. To this end, we collect datasets for feedback-based interaction and propose a lightweight training scheme that avoids expensive sequential optimization. We also introduce a plug-and-play Feedback ALignment Module (FALM) that enables existing EM-NLQ models to incorporate user feedback effectively. Our approach significantly improves over the state of the art on three challenging benchmarks and is better than or competitive with commercial large vision-language models while remaining efficient. Evaluation with human-generated feedback shows that it generalizes well to real-world scenarios.
Benchmarking Interaction, Beyond Policy: a Reproducible Benchmark for Collaborative Instance Object Navigation
Mar 31, 2026We propose Question-Asking Navigation (QAsk-Nav), the first reproducible benchmark for Collaborative Instance Object Navigation (CoIN) that enables an explicit, separate assessment of embodied navigation and collaborative question asking. CoIN tasks an embodied agent with reaching a target specified in free-form natural language under partial observability, using only egocentric visual observations and interactive natural-language dialogue with a human, where the dialogue can help to resolve ambiguity among visually similar object instances. Existing CoIN benchmarks are primarily focused on navigation success and offer no support for consistent evaluation of collaborative interaction. To address this limitation, QAsk-Nav provides (i) a lightweight question-asking protocol scored independently of navigation, (ii) an enhanced navigation protocol with realistic, diverse, high-quality target descriptions, and (iii) an open-source dataset, that includes 28,000 quality-checked reasoning and question-asking traces for training and analysis of interactive capabilities of CoIN models. Using the proposed QAsk-Nav benchmark, we develop Light-CoNav, a lightweight unified model for collaborative navigation that is 3x smaller and 70x faster than existing modular methods, while outperforming state-of-the-art CoIN approaches in generalization to unseen objects and environments. Project page at https://benchmarking-interaction.github.io/
Med-MMFL: A Multimodal Federated Learning Benchmark in Healthcare
Feb 04, 2026Federated learning (FL) enables collaborative model training across decentralized medical institutions while preserving data privacy. However, medical FL benchmarks remain scarce, with existing efforts focusing mainly on unimodal or bimodal modalities and a limited range of medical tasks. This gap underscores the need for standardized evaluation to advance systematic understanding in medical MultiModal FL (MMFL). To this end, we introduce Med-MMFL, the first comprehensive MMFL benchmark for the medical domain, encompassing diverse modalities, tasks, and federation scenarios. Our benchmark evaluates six representative state-of-the-art FL algorithms, covering different aggregation strategies, loss formulations, and regularization techniques. It spans datasets with 2 to 4 modalities, comprising a total of 10 unique medical modalities, including text, pathology images, ECG, X-ray, radiology reports, and multiple MRI sequences. Experiments are conducted across naturally federated, synthetic IID, and synthetic non-IID settings to simulate real-world heterogeneity. We assess segmentation, classification, modality alignment (retrieval), and VQA tasks. To support reproducibility and fair comparison of future multimodal federated learning (MMFL) methods under realistic medical settings, we release the complete benchmark implementation, including data processing and partitioning pipelines, at https://github.com/bhattarailab/Med-MMFL-Benchmark .
ToFu: Visual Tokens Reduction via Fusion for Multi-modal, Multi-patch, Multi-image Task
Mar 06, 2025



Large Multimodal Models (LMMs) are powerful tools that are capable of reasoning and understanding multimodal information beyond text and language. Despite their entrenched impact, the development of LMMs is hindered by the higher computational requirements compared to their unimodal counterparts. One of the main causes of this is the large amount of tokens needed to encode the visual input, which is especially evident for multi-image multimodal tasks. Recent approaches to reduce visual tokens depend on the visual encoder architecture, require fine-tuning the LLM to maintain the performance, and only consider single-image scenarios. To address these limitations, we propose ToFu, a visual encoder-agnostic, training-free Token Fusion strategy that combines redundant visual tokens of LMMs for high-resolution, multi-image, tasks. The core intuition behind our method is straightforward yet effective: preserve distinctive tokens while combining similar ones. We achieve this by sequentially examining visual tokens and deciding whether to merge them with others or keep them as separate entities. We validate our approach on the well-established LLaVA-Interleave Bench, which covers challenging multi-image tasks. In addition, we push to the extreme our method by testing it on a newly-created benchmark, ComPairs, focused on multi-image comparisons where a larger amount of images and visual tokens are inputted to the LMMs. Our extensive analysis, considering several LMM architectures, demonstrates the benefits of our approach both in terms of efficiency and performance gain.
UniCoRN: Unified Commented Retrieval Network with LMMs
Feb 12, 2025Multimodal retrieval methods have limitations in handling complex, compositional queries that require reasoning about the visual content of both the query and the retrieved entities. On the other hand, Large Multimodal Models (LMMs) can answer with language to more complex visual questions, but without the inherent ability to retrieve relevant entities to support their answers. We aim to address these limitations with UniCoRN, a Unified Commented Retrieval Network that combines the strengths of composed multimodal retrieval methods and generative language approaches, going beyond Retrieval-Augmented Generation (RAG). We introduce an entity adapter module to inject the retrieved multimodal entities back into the LMM, so it can attend to them while generating answers and comments. By keeping the base LMM frozen, UniCoRN preserves its original capabilities while being able to perform both retrieval and text generation tasks under a single integrated framework. To assess these new abilities, we introduce the Commented Retrieval task (CoR) and a corresponding dataset, with the goal of retrieving an image that accurately answers a given question and generate an additional textual response that provides further clarification and details about the visual information. We demonstrate the effectiveness of UniCoRN on several datasets showing improvements of +4.5% recall over the state of the art for composed multimodal retrieval and of +14.9% METEOR / +18.4% BEM over RAG for commenting in CoR.
Learning Visual Hierarchies with Hyperbolic Embeddings
Nov 26, 2024Structuring latent representations in a hierarchical manner enables models to learn patterns at multiple levels of abstraction. However, most prevalent image understanding models focus on visual similarity, and learning visual hierarchies is relatively unexplored. In this work, for the first time, we introduce a learning paradigm that can encode user-defined multi-level visual hierarchies in hyperbolic space without requiring explicit hierarchical labels. As a concrete example, first, we define a part-based image hierarchy using object-level annotations within and across images. Then, we introduce an approach to enforce the hierarchy using contrastive loss with pairwise entailment metrics. Finally, we discuss new evaluation metrics to effectively measure hierarchical image retrieval. Encoding these complex relationships ensures that the learned representations capture semantic and structural information that transcends mere visual similarity. Experiments in part-based image retrieval show significant improvements in hierarchical retrieval tasks, demonstrating the capability of our model in capturing visual hierarchies.
LatteCLIP: Unsupervised CLIP Fine-Tuning via LMM-Synthetic Texts
Oct 10, 2024



Large-scale vision-language pre-trained (VLP) models (e.g., CLIP) are renowned for their versatility, as they can be applied to diverse applications in a zero-shot setup. However, when these models are used in specific domains, their performance often falls short due to domain gaps or the under-representation of these domains in the training data. While fine-tuning VLP models on custom datasets with human-annotated labels can address this issue, annotating even a small-scale dataset (e.g., 100k samples) can be an expensive endeavor, often requiring expert annotators if the task is complex. To address these challenges, we propose LatteCLIP, an unsupervised method for fine-tuning CLIP models on classification with known class names in custom domains, without relying on human annotations. Our method leverages Large Multimodal Models (LMMs) to generate expressive textual descriptions for both individual images and groups of images. These provide additional contextual information to guide the fine-tuning process in the custom domains. Since LMM-generated descriptions are prone to hallucination or missing details, we introduce a novel strategy to distill only the useful information and stabilize the training. Specifically, we learn rich per-class prototype representations from noisy generated texts and dual pseudo-labels. Our experiments on 10 domain-specific datasets show that LatteCLIP outperforms pre-trained zero-shot methods by an average improvement of +4.74 points in top-1 accuracy and other state-of-the-art unsupervised methods by +3.45 points.
ViewFusion: Towards Multi-View Consistency via Interpolated Denoising
Feb 29, 2024



Novel-view synthesis through diffusion models has demonstrated remarkable potential for generating diverse and high-quality images. Yet, the independent process of image generation in these prevailing methods leads to challenges in maintaining multiple-view consistency. To address this, we introduce ViewFusion, a novel, training-free algorithm that can be seamlessly integrated into existing pre-trained diffusion models. Our approach adopts an auto-regressive method that implicitly leverages previously generated views as context for the next view generation, ensuring robust multi-view consistency during the novel-view generation process. Through a diffusion process that fuses known-view information via interpolated denoising, our framework successfully extends single-view conditioned models to work in multiple-view conditional settings without any additional fine-tuning. Extensive experimental results demonstrate the effectiveness of ViewFusion in generating consistent and detailed novel views.
iEdit: Localised Text-guided Image Editing with Weak Supervision
May 10, 2023Diffusion models (DMs) can generate realistic images with text guidance using large-scale datasets. However, they demonstrate limited controllability in the output space of the generated images. We propose a novel learning method for text-guided image editing, namely \texttt{iEdit}, that generates images conditioned on a source image and a textual edit prompt. As a fully-annotated dataset with target images does not exist, previous approaches perform subject-specific fine-tuning at test time or adopt contrastive learning without a target image, leading to issues on preserving the fidelity of the source image. We propose to automatically construct a dataset derived from LAION-5B, containing pseudo-target images with their descriptive edit prompts given input image-caption pairs. This dataset gives us the flexibility of introducing a weakly-supervised loss function to generate the pseudo-target image from the latent noise of the source image conditioned on the edit prompt. To encourage localised editing and preserve or modify spatial structures in the image, we propose a loss function that uses segmentation masks to guide the editing during training and optionally at inference. Our model is trained on the constructed dataset with 200K samples and constrained GPU resources. It shows favourable results against its counterparts in terms of image fidelity, CLIP alignment score and qualitatively for editing both generated and real images.
Contrastive Language-Action Pre-training for Temporal Localization
Apr 26, 2022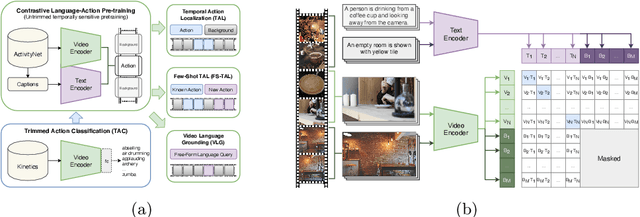
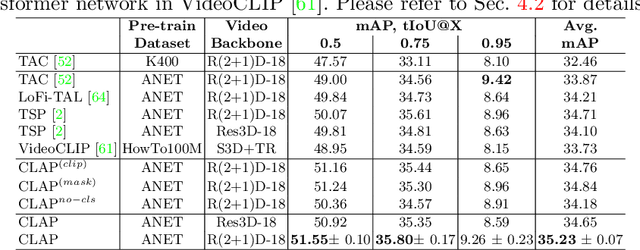
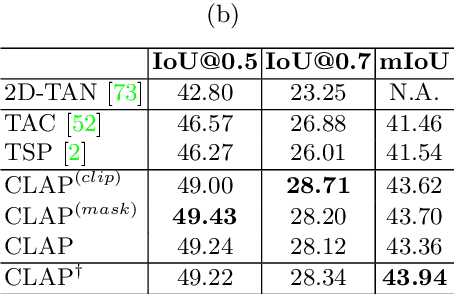
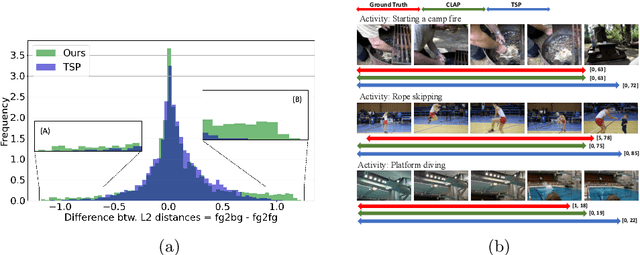
Long-form video understanding requires designing approaches that are able to temporally localize activities or language. End-to-end training for such tasks is limited by the compute device memory constraints and lack of temporal annotations at large-scale. These limitations can be addressed by pre-training on large datasets of temporally trimmed videos supervised by class annotations. Once the video encoder is pre-trained, it is common practice to freeze it during fine-tuning. Therefore, the video encoder does not learn temporal boundaries and unseen classes, causing a domain gap with respect to the downstream tasks. Moreover, using temporally trimmed videos prevents to capture the relations between different action categories and the background context in a video clip which results in limited generalization capacity. To address these limitations, we propose a novel post-pre-training approach without freezing the video encoder which leverages language. We introduce a masked contrastive learning loss to capture visio-linguistic relations between activities, background video clips and language in the form of captions. Our experiments show that the proposed approach improves the state-of-the-art on temporal action localization, few-shot temporal action localization, and video language grounding tasks.