 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIndependent Encoder for Deep Hierarchical Unsupervised Image-to-Image Translation
Paper and Code
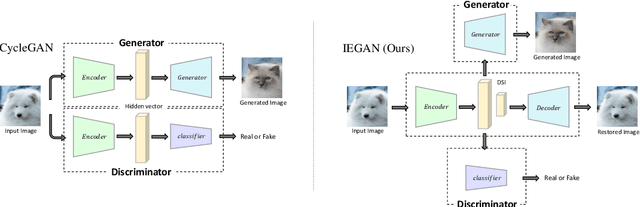
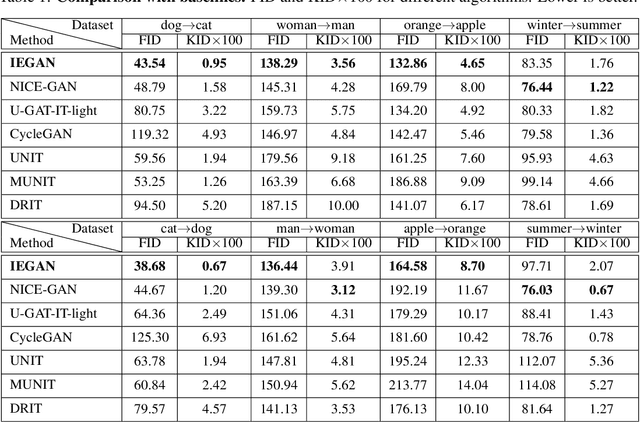
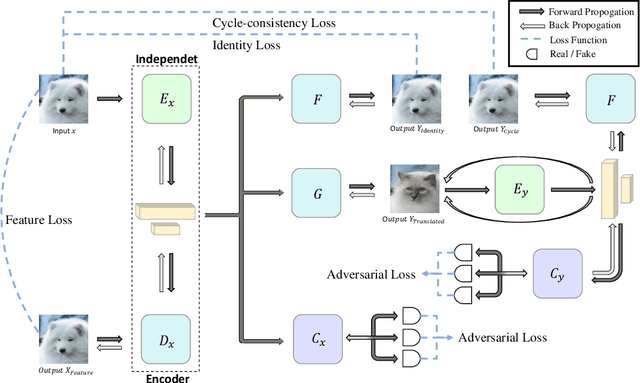
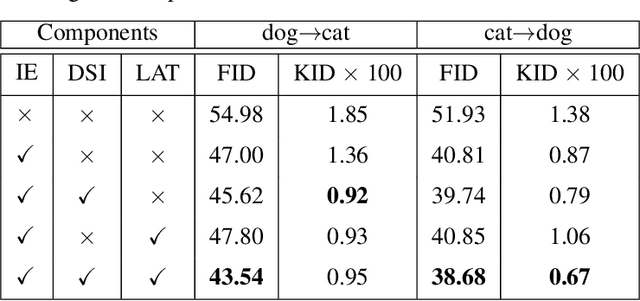
The main challenges of image-to-image (I2I) translation are to make the translated image realistic and retain as much information from the source domain as possible. To address this issue, we propose a novel architecture, termed as IEGAN, which removes the encoder of each network and introduces an encoder that is independent of other networks. Compared with previous models, it embodies three advantages of our model: Firstly, it is more directly and comprehensively to grasp image information since the encoder no longer receives loss from generator and discriminator. Secondly, the independent encoder allows each network to focus more on its own goal which makes the translated image more realistic. Thirdly, the reduction in the number of encoders performs more unified image representation. However, when the independent encoder applies two down-sampling blocks, it's hard to extract semantic information. To tackle this problem, we propose deep and shallow information space containing characteristic and semantic information, which can guide the model to translate high-quality images under the task with significant shape or texture change. We compare IEGAN with other previous models, and conduct researches on semantic information consistency and component ablation at the same time. These experiments show the superiority and effectiveness of our architecture. Our code is published on: https://github.com/Elvinky/IEGAN.