 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image To Image Translation": models, code, and papers
GMM-UNIT: Unsupervised Multi-Domain and Multi-Modal Image-to-Image Translation via Attribute Gaussian Mixture Modeling
Mar 15, 2020


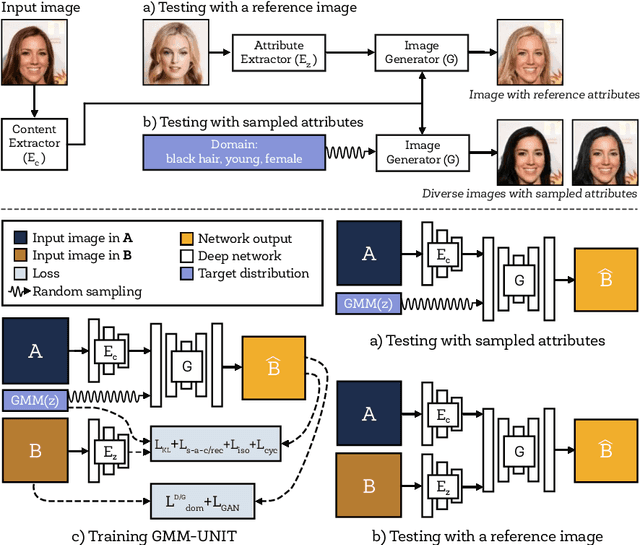

Unsupervised image-to-image translation (UNIT) aims at learning a mapping between several visual domains by using unpaired training images. Recent studies have shown remarkable success for multiple domains but they suffer from two main limitations: they are either built from several two-domain mappings that are required to be learned independently, or they generate low-diversity results, a problem known as model collapse. To overcome these limitations, we propose a method named GMM-UNIT, which is based on a content-attribute disentangled representation where the attribute space is fitted with a GMM. Each GMM component represents a domain, and this simple assumption has two prominent advantages. First, it can be easily extended to most multi-domain and multi-modal image-to-image translation tasks. Second, the continuous domain encoding allows for interpolation between domains and for extrapolation to unseen domains and translations. Additionally, we show how GMM-UNIT can be constrained down to different methods in the literature, meaning that GMM-UNIT is a unifying framework for unsupervised image-to-image translation.
Zero-Shot Contrastive Loss for Text-Guided Diffusion Image Style Transfer
Mar 15, 2023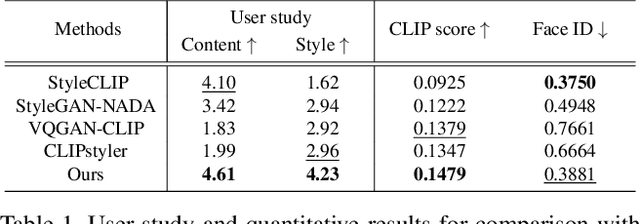
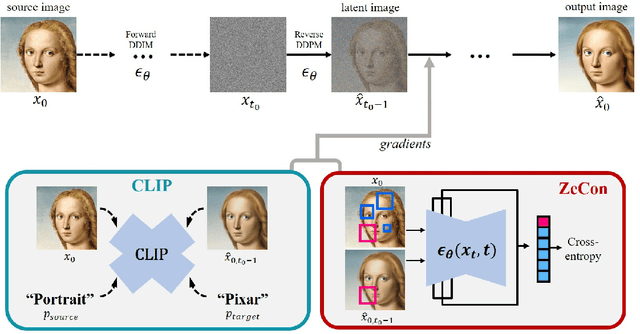
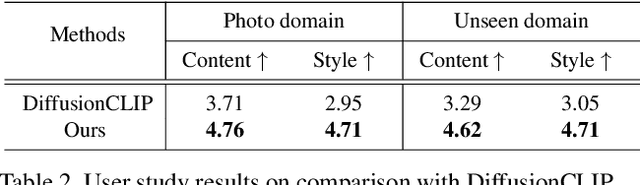
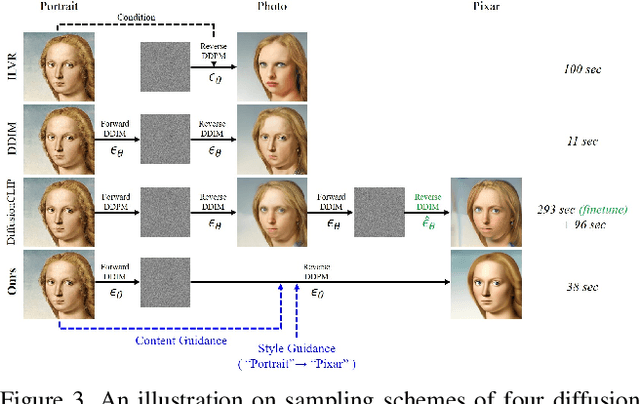
Diffusion models have shown great promise in text-guided image style transfer, but there is a trade-off between style transformation and content preservation due to their stochastic nature. Existing methods require computationally expensive fine-tuning of diffusion models or additional neural network. To address this, here we propose a zero-shot contrastive loss for diffusion models that doesn't require additional fine-tuning or auxiliary networks. By leveraging patch-wise contrastive loss between generated samples and original image embeddings in the pre-trained diffusion model, our method can generate images with the same semantic content as the source image in a zero-shot manner. Our approach outperforms existing methods while preserving content and requiring no additional training, not only for image style transfer but also for image-to-image translation and manipulation. Our experimental results validate the effectiveness of our proposed method.
An Efficient Image-to-Image Translation HourGlass-based Architecture for Object Pushing Policy Learning
Aug 02, 2021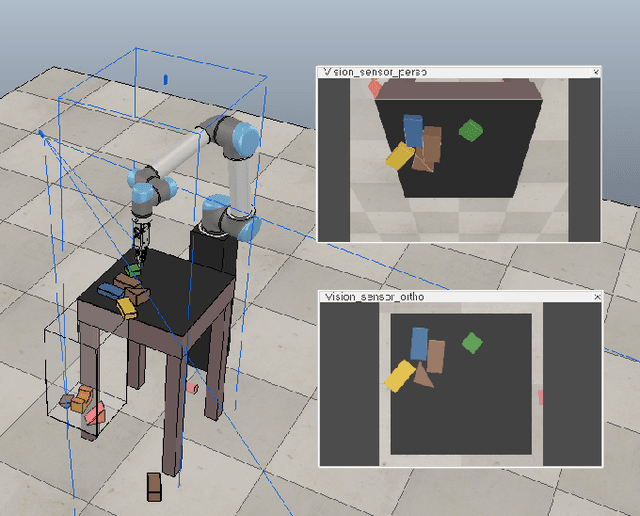
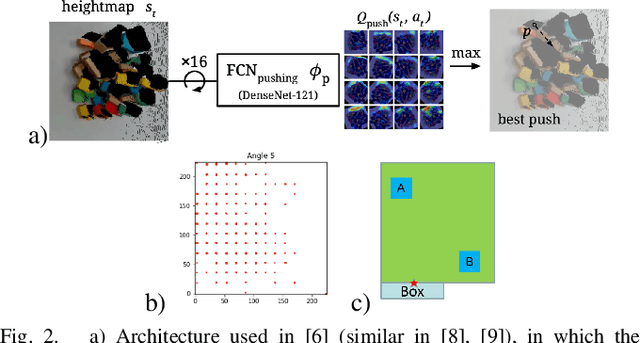
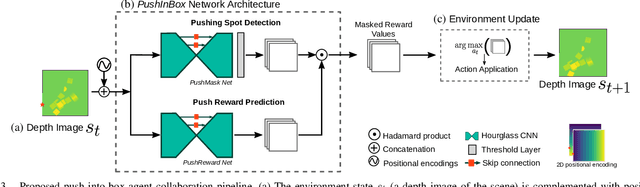
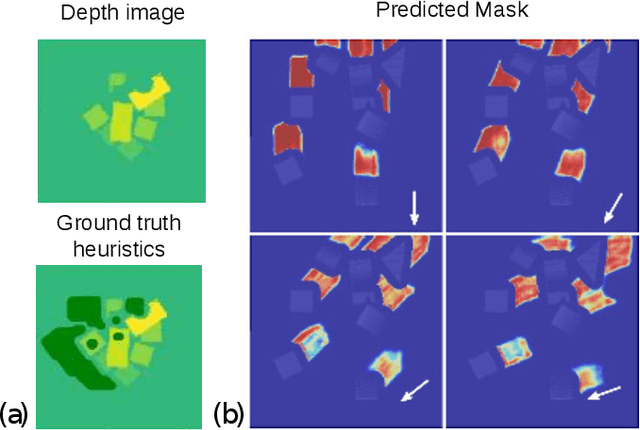
Humans effortlessly solve pushing tasks in everyday life but unlocking these capabilities remains a challenge in robotics because physics models of these tasks are often inaccurate or unattainable. State-of-the-art data-driven approaches learn to compensate for these inaccuracies or replace the approximated physics models altogether. Nevertheless, approaches like Deep Q-Networks (DQNs) suffer from local optima in large state-action spaces. Furthermore, they rely on well-chosen deep learning architectures and learning paradigms. In this paper, we propose to frame the learning of pushing policies (where to push and how) by DQNs as an image-to-image translation problem and exploit an Hourglass-based architecture. We present an architecture combining a predictor of which pushes lead to changes in the environment with a state-action value predictor dedicated to the pushing task. Moreover, we investigate positional information encoding to learn position-dependent policy behaviors. We demonstrate in simulation experiments with a UR5 robot arm that our overall architecture helps the DQN learn faster and achieve higher performance in a pushing task involving objects with unknown dynamics.
Independent Encoder for Deep Hierarchical Unsupervised Image-to-Image Translation
Jul 06, 2021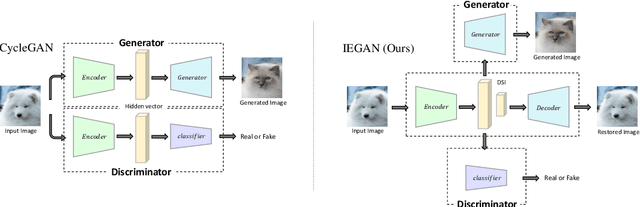
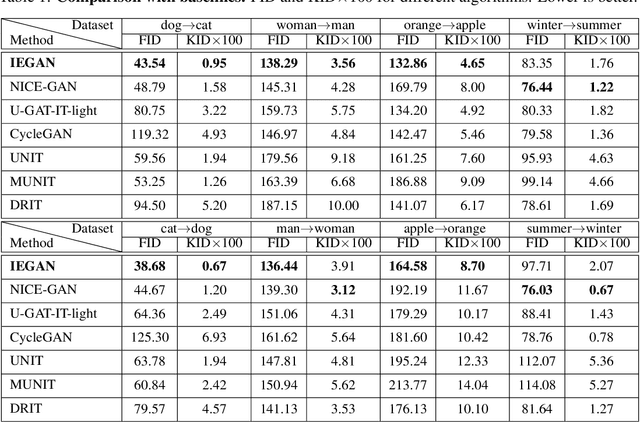
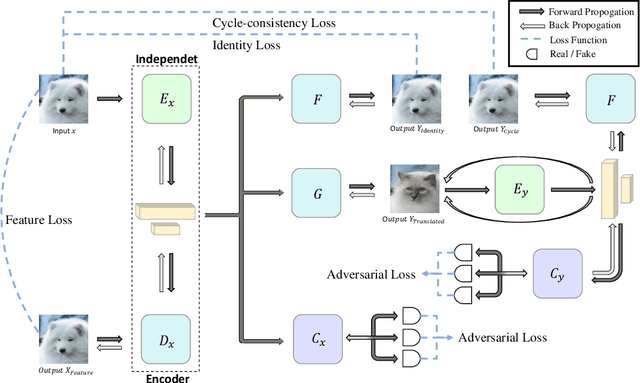
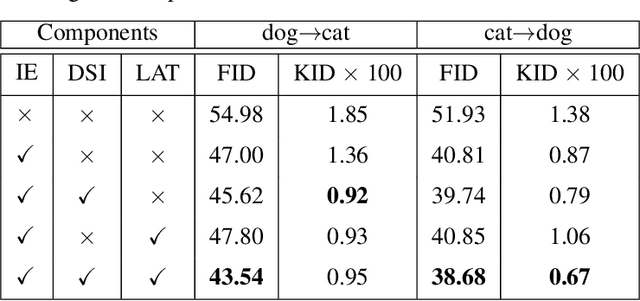
The main challenges of image-to-image (I2I) translation are to make the translated image realistic and retain as much information from the source domain as possible. To address this issue, we propose a novel architecture, termed as IEGAN, which removes the encoder of each network and introduces an encoder that is independent of other networks. Compared with previous models, it embodies three advantages of our model: Firstly, it is more directly and comprehensively to grasp image information since the encoder no longer receives loss from generator and discriminator. Secondly, the independent encoder allows each network to focus more on its own goal which makes the translated image more realistic. Thirdly, the reduction in the number of encoders performs more unified image representation. However, when the independent encoder applies two down-sampling blocks, it's hard to extract semantic information. To tackle this problem, we propose deep and shallow information space containing characteristic and semantic information, which can guide the model to translate high-quality images under the task with significant shape or texture change. We compare IEGAN with other previous models, and conduct researches on semantic information consistency and component ablation at the same time. These experiments show the superiority and effectiveness of our architecture. Our code is published on: https://github.com/Elvinky/IEGAN.
Energy-guided Entropic Neural Optimal Transport
Apr 12, 2023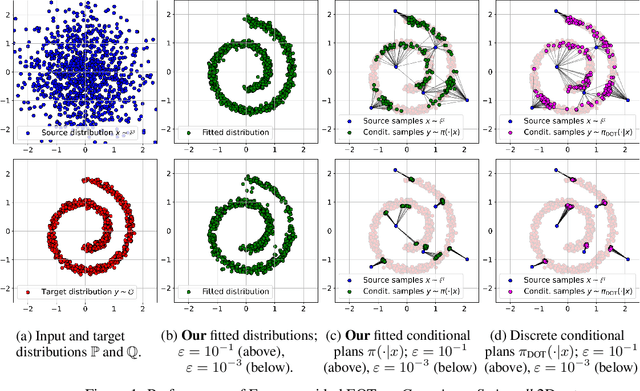
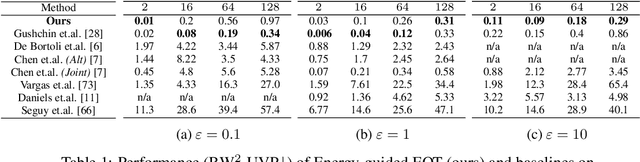


Energy-Based Models (EBMs) are known in the Machine Learning community for the decades. Since the seminal works devoted to EBMs dating back to the noughties there have been appearing a lot of efficient methods which solve the generative modelling problem by means of energy potentials (unnormalized likelihood functions). In contrast, the realm of Optimal Transport (OT) and, in particular, neural OT solvers is much less explored and limited by few recent works (excluding WGAN based approaches which utilize OT as a loss function and do not model OT maps themselves). In our work, we bridge the gap between EBMs and Entropy-regularized OT. We present the novel methodology which allows utilizing the recent developments and technical improvements of the former in order to enrich the latter. We validate the applicability of our method on toy 2D scenarios as well as standard unpaired image-to-image translation problems. For the sake of simplicity, we choose simple short- and long- run EBMs as a backbone of our Energy-guided Entropic OT method, leaving the application of more sophisticated EBMs for future research.
NPR: Nocturnal Place Recognition in Street
Apr 01, 2023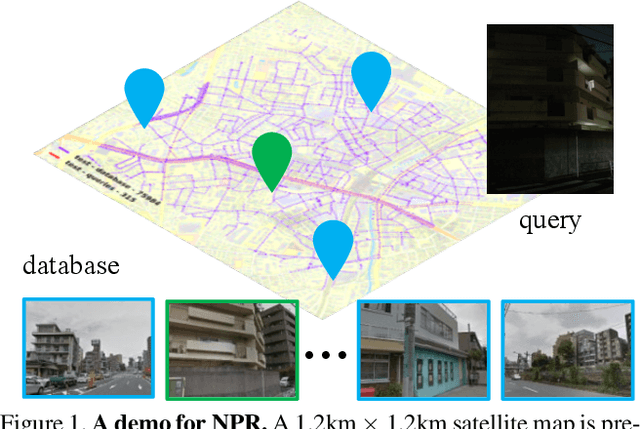
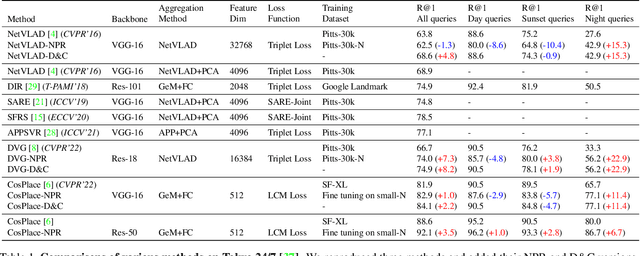


Visual Place Recognition (VPR) is the task of retrieving database images similar to a query photo by comparing it to a large database of known images. In real-world applications, extreme illumination changes caused by query images taken at night pose a significant obstacle that VPR needs to overcome. However, a training set with day-night correspondence for city-scale, street-level VPR does not exist. To address this challenge, we propose a novel pipeline that divides VPR and conquers Nocturnal Place Recognition (NPR). Specifically, we first established a street-level day-night dataset, NightStreet, and used it to train an unpaired image-to-image translation model. Then we used this model to process existing large-scale VPR datasets to generate the VPR-Night datasets and demonstrated how to combine them with two popular VPR pipelines. Finally, we proposed a divide-and-conquer VPR framework and provided explanations at the theoretical, experimental, and application levels. Under our framework, previous methods can significantly improve performance on two public datasets, including the top-ranked method.
Guided Image-to-Image Translation with Bi-Directional Feature Transformation
Oct 24, 2019
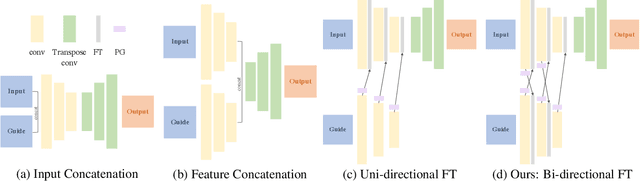
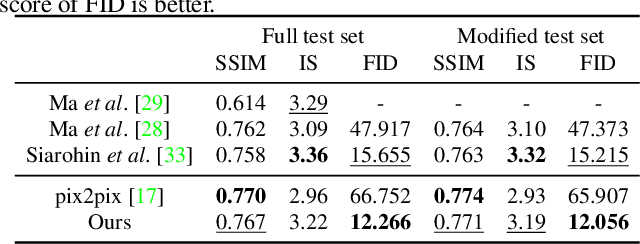
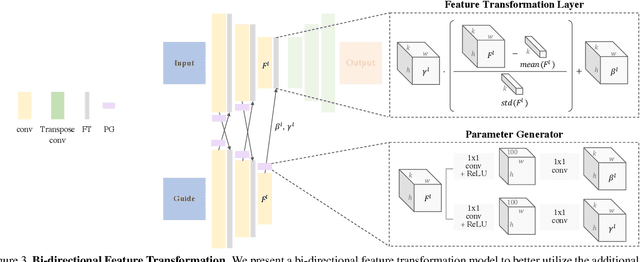
We address the problem of guided image-to-image translation where we translate an input image into another while respecting the constraints provided by an external, user-provided guidance image. Various conditioning methods for leveraging the given guidance image have been explored, including input concatenation , feature concatenation, and conditional affine transformation of feature activations. All these conditioning mechanisms, however, are uni-directional, i.e., no information flow from the input image back to the guidance. To better utilize the constraints of the guidance image, we present a bi-directional feature transformation (bFT) scheme. We show that our bFT scheme outperforms other conditioning schemes and has comparable results to state-of-the-art methods on different tasks.
TSIT: A Simple and Versatile Framework for Image-to-Image Translation
Jul 25, 2020
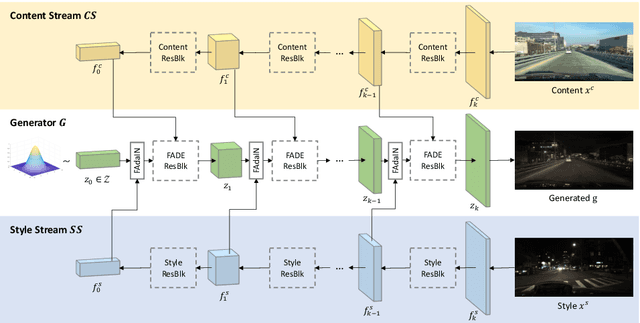
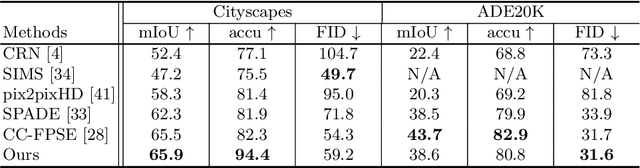
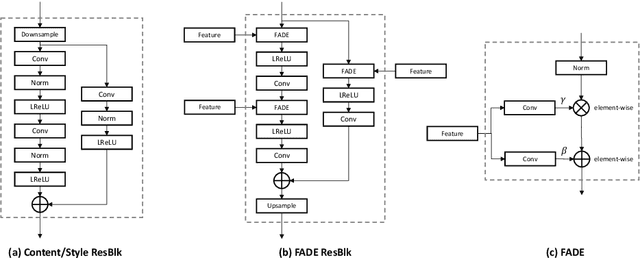
We introduce a simple and versatile framework for image-to-image translation. We unearth the importance of normalization layers, and provide a carefully designed two-stream generative model with newly proposed feature transformations in a coarse-to-fine fashion. This allows multi-scale semantic structure information and style representation to be effectively captured and fused by the network, permitting our method to scale to various tasks in both unsupervised and supervised settings. No additional constraints (e.g., cycle consistency) are needed, contributing to a very clean and simple method. Multi-modal image synthesis with arbitrary style control is made possible. A systematic study compares the proposed method with several state-of-the-art task-specific baselines, verifying its effectiveness in both perceptual quality and quantitative evaluations.
Extremal Domain Translation with Neural Optimal Transport
Jan 30, 2023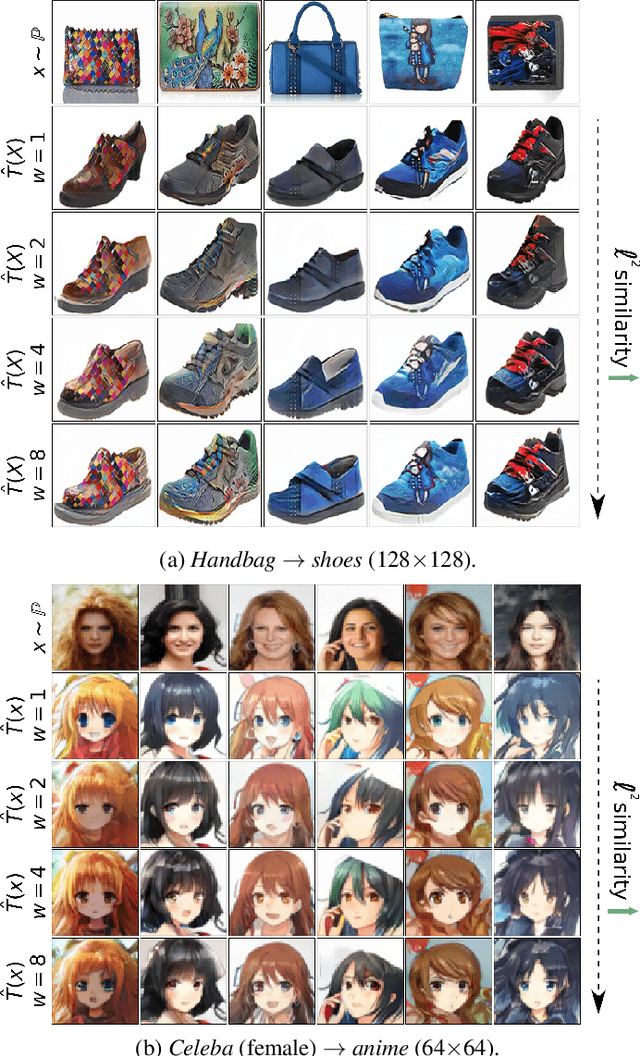
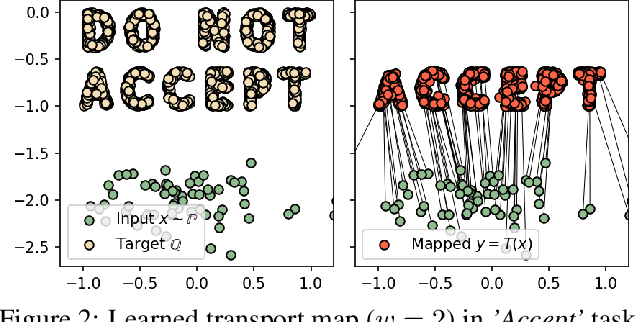
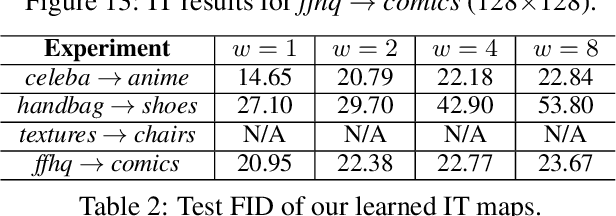
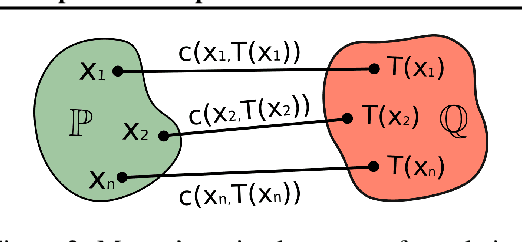
We propose the extremal transport (ET) which is a mathematical formalization of the theoretically best possible unpaired translation between a pair of domains w.r.t. the given similarity function. Inspired by the recent advances in neural optimal transport (OT), we propose a scalable algorithm to approximate ET maps as a limit of partial OT maps. We test our algorithm on toy examples and on the unpaired image-to-image translation task.