 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgephoto
Papers and Code
Structure-preserving Feature Alignment for Old Photo Colorization
Aug 18, 2025Deep learning techniques have made significant advancements in reference-based colorization by training on large-scale datasets. However, directly applying these methods to the task of colorizing old photos is challenging due to the lack of ground truth and the notorious domain gap between natural gray images and old photos. To address this issue, we propose a novel CNN-based algorithm called SFAC, i.e., Structure-preserving Feature Alignment Colorizer. SFAC is trained on only two images for old photo colorization, eliminating the reliance on big data and allowing direct processing of the old photo itself to overcome the domain gap problem. Our primary objective is to establish semantic correspondence between the two images, ensuring that semantically related objects have similar colors. We achieve this through a feature distribution alignment loss that remains robust to different metric choices. However, utilizing robust semantic correspondence to transfer color from the reference to the old photo can result in inevitable structure distortions. To mitigate this, we introduce a structure-preserving mechanism that incorporates a perceptual constraint at the feature level and a frozen-updated pyramid at the pixel level. Extensive experiments demonstrate the effectiveness of our method for old photo colorization, as confirmed by qualitative and quantitative metrics.
TechOps: Technical Documentation Templates for the AI Act
Aug 12, 2025Operationalizing the EU AI Act requires clear technical documentation to ensure AI systems are transparent, traceable, and accountable. Existing documentation templates for AI systems do not fully cover the entire AI lifecycle while meeting the technical documentation requirements of the AI Act. This paper addresses those shortcomings by introducing open-source templates and examples for documenting data, models, and applications to provide sufficient documentation for certifying compliance with the AI Act. These templates track the system status over the entire AI lifecycle, ensuring traceability, reproducibility, and compliance with the AI Act. They also promote discoverability and collaboration, reduce risks, and align with best practices in AI documentation and governance. The templates are evaluated and refined based on user feedback to enable insights into their usability and implementability. We then validate the approach on real-world scenarios, providing examples that further guide their implementation: the data template is followed to document a skin tones dataset created to support fairness evaluations of downstream computer vision models and human-centric applications; the model template is followed to document a neural network for segmenting human silhouettes in photos. The application template is tested on a system deployed for construction site safety using real-time video analytics and sensor data. Our results show that TechOps can serve as a practical tool to enable oversight for regulatory compliance and responsible AI development.
Communication Efficient Robotic Mixed Reality with Gaussian Splatting Cross-Layer Optimization
Aug 12, 2025



Realizing low-cost communication in robotic mixed reality (RoboMR) systems presents a challenge, due to the necessity of uploading high-resolution images through wireless channels. This paper proposes Gaussian splatting (GS) RoboMR (GSMR), which enables the simulator to opportunistically render a photo-realistic view from the robot's pose by calling ``memory'' from a GS model, thus reducing the need for excessive image uploads. However, the GS model may involve discrepancies compared to the actual environments. To this end, a GS cross-layer optimization (GSCLO) framework is further proposed, which jointly optimizes content switching (i.e., deciding whether to upload image or not) and power allocation (i.e., adjusting to content profiles) across different frames by minimizing a newly derived GSMR loss function. The GSCLO problem is addressed by an accelerated penalty optimization (APO) algorithm that reduces computational complexity by over $10$x compared to traditional branch-and-bound and search algorithms. Moreover, variants of GSCLO are presented to achieve robust, low-power, and multi-robot GSMR. Extensive experiments demonstrate that the proposed GSMR paradigm and GSCLO method achieve significant improvements over existing benchmarks on both wheeled and legged robots in terms of diverse metrics in various scenarios. For the first time, it is found that RoboMR can be achieved with ultra-low communication costs, and mixture of data is useful for enhancing GS performance in dynamic scenarios.
Undress to Redress: A Training-Free Framework for Virtual Try-On
Aug 11, 2025Virtual try-on (VTON) is a crucial task for enhancing user experience in online shopping by generating realistic garment previews on personal photos. Although existing methods have achieved impressive results, they struggle with long-sleeve-to-short-sleeve conversions-a common and practical scenario-often producing unrealistic outputs when exposed skin is underrepresented in the original image. We argue that this challenge arises from the ''majority'' completion rule in current VTON models, which leads to inaccurate skin restoration in such cases. To address this, we propose UR-VTON (Undress-Redress Virtual Try-ON), a novel, training-free framework that can be seamlessly integrated with any existing VTON method. UR-VTON introduces an ''undress-to-redress'' mechanism: it first reveals the user's torso by virtually ''undressing,'' then applies the target short-sleeve garment, effectively decomposing the conversion into two more manageable steps. Additionally, we incorporate Dynamic Classifier-Free Guidance scheduling to balance diversity and image quality during DDPM sampling, and employ Structural Refiner to enhance detail fidelity using high-frequency cues. Finally, we present LS-TON, a new benchmark for long-sleeve-to-short-sleeve try-on. Extensive experiments demonstrate that UR-VTON outperforms state-of-the-art methods in both detail preservation and image quality. Code will be released upon acceptance.
NeeCo: Image Synthesis of Novel Instrument States Based on Dynamic and Deformable 3D Gaussian Reconstruction
Aug 11, 2025



Computer vision-based technologies significantly enhance surgical automation by advancing tool tracking, detection, and localization. However, Current data-driven approaches are data-voracious, requiring large, high-quality labeled image datasets, which limits their application in surgical data science. Our Work introduces a novel dynamic Gaussian Splatting technique to address the data scarcity in surgical image datasets. We propose a dynamic Gaussian model to represent dynamic surgical scenes, enabling the rendering of surgical instruments from unseen viewpoints and deformations with real tissue backgrounds. We utilize a dynamic training adjustment strategy to address challenges posed by poorly calibrated camera poses from real-world scenarios. Additionally, we propose a method based on dynamic Gaussians for automatically generating annotations for our synthetic data. For evaluation, we constructed a new dataset featuring seven scenes with 14,000 frames of tool and camera motion and tool jaw articulation, with a background of an ex-vivo porcine model. Using this dataset, we synthetically replicate the scene deformation from the ground truth data, allowing direct comparisons of synthetic image quality. Experimental results illustrate that our method generates photo-realistic labeled image datasets with the highest values in Peak-Signal-to-Noise Ratio (29.87). We further evaluate the performance of medical-specific neural networks trained on real and synthetic images using an unseen real-world image dataset. Our results show that the performance of models trained on synthetic images generated by the proposed method outperforms those trained with state-of-the-art standard data augmentation by 10%, leading to an overall improvement in model performances by nearly 15%.
GS4Buildings: Prior-Guided Gaussian Splatting for 3D Building Reconstruction
Aug 10, 2025
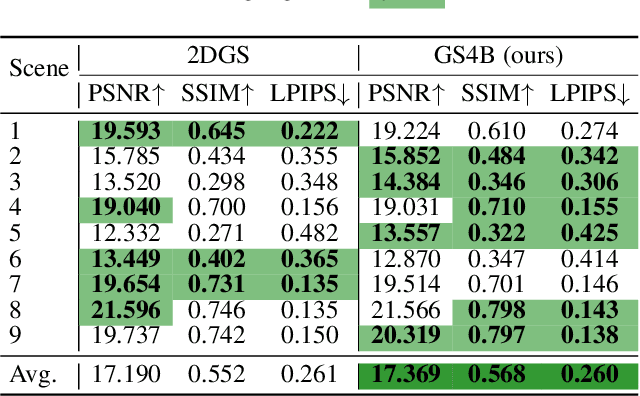
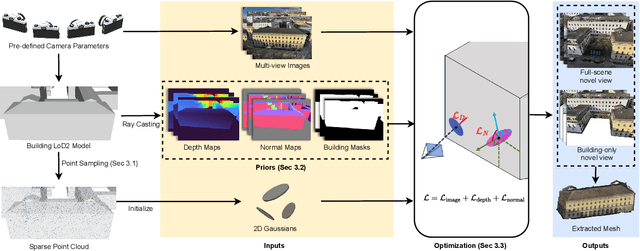

Recent advances in Gaussian Splatting (GS) have demonstrated its effectiveness in photo-realistic rendering and 3D reconstruction. Among these, 2D Gaussian Splatting (2DGS) is particularly suitable for surface reconstruction due to its flattened Gaussian representation and integrated normal regularization. However, its performance often degrades in large-scale and complex urban scenes with frequent occlusions, leading to incomplete building reconstructions. We propose GS4Buildings, a novel prior-guided Gaussian Splatting method leveraging the ubiquity of semantic 3D building models for robust and scalable building surface reconstruction. Instead of relying on traditional Structure-from-Motion (SfM) pipelines, GS4Buildings initializes Gaussians directly from low-level Level of Detail (LoD)2 semantic 3D building models. Moreover, we generate prior depth and normal maps from the planar building geometry and incorporate them into the optimization process, providing strong geometric guidance for surface consistency and structural accuracy. We also introduce an optional building-focused mode that limits reconstruction to building regions, achieving a 71.8% reduction in Gaussian primitives and enabling a more efficient and compact representation. Experiments on urban datasets demonstrate that GS4Buildings improves reconstruction completeness by 20.5% and geometric accuracy by 32.8%. These results highlight the potential of semantic building model integration to advance GS-based reconstruction toward real-world urban applications such as smart cities and digital twins. Our project is available: https://github.com/zqlin0521/GS4Buildings.
Textual Inversion for Efficient Adaptation of Open-Vocabulary Object Detectors Without Forgetting
Aug 07, 2025Recent progress in large pre-trained vision language models (VLMs) has reached state-of-the-art performance on several object detection benchmarks and boasts strong zero-shot capabilities, but for optimal performance on specific targets some form of finetuning is still necessary. While the initial VLM weights allow for great few-shot transfer learning, this usually involves the loss of the original natural language querying and zero-shot capabilities. Inspired by the success of Textual Inversion (TI) in personalizing text-to-image diffusion models, we propose a similar formulation for open-vocabulary object detection. TI allows extending the VLM vocabulary by learning new or improving existing tokens to accurately detect novel or fine-grained objects from as little as three examples. The learned tokens are completely compatible with the original VLM weights while keeping them frozen, retaining the original model's benchmark performance, and leveraging its existing capabilities such as zero-shot domain transfer (e.g., detecting a sketch of an object after training only on real photos). The storage and gradient calculations are limited to the token embedding dimension, requiring significantly less compute than full-model fine-tuning. We evaluated whether the method matches or outperforms the baseline methods that suffer from forgetting in a wide variety of quantitative and qualitative experiments.
YOLOv8-Based Deep Learning Model for Automated Poultry Disease Detection and Health Monitoring paper
Aug 06, 2025



In the poultry industry, detecting chicken illnesses is essential to avoid financial losses. Conventional techniques depend on manual observation, which is laborious and prone to mistakes. Using YOLO v8 a deep learning model for real-time object recognition. This study suggests an AI based approach, by developing a system that analyzes high resolution chicken photos, YOLO v8 detects signs of illness, such as abnormalities in behavior and appearance. A sizable, annotated dataset has been used to train the algorithm, which provides accurate real-time identification of infected chicken and prompt warnings to farm operators for prompt action. By facilitating early infection identification, eliminating the need for human inspection, and enhancing biosecurity in large-scale farms, this AI technology improves chicken health management. The real-time features of YOLO v8 provide a scalable and effective method for improving farm management techniques.
A Mixed User-Centered Approach to Enable Augmented Intelligence in Intelligent Tutoring Systems: The Case of MathAIde app
Jul 31, 2025Integrating Artificial Intelligence in Education (AIED) aims to enhance learning experiences through technologies like Intelligent Tutoring Systems (ITS), offering personalized learning, increased engagement, and improved retention rates. However, AIED faces three main challenges: the critical role of teachers in the design process, the limitations and reliability of AI tools, and the accessibility of technological resources. Augmented Intelligence (AuI) addresses these challenges by enhancing human capabilities rather than replacing them, allowing systems to suggest solutions. In contrast, humans provide final assessments, thus improving AI over time. In this sense, this study focuses on designing, developing, and evaluating MathAIde, an ITS that corrects mathematics exercises using computer vision and AI and provides feedback based on photos of student work. The methodology included brainstorming sessions with potential users, high-fidelity prototyping, A/B testing, and a case study involving real-world classroom environments for teachers and students. Our research identified several design possibilities for implementing AuI in ITSs, emphasizing a balance between user needs and technological feasibility. Prioritization and validation through prototyping and testing highlighted the importance of efficiency metrics, ultimately leading to a solution that offers pre-defined remediation alternatives for teachers. Real-world deployment demonstrated the usefulness of the proposed solution. Our research contributes to the literature by providing a usable, teacher-centered design approach that involves teachers in all design phases. As a practical implication, we highlight that the user-centered design approach increases the usefulness and adoption potential of AIED systems, especially in resource-limited environments.
JWB-DH-V1: Benchmark for Joint Whole-Body Talking Avatar and Speech Generation Version 1
Jul 28, 2025Recent advances in diffusion-based video generation have enabled photo-realistic short clips, but current methods still struggle to achieve multi-modal consistency when jointly generating whole-body motion and natural speech. Current approaches lack comprehensive evaluation frameworks that assess both visual and audio quality, and there are insufficient benchmarks for region-specific performance analysis. To address these gaps, we introduce the Joint Whole-Body Talking Avatar and Speech Generation Version I(JWB-DH-V1), comprising a large-scale multi-modal dataset with 10,000 unique identities across 2 million video samples, and an evaluation protocol for assessing joint audio-video generation of whole-body animatable avatars. Our evaluation of SOTA models reveals consistent performance disparities between face/hand-centric and whole-body performance, which incidates essential areas for future research. The dataset and evaluation tools are publicly available at https://github.com/deepreasonings/WholeBodyBenchmark.