 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
SalFoM: Dynamic Saliency Prediction with Video Foundation Models
Apr 03, 2024
Recent advancements in video saliency prediction (VSP) have shown promising performance compared to the human visual system, whose emulation is the primary goal of VSP. However, current state-of-the-art models employ spatio-temporal transformers trained on limited amounts of data, hindering generalizability adaptation to downstream tasks. The benefits of vision foundation models present a potential solution to improve the VSP process. However, adapting image foundation models to the video domain presents significant challenges in modeling scene dynamics and capturing temporal information. To address these challenges, and as the first initiative to design a VSP model based on video foundation models, we introduce SalFoM, a novel encoder-decoder video transformer architecture. Our model employs UnMasked Teacher (UMT) as feature extractor and presents a heterogeneous decoder which features a locality-aware spatio-temporal transformer and integrates local and global spatio-temporal information from various perspectives to produce the final saliency map. Our qualitative and quantitative experiments on the challenging VSP benchmark datasets of DHF1K, Hollywood-2 and UCF-Sports demonstrate the superiority of our proposed model in comparison with the state-of-the-art methods.
Latent Neural Cellular Automata for Resource-Efficient Image Restoration
Mar 22, 2024Neural cellular automata represent an evolution of the traditional cellular automata model, enhanced by the integration of a deep learning-based transition function. This shift from a manual to a data-driven approach significantly increases the adaptability of these models, enabling their application in diverse domains, including content generation and artificial life. However, their widespread application has been hampered by significant computational requirements. In this work, we introduce the Latent Neural Cellular Automata (LNCA) model, a novel architecture designed to address the resource limitations of neural cellular automata. Our approach shifts the computation from the conventional input space to a specially designed latent space, relying on a pre-trained autoencoder. We apply our model in the context of image restoration, which aims to reconstruct high-quality images from their degraded versions. This modification not only reduces the model's resource consumption but also maintains a flexible framework suitable for various applications. Our model achieves a significant reduction in computational requirements while maintaining high reconstruction fidelity. This increase in efficiency allows for inputs up to 16 times larger than current state-of-the-art neural cellular automata models, using the same resources.
VideoDistill: Language-aware Vision Distillation for Video Question Answering
Apr 01, 2024Significant advancements in video question answering (VideoQA) have been made thanks to thriving large image-language pretraining frameworks. Although these image-language models can efficiently represent both video and language branches, they typically employ a goal-free vision perception process and do not interact vision with language well during the answer generation, thus omitting crucial visual cues. In this paper, we are inspired by the human recognition and learning pattern and propose VideoDistill, a framework with language-aware (i.e., goal-driven) behavior in both vision perception and answer generation process. VideoDistill generates answers only from question-related visual embeddings and follows a thinking-observing-answering approach that closely resembles human behavior, distinguishing it from previous research. Specifically, we develop a language-aware gating mechanism to replace the standard cross-attention, avoiding language's direct fusion into visual representations. We incorporate this mechanism into two key components of the entire framework. The first component is a differentiable sparse sampling module, which selects frames containing the necessary dynamics and semantics relevant to the questions. The second component is a vision refinement module that merges existing spatial-temporal attention layers to ensure the extraction of multi-grained visual semantics associated with the questions. We conduct experimental evaluations on various challenging video question-answering benchmarks, and VideoDistill achieves state-of-the-art performance in both general and long-form VideoQA datasets. In Addition, we verify that VideoDistill can effectively alleviate the utilization of language shortcut solutions in the EgoTaskQA dataset.
FE-DeTr: Keypoint Detection and Tracking in Low-quality Image Frames with Events
Mar 18, 2024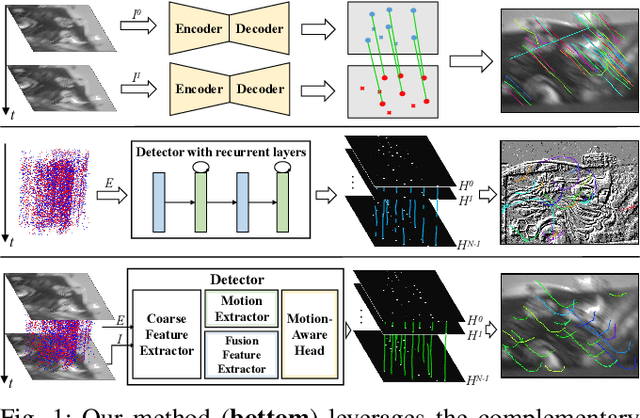
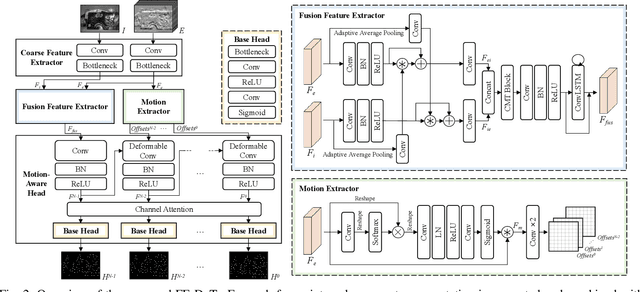
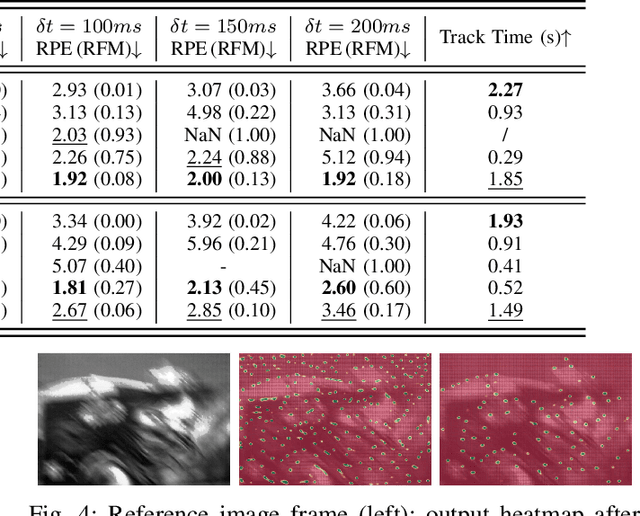
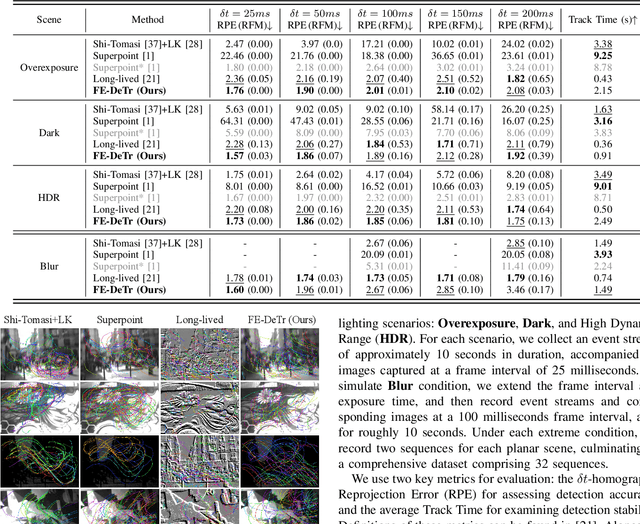
Keypoint detection and tracking in traditional image frames are often compromised by image quality issues such as motion blur and extreme lighting conditions. Event cameras offer potential solutions to these challenges by virtue of their high temporal resolution and high dynamic range. However, they have limited performance in practical applications due to their inherent noise in event data. This paper advocates fusing the complementary information from image frames and event streams to achieve more robust keypoint detection and tracking. Specifically, we propose a novel keypoint detection network that fuses the textural and structural information from image frames with the high-temporal-resolution motion information from event streams, namely FE-DeTr. The network leverages a temporal response consistency for supervision, ensuring stable and efficient keypoint detection. Moreover, we use a spatio-temporal nearest-neighbor search strategy for robust keypoint tracking. Extensive experiments are conducted on a new dataset featuring both image frames and event data captured under extreme conditions. The experimental results confirm the superior performance of our method over both existing frame-based and event-based methods.
3DStyleGLIP: Part-Tailored Text-Guided 3D Neural Stylization
Apr 03, 20243D stylization, which entails the application of specific styles to three-dimensional objects, holds significant commercial potential as it enables the creation of diverse 3D objects with distinct moods and styles, tailored to specific demands of different scenes. With recent advancements in text-driven methods and artificial intelligence, the stylization process is increasingly intuitive and automated, thereby diminishing the reliance on manual labor and expertise. However, existing methods have predominantly focused on holistic stylization, thereby leaving the application of styles to individual components of a 3D object unexplored. In response, we introduce 3DStyleGLIP, a novel framework specifically designed for text-driven, part-tailored 3D stylization. Given a 3D mesh and a text prompt, 3DStyleGLIP leverages the vision-language embedding space of the Grounded Language-Image Pre-training (GLIP) model to localize the individual parts of the 3D mesh and modify their colors and local geometries to align them with the desired styles specified in the text prompt. 3DStyleGLIP is effectively trained for 3D stylization tasks through a part-level style loss working in GLIP's embedding space, supplemented by two complementary learning techniques. Extensive experimental validation confirms that our method achieves significant part-wise stylization capabilities, demonstrating promising potential in advancing the field of 3D stylization.
Neural Radiance Fields with Torch Units
Apr 03, 2024Neural Radiance Fields (NeRF) give rise to learning-based 3D reconstruction methods widely used in industrial applications. Although prevalent methods achieve considerable improvements in small-scale scenes, accomplishing reconstruction in complex and large-scale scenes is still challenging. First, the background in complex scenes shows a large variance among different views. Second, the current inference pattern, $i.e.$, a pixel only relies on an individual camera ray, fails to capture contextual information. To solve these problems, we propose to enlarge the ray perception field and build up the sample points interactions. In this paper, we design a novel inference pattern that encourages a single camera ray possessing more contextual information, and models the relationship among sample points on each camera ray. To hold contextual information,a camera ray in our proposed method can render a patch of pixels simultaneously. Moreover, we replace the MLP in neural radiance field models with distance-aware convolutions to enhance the feature propagation among sample points from the same camera ray. To summarize, as a torchlight, a ray in our proposed method achieves rendering a patch of image. Thus, we call the proposed method, Torch-NeRF. Extensive experiments on KITTI-360 and LLFF show that the Torch-NeRF exhibits excellent performance.
Data-Efficient Contrastive Language-Image Pretraining: Prioritizing Data Quality over Quantity
Mar 20, 2024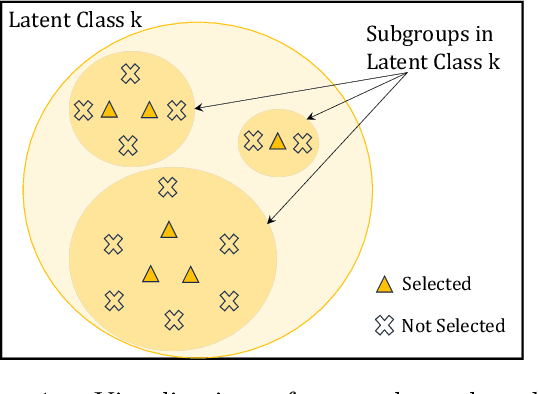
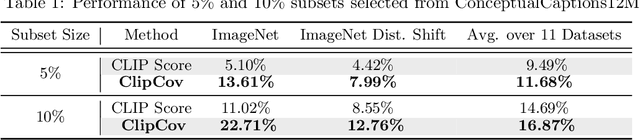
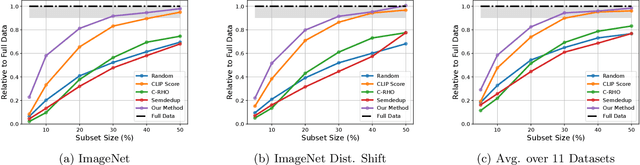
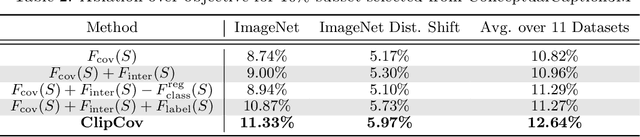
Contrastive Language-Image Pre-training (CLIP) on large-scale image-caption datasets learns representations that can achieve remarkable zero-shot generalization. However, such models require a massive amount of pre-training data. Improving the quality of the pre-training data has been shown to be much more effective in improving CLIP's performance than increasing its volume. Nevertheless, finding small subsets of training data that provably generalize the best has remained an open question. In this work, we propose the first theoretically rigorous data selection method for CLIP. We show that subsets that closely preserve the cross-covariance of the images and captions of the full data provably achieve a superior generalization performance. Our extensive experiments on ConceptualCaptions3M and ConceptualCaptions12M demonstrate that subsets found by \method\ achieve over 2.7x and 1.4x the accuracy of the next best baseline on ImageNet and its shifted versions. Moreover, we show that our subsets obtain 1.5x the average accuracy across 11 downstream datasets, of the next best baseline. The code is available at: https://github.com/BigML-CS-UCLA/clipcov-data-efficient-clip.
mChartQA: A universal benchmark for multimodal Chart Question Answer based on Vision-Language Alignment and Reasoning
Apr 02, 2024In the fields of computer vision and natural language processing, multimodal chart question-answering, especially involving color, structure, and textless charts, poses significant challenges. Traditional methods, which typically involve either direct multimodal processing or a table-to-text conversion followed by language model analysis, have limitations in effectively handling these complex scenarios. This paper introduces a novel multimodal chart question-answering model, specifically designed to address these intricate tasks. Our model integrates visual and linguistic processing, overcoming the constraints of existing methods. We adopt a dual-phase training approach: the initial phase focuses on aligning image and text representations, while the subsequent phase concentrates on optimizing the model's interpretative and analytical abilities in chart-related queries. This approach has demonstrated superior performance on multiple public datasets, particularly in handling color, structure, and textless chart questions, indicating its effectiveness in complex multimodal tasks.
Low-Trace Adaptation of Zero-shot Self-supervised Blind Image Denoising
Mar 19, 2024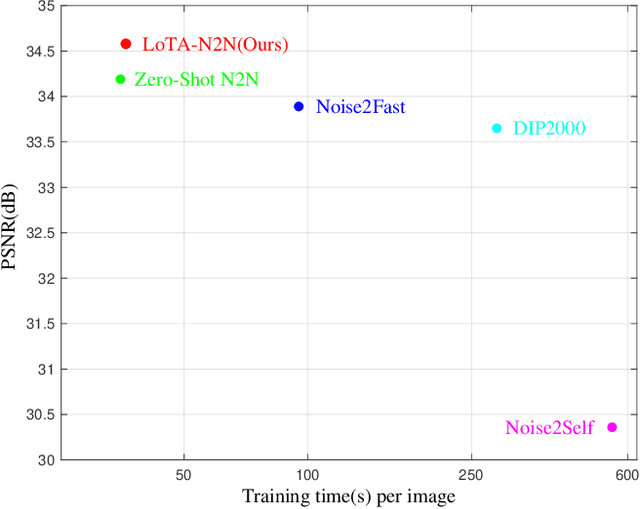
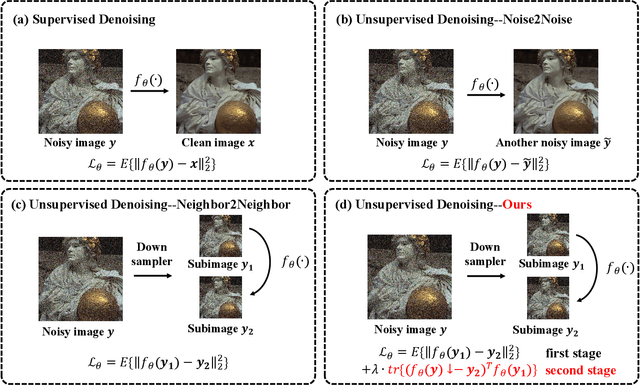
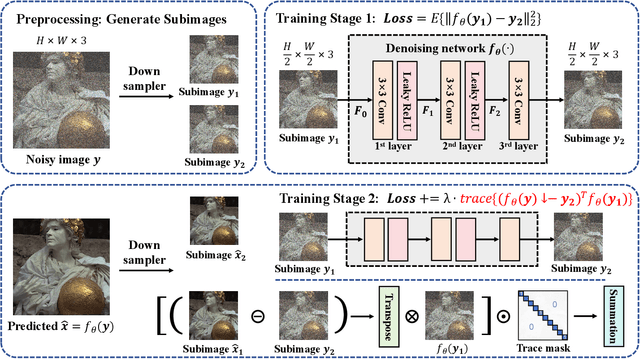

Deep learning-based denoiser has been the focus of recent development on image denoising. In the past few years, there has been increasing interest in developing self-supervised denoising networks that only require noisy images, without the need for clean ground truth for training. However, a performance gap remains between current self-supervised methods and their supervised counterparts. Additionally, these methods commonly depend on assumptions about noise characteristics, thereby constraining their applicability in real-world scenarios. Inspired by the properties of the Frobenius norm expansion, we discover that incorporating a trace term reduces the optimization goal disparity between self-supervised and supervised methods, thereby enhancing the performance of self-supervised learning. To exploit this insight, we propose a trace-constraint loss function and design the low-trace adaptation Noise2Noise (LoTA-N2N) model that bridges the gap between self-supervised and supervised learning. Furthermore, we have discovered that several existing self-supervised denoising frameworks naturally fall within the proposed trace-constraint loss as subcases. Extensive experiments conducted on natural and confocal image datasets indicate that our method achieves state-of-the-art performance within the realm of zero-shot self-supervised image denoising approaches, without relying on any assumptions regarding the noise.
VLM-CPL: Consensus Pseudo Labels from Vision-Language Models for Human Annotation-Free Pathological Image Classification
Mar 23, 2024Despite that deep learning methods have achieved remarkable performance in pathology image classification, they heavily rely on labeled data, demanding extensive human annotation efforts. In this study, we present a novel human annotation-free method for pathology image classification by leveraging pre-trained Vision-Language Models (VLMs). Without human annotation, pseudo labels of the training set are obtained by utilizing the zero-shot inference capabilities of VLM, which may contain a lot of noise due to the domain shift between the pre-training data and the target dataset. To address this issue, we introduce VLM-CPL, a novel approach based on consensus pseudo labels that integrates two noisy label filtering techniques with a semi-supervised learning strategy. Specifically, we first obtain prompt-based pseudo labels with uncertainty estimation by zero-shot inference with the VLM using multiple augmented views of an input. Then, by leveraging the feature representation ability of VLM, we obtain feature-based pseudo labels via sample clustering in the feature space. Prompt-feature consensus is introduced to select reliable samples based on the consensus between the two types of pseudo labels. By rejecting low-quality pseudo labels, we further propose High-confidence Cross Supervision (HCS) to learn from samples with reliable pseudo labels and the remaining unlabeled samples. Experimental results showed that our method obtained an accuracy of 87.1% and 95.1% on the HPH and LC25K datasets, respectively, and it largely outperformed existing zero-shot classification and noisy label learning methods. The code is available at https://github.com/lanfz2000/VLM-CPL.