 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgefacial recognition
Facial recognition is an AI-based technique for identifying or confirming an individual's identity using their face. It maps facial features from an image or video and then compares the information with a collection of known faces to find a match.
Papers and Code
MEGC2025: Micro-Expression Grand Challenge on Spot Then Recognize and Visual Question Answering
Jun 18, 2025
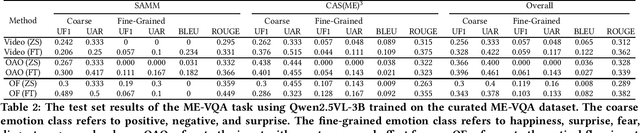
Facial micro-expressions (MEs) are involuntary movements of the face that occur spontaneously when a person experiences an emotion but attempts to suppress or repress the facial expression, typically found in a high-stakes environment. In recent years, substantial advancements have been made in the areas of ME recognition, spotting, and generation. However, conventional approaches that treat spotting and recognition as separate tasks are suboptimal, particularly for analyzing long-duration videos in realistic settings. Concurrently, the emergence of multimodal large language models (MLLMs) and large vision-language models (LVLMs) offers promising new avenues for enhancing ME analysis through their powerful multimodal reasoning capabilities. The ME grand challenge (MEGC) 2025 introduces two tasks that reflect these evolving research directions: (1) ME spot-then-recognize (ME-STR), which integrates ME spotting and subsequent recognition in a unified sequential pipeline; and (2) ME visual question answering (ME-VQA), which explores ME understanding through visual question answering, leveraging MLLMs or LVLMs to address diverse question types related to MEs. All participating algorithms are required to run on this test set and submit their results on a leaderboard. More details are available at https://megc2025.github.io.
Longitudinal Study of Facial Biometrics at the BEZ: Temporal Variance Analysis
Jul 09, 2025This study presents findings from long-term biometric evaluations conducted at the Biometric Evaluation Center (bez). Over the course of two and a half years, our ongoing research with over 400 participants representing diverse ethnicities, genders, and age groups were regularly assessed using a variety of biometric tools and techniques at the controlled testing facilities. Our findings are based on the General Data Protection Regulation-compliant local bez database with more than 238.000 biometric data sets categorized into multiple biometric modalities such as face and finger. We used state-of-the-art face recognition algorithms to analyze long-term comparison scores. Our results show that these scores fluctuate more significantly between individual days than over the entire measurement period. These findings highlight the importance of testing biometric characteristics of the same individuals over a longer period of time in a controlled measurement environment and lays the groundwork for future advancements in biometric data analysis.
Team RAS in 9th ABAW Competition: Multimodal Compound Expression Recognition Approach
Jul 02, 2025Compound Expression Recognition (CER), a subfield of affective computing, aims to detect complex emotional states formed by combinations of basic emotions. In this work, we present a novel zero-shot multimodal approach for CER that combines six heterogeneous modalities into a single pipeline: static and dynamic facial expressions, scene and label matching, scene context, audio, and text. Unlike previous approaches relying on task-specific training data, our approach uses zero-shot components, including Contrastive Language-Image Pretraining (CLIP)-based label matching and Qwen-VL for semantic scene understanding. We further introduce a Multi-Head Probability Fusion (MHPF) module that dynamically weights modality-specific predictions, followed by a Compound Expressions (CE) transformation module that uses Pair-Wise Probability Aggregation (PPA) and Pair-Wise Feature Similarity Aggregation (PFSA) methods to produce interpretable compound emotion outputs. Evaluated under multi-corpus training, the proposed approach shows F1 scores of 46.95% on AffWild2, 49.02% on Acted Facial Expressions in The Wild (AFEW), and 34.85% on C-EXPR-DB via zero-shot testing, which is comparable to the results of supervised approaches trained on target data. This demonstrates the effectiveness of the proposed approach for capturing CE without domain adaptation. The source code is publicly available.
ID-EA: Identity-driven Text Enhancement and Adaptation with Textual Inversion for Personalized Text-to-Image Generation
Jul 16, 2025Recently, personalized portrait generation with a text-to-image diffusion model has significantly advanced with Textual Inversion, emerging as a promising approach for creating high-fidelity personalized images. Despite its potential, current Textual Inversion methods struggle to maintain consistent facial identity due to semantic misalignments between textual and visual embedding spaces regarding identity. We introduce ID-EA, a novel framework that guides text embeddings to align with visual identity embeddings, thereby improving identity preservation in a personalized generation. ID-EA comprises two key components: the ID-driven Enhancer (ID-Enhancer) and the ID-conditioned Adapter (ID-Adapter). First, the ID-Enhancer integrates identity embeddings with a textual ID anchor, refining visual identity embeddings derived from a face recognition model using representative text embeddings. Then, the ID-Adapter leverages the identity-enhanced embedding to adapt the text condition, ensuring identity preservation by adjusting the cross-attention module in the pre-trained UNet model. This process encourages the text features to find the most related visual clues across the foreground snippets. Extensive quantitative and qualitative evaluations demonstrate that ID-EA substantially outperforms state-of-the-art methods in identity preservation metrics while achieving remarkable computational efficiency, generating personalized portraits approximately 15 times faster than existing approaches.
Privacy-preserving Preselection for Face Identification Based on Packing
Jul 03, 2025Face identification systems operating in the ciphertext domain have garnered significant attention due to increasing privacy concerns and the potential recovery of original facial data. However, as the size of ciphertext template libraries grows, the face retrieval process becomes progressively more time-intensive. To address this challenge, we propose a novel and efficient scheme for face retrieval in the ciphertext domain, termed Privacy-Preserving Preselection for Face Identification Based on Packing (PFIP). PFIP incorporates an innovative preselection mechanism to reduce computational overhead and a packing module to enhance the flexibility of biometric systems during the enrollment stage. Extensive experiments conducted on the LFW and CASIA datasets demonstrate that PFIP preserves the accuracy of the original face recognition model, achieving a 100% hit rate while retrieving 1,000 ciphertext face templates within 300 milliseconds. Compared to existing approaches, PFIP achieves a nearly 50x improvement in retrieval efficiency.
Towards Large-Scale Pose-Invariant Face Recognition Using Face Defrontalization
Jun 04, 2025Face recognition under extreme head poses is a challenging task. Ideally, a face recognition system should perform well across different head poses, which is known as pose-invariant face recognition. To achieve pose invariance, current approaches rely on sophisticated methods, such as face frontalization and various facial feature extraction model architectures. However, these methods are somewhat impractical in real-life settings and are typically evaluated on small scientific datasets, such as Multi-PIE. In this work, we propose the inverse method of face frontalization, called face defrontalization, to augment the training dataset of facial feature extraction model. The method does not introduce any time overhead during the inference step. The method is composed of: 1) training an adapted face defrontalization FFWM model on a frontal-profile pairs dataset, which has been preprocessed using our proposed face alignment method; 2) training a ResNet-50 facial feature extraction model based on ArcFace loss on a raw and randomly defrontalized large-scale dataset, where defrontalization was performed with our previously trained face defrontalization model. Our method was compared with the existing approaches on four open-access datasets: LFW, AgeDB, CFP, and Multi-PIE. Defrontalization shows improved results compared to models without defrontalization, while the proposed adjustments show clear superiority over the state-of-the-art face frontalization FFWM method on three larger open-access datasets, but not on the small Multi-PIE dataset for extreme poses (75 and 90 degrees). The results suggest that at least some of the current methods may be overfitted to small datasets.
MMME: A Spontaneous Multi-Modal Micro-Expression Dataset Enabling Visual-Physiological Fusion
Jun 12, 2025Micro-expressions (MEs) are subtle, fleeting nonverbal cues that reveal an individual's genuine emotional state. Their analysis has attracted considerable interest due to its promising applications in fields such as healthcare, criminal investigation, and human-computer interaction. However, existing ME research is limited to single visual modality, overlooking the rich emotional information conveyed by other physiological modalities, resulting in ME recognition and spotting performance far below practical application needs. Therefore, exploring the cross-modal association mechanism between ME visual features and physiological signals (PS), and developing a multimodal fusion framework, represents a pivotal step toward advancing ME analysis. This study introduces a novel ME dataset, MMME, which, for the first time, enables synchronized collection of facial action signals (MEs), central nervous system signals (EEG), and peripheral PS (PPG, RSP, SKT, EDA, and ECG). By overcoming the constraints of existing ME corpora, MMME comprises 634 MEs, 2,841 macro-expressions (MaEs), and 2,890 trials of synchronized multimodal PS, establishing a robust foundation for investigating ME neural mechanisms and conducting multimodal fusion-based analyses. Extensive experiments validate the dataset's reliability and provide benchmarks for ME analysis, demonstrating that integrating MEs with PS significantly enhances recognition and spotting performance. To the best of our knowledge, MMME is the most comprehensive ME dataset to date in terms of modality diversity. It provides critical data support for exploring the neural mechanisms of MEs and uncovering the visual-physiological synergistic effects, driving a paradigm shift in ME research from single-modality visual analysis to multimodal fusion. The dataset will be publicly available upon acceptance of this paper.
BAH Dataset for Ambivalence/Hesitancy Recognition in Videos for Behavioural Change
May 25, 2025



Recognizing complex emotions linked to ambivalence and hesitancy (A/H) can play a critical role in the personalization and effectiveness of digital behaviour change interventions. These subtle and conflicting emotions are manifested by a discord between multiple modalities, such as facial and vocal expressions, and body language. Although experts can be trained to identify A/H, integrating them into digital interventions is costly and less effective. Automatic learning systems provide a cost-effective alternative that can adapt to individual users, and operate seamlessly within real-time, and resource-limited environments. However, there are currently no datasets available for the design of ML models to recognize A/H. This paper introduces a first Behavioural Ambivalence/Hesitancy (BAH) dataset collected for subject-based multimodal recognition of A/H in videos. It contains videos from 224 participants captured across 9 provinces in Canada, with different age, and ethnicity. Through our web platform, we recruited participants to answer 7 questions, some of which were designed to elicit A/H while recording themselves via webcam with microphone. BAH amounts to 1,118 videos for a total duration of 8.26 hours with 1.5 hours of A/H. Our behavioural team annotated timestamp segments to indicate where A/H occurs, and provide frame- and video-level annotations with the A/H cues. Video transcripts and their timestamps are also included, along with cropped and aligned faces in each frame, and a variety of participants meta-data. We include results baselines for BAH at frame- and video-level recognition in multi-modal setups, in addition to zero-shot prediction, and for personalization using unsupervised domain adaptation. The limited performance of baseline models highlights the challenges of recognizing A/H in real-world videos. The data, code, and pretrained weights are available.
TokBench: Evaluating Your Visual Tokenizer before Visual Generation
May 26, 2025In this work, we reveal the limitations of visual tokenizers and VAEs in preserving fine-grained features, and propose a benchmark to evaluate reconstruction performance for two challenging visual contents: text and face. Visual tokenizers and VAEs have significantly advanced visual generation and multimodal modeling by providing more efficient compressed or quantized image representations. However, while helping production models reduce computational burdens, the information loss from image compression fundamentally limits the upper bound of visual generation quality. To evaluate this upper bound, we focus on assessing reconstructed text and facial features since they typically: 1) exist at smaller scales, 2) contain dense and rich textures, 3) are prone to collapse, and 4) are highly sensitive to human vision. We first collect and curate a diverse set of clear text and face images from existing datasets. Unlike approaches using VLM models, we employ established OCR and face recognition models for evaluation, ensuring accuracy while maintaining an exceptionally lightweight assessment process <span style="font-weight: bold; color: rgb(214, 21, 21);">requiring just 2GB memory and 4 minutes</span> to complete. Using our benchmark, we analyze text and face reconstruction quality across various scales for different image tokenizers and VAEs. Our results show modern visual tokenizers still struggle to preserve fine-grained features, especially at smaller scales. We further extend this evaluation framework to video, conducting comprehensive analysis of video tokenizers. Additionally, we demonstrate that traditional metrics fail to accurately reflect reconstruction performance for faces and text, while our proposed metrics serve as an effective complement.
EmoSign: A Multimodal Dataset for Understanding Emotions in American Sign Language
May 20, 2025Unlike spoken languages where the use of prosodic features to convey emotion is well studied, indicators of emotion in sign language remain poorly understood, creating communication barriers in critical settings. Sign languages present unique challenges as facial expressions and hand movements simultaneously serve both grammatical and emotional functions. To address this gap, we introduce EmoSign, the first sign video dataset containing sentiment and emotion labels for 200 American Sign Language (ASL) videos. We also collect open-ended descriptions of emotion cues. Annotations were done by 3 Deaf ASL signers with professional interpretation experience. Alongside the annotations, we include baseline models for sentiment and emotion classification. This dataset not only addresses a critical gap in existing sign language research but also establishes a new benchmark for understanding model capabilities in multimodal emotion recognition for sign languages. The dataset is made available at https://huggingface.co/datasets/catfang/emosign.