 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgephoto
Papers and Code
GSWorld: Closed-Loop Photo-Realistic Simulation Suite for Robotic Manipulation
Oct 23, 2025This paper presents GSWorld, a robust, photo-realistic simulator for robotics manipulation that combines 3D Gaussian Splatting with physics engines. Our framework advocates "closing the loop" of developing manipulation policies with reproducible evaluation of policies learned from real-robot data and sim2real policy training without using real robots. To enable photo-realistic rendering of diverse scenes, we propose a new asset format, which we term GSDF (Gaussian Scene Description File), that infuses Gaussian-on-Mesh representation with robot URDF and other objects. With a streamlined reconstruction pipeline, we curate a database of GSDF that contains 3 robot embodiments for single-arm and bimanual manipulation, as well as more than 40 objects. Combining GSDF with physics engines, we demonstrate several immediate interesting applications: (1) learning zero-shot sim2real pixel-to-action manipulation policy with photo-realistic rendering, (2) automated high-quality DAgger data collection for adapting policies to deployment environments, (3) reproducible benchmarking of real-robot manipulation policies in simulation, (4) simulation data collection by virtual teleoperation, and (5) zero-shot sim2real visual reinforcement learning. Website: https://3dgsworld.github.io/.
Capture, Canonicalize, Splat: Zero-Shot 3D Gaussian Avatars from Unstructured Phone Images
Oct 15, 2025We present a novel, zero-shot pipeline for creating hyperrealistic, identity-preserving 3D avatars from a few unstructured phone images. Existing methods face several challenges: single-view approaches suffer from geometric inconsistencies and hallucinations, degrading identity preservation, while models trained on synthetic data fail to capture high-frequency details like skin wrinkles and fine hair, limiting realism. Our method introduces two key contributions: (1) a generative canonicalization module that processes multiple unstructured views into a standardized, consistent representation, and (2) a transformer-based model trained on a new, large-scale dataset of high-fidelity Gaussian splatting avatars derived from dome captures of real people. This "Capture, Canonicalize, Splat" pipeline produces static quarter-body avatars with compelling realism and robust identity preservation from unstructured photos.
SyncHuman: Synchronizing 2D and 3D Generative Models for Single-view Human Reconstruction
Oct 09, 2025Photorealistic 3D full-body human reconstruction from a single image is a critical yet challenging task for applications in films and video games due to inherent ambiguities and severe self-occlusions. While recent approaches leverage SMPL estimation and SMPL-conditioned image generative models to hallucinate novel views, they suffer from inaccurate 3D priors estimated from SMPL meshes and have difficulty in handling difficult human poses and reconstructing fine details. In this paper, we propose SyncHuman, a novel framework that combines 2D multiview generative model and 3D native generative model for the first time, enabling high-quality clothed human mesh reconstruction from single-view images even under challenging human poses. Multiview generative model excels at capturing fine 2D details but struggles with structural consistency, whereas 3D native generative model generates coarse yet structurally consistent 3D shapes. By integrating the complementary strengths of these two approaches, we develop a more effective generation framework. Specifically, we first jointly fine-tune the multiview generative model and the 3D native generative model with proposed pixel-aligned 2D-3D synchronization attention to produce geometrically aligned 3D shapes and 2D multiview images. To further improve details, we introduce a feature injection mechanism that lifts fine details from 2D multiview images onto the aligned 3D shapes, enabling accurate and high-fidelity reconstruction. Extensive experiments demonstrate that SyncHuman achieves robust and photo-realistic 3D human reconstruction, even for images with challenging poses. Our method outperforms baseline methods in geometric accuracy and visual fidelity, demonstrating a promising direction for future 3D generation models.
Virtual Fashion Photo-Shoots: Building a Large-Scale Garment-Lookbook Dataset
Oct 01, 2025Fashion image generation has so far focused on narrow tasks such as virtual try-on, where garments appear in clean studio environments. In contrast, editorial fashion presents garments through dynamic poses, diverse locations, and carefully crafted visual narratives. We introduce the task of virtual fashion photo-shoot, which seeks to capture this richness by transforming standardized garment images into contextually grounded editorial imagery. To enable this new direction, we construct the first large-scale dataset of garment-lookbook pairs, bridging the gap between e-commerce and fashion media. Because such pairs are not readily available, we design an automated retrieval pipeline that aligns garments across domains, combining visual-language reasoning with object-level localization. We construct a dataset with three garment-lookbook pair accuracy levels: high quality (10,000 pairs), medium quality (50,000 pairs), and low quality (300,000 pairs). This dataset offers a foundation for models that move beyond catalog-style generation and toward fashion imagery that reflects creativity, atmosphere, and storytelling.
DiffCamera: Arbitrary Refocusing on Images
Sep 30, 2025



The depth-of-field (DoF) effect, which introduces aesthetically pleasing blur, enhances photographic quality but is fixed and difficult to modify once the image has been created. This becomes problematic when the applied blur is undesirable~(e.g., the subject is out of focus). To address this, we propose DiffCamera, a model that enables flexible refocusing of a created image conditioned on an arbitrary new focus point and a blur level. Specifically, we design a diffusion transformer framework for refocusing learning. However, the training requires pairs of data with different focus planes and bokeh levels in the same scene, which are hard to acquire. To overcome this limitation, we develop a simulation-based pipeline to generate large-scale image pairs with varying focus planes and bokeh levels. With the simulated data, we find that training with only a vanilla diffusion objective often leads to incorrect DoF behaviors due to the complexity of the task. This requires a stronger constraint during training. Inspired by the photographic principle that photos of different focus planes can be linearly blended into a multi-focus image, we propose a stacking constraint during training to enforce precise DoF manipulation. This constraint enhances model training by imposing physically grounded refocusing behavior that the focusing results should be faithfully aligned with the scene structure and the camera conditions so that they can be combined into the correct multi-focus image. We also construct a benchmark to evaluate the effectiveness of our refocusing model. Extensive experiments demonstrate that DiffCamera supports stable refocusing across a wide range of scenes, providing unprecedented control over DoF adjustments for photography and generative AI applications.
Hierarchical Representation Matching for CLIP-based Class-Incremental Learning
Sep 26, 2025Class-Incremental Learning (CIL) aims to endow models with the ability to continuously adapt to evolving data streams. Recent advances in pre-trained vision-language models (e.g., CLIP) provide a powerful foundation for this task. However, existing approaches often rely on simplistic templates, such as "a photo of a [CLASS]", which overlook the hierarchical nature of visual concepts. For example, recognizing "cat" versus "car" depends on coarse-grained cues, while distinguishing "cat" from "lion" requires fine-grained details. Similarly, the current feature mapping in CLIP relies solely on the representation from the last layer, neglecting the hierarchical information contained in earlier layers. In this work, we introduce HiErarchical Representation MAtchiNg (HERMAN) for CLIP-based CIL. Our approach leverages LLMs to recursively generate discriminative textual descriptors, thereby augmenting the semantic space with explicit hierarchical cues. These descriptors are matched to different levels of the semantic hierarchy and adaptively routed based on task-specific requirements, enabling precise discrimination while alleviating catastrophic forgetting in incremental tasks. Extensive experiments on multiple benchmarks demonstrate that our method consistently achieves state-of-the-art performance.
MS-GS: Multi-Appearance Sparse-View 3D Gaussian Splatting in the Wild
Sep 19, 2025



In-the-wild photo collections often contain limited volumes of imagery and exhibit multiple appearances, e.g., taken at different times of day or seasons, posing significant challenges to scene reconstruction and novel view synthesis. Although recent adaptations of Neural Radiance Field (NeRF) and 3D Gaussian Splatting (3DGS) have improved in these areas, they tend to oversmooth and are prone to overfitting. In this paper, we present MS-GS, a novel framework designed with Multi-appearance capabilities in Sparse-view scenarios using 3DGS. To address the lack of support due to sparse initializations, our approach is built on the geometric priors elicited from monocular depth estimations. The key lies in extracting and utilizing local semantic regions with a Structure-from-Motion (SfM) points anchored algorithm for reliable alignment and geometry cues. Then, to introduce multi-view constraints, we propose a series of geometry-guided supervision at virtual views in a fine-grained and coarse scheme to encourage 3D consistency and reduce overfitting. We also introduce a dataset and an in-the-wild experiment setting to set up more realistic benchmarks. We demonstrate that MS-GS achieves photorealistic renderings under various challenging sparse-view and multi-appearance conditions and outperforms existing approaches significantly across different datasets.
Large Vision Models Can Solve Mental Rotation Problems
Sep 18, 2025Mental rotation is a key test of spatial reasoning in humans and has been central to understanding how perception supports cognition. Despite the success of modern vision transformers, it is still unclear how well these models develop similar abilities. In this work, we present a systematic evaluation of ViT, CLIP, DINOv2, and DINOv3 across a range of mental-rotation tasks, from simple block structures similar to those used by Shepard and Metzler to study human cognition, to more complex block figures, three types of text, and photo-realistic objects. By probing model representations layer by layer, we examine where and how these networks succeed. We find that i) self-supervised ViTs capture geometric structure better than supervised ViTs; ii) intermediate layers perform better than final layers; iii) task difficulty increases with rotation complexity and occlusion, mirroring human reaction times and suggesting similar constraints in embedding space representations.
A Race Bias Free Face Aging Model for Reliable Kinship Verification
Sep 18, 2025The age gap in kinship verification addresses the time difference between the photos of the parent and the child. Moreover, their same-age photos are often unavailable, and face aging models are racially biased, which impacts the likeness of photos. Therefore, we propose a face aging GAN model, RA-GAN, consisting of two new modules, RACEpSp and a feature mixer, to produce racially unbiased images. The unbiased synthesized photos are used in kinship verification to investigate the results of verifying same-age parent-child images. The experiments demonstrate that our RA-GAN outperforms SAM-GAN on an average of 13.14\% across all age groups, and CUSP-GAN in the 60+ age group by 9.1\% in terms of racial accuracy. Moreover, RA-GAN can preserve subjects' identities better than SAM-GAN and CUSP-GAN across all age groups. Additionally, we demonstrate that transforming parent and child images from the KinFaceW-I and KinFaceW-II datasets to the same age can enhance the verification accuracy across all age groups. The accuracy increases with our RA-GAN for the kinship relationships of father-son and father-daughter, mother-son, and mother-daughter, which are 5.22, 5.12, 1.63, and 0.41, respectively, on KinFaceW-I. Additionally, the accuracy for the relationships of father-daughter, father-son, and mother-son is 2.9, 0.39, and 1.6 on KinFaceW-II, respectively. The code is available at~\href{https://github.com/bardiya2254kariminia/An-Age-Transformation-whitout-racial-bias-for-Kinship-verification}{Github}
Performance Optimization of YOLO-FEDER FusionNet for Robust Drone Detection in Visually Complex Environments
Sep 17, 2025
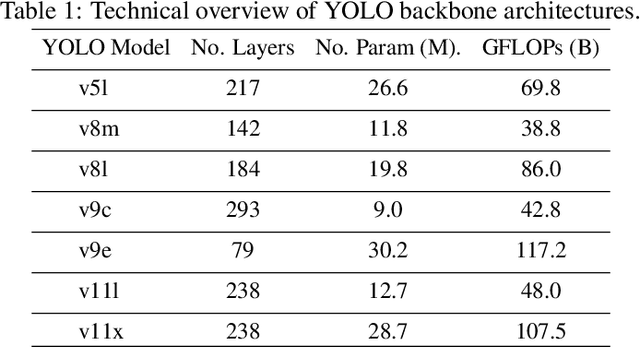
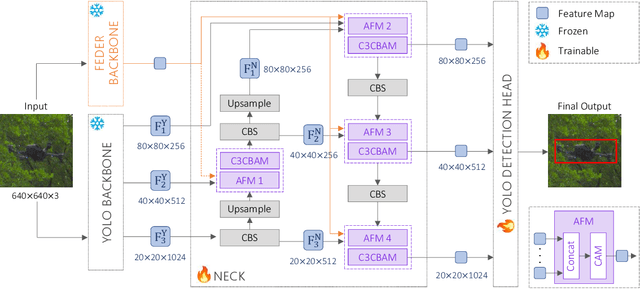
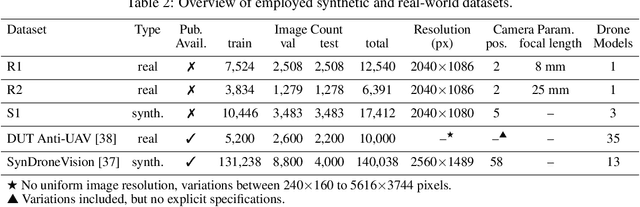
Drone detection in visually complex environments remains challenging due to background clutter, small object scale, and camouflage effects. While generic object detectors like YOLO exhibit strong performance in low-texture scenes, their effectiveness degrades in cluttered environments with low object-background separability. To address these limitations, this work presents an enhanced iteration of YOLO-FEDER FusionNet -- a detection framework that integrates generic object detection with camouflage object detection techniques. Building upon the original architecture, the proposed iteration introduces systematic advancements in training data composition, feature fusion strategies, and backbone design. Specifically, the training process leverages large-scale, photo-realistic synthetic data, complemented by a small set of real-world samples, to enhance robustness under visually complex conditions. The contribution of intermediate multi-scale FEDER features is systematically evaluated, and detection performance is comprehensively benchmarked across multiple YOLO-based backbone configurations. Empirical results indicate that integrating intermediate FEDER features, in combination with backbone upgrades, contributes to notable performance improvements. In the most promising configuration -- YOLO-FEDER FusionNet with a YOLOv8l backbone and FEDER features derived from the DWD module -- these enhancements lead to a FNR reduction of up to 39.1 percentage points and a mAP increase of up to 62.8 percentage points at an IoU threshold of 0.5, compared to the initial baseline.