 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWsj0 3mix
Papers and Code
Boosting Unknown-number Speaker Separation with Transformer Decoder-based Attractor
Jan 23, 2024We propose a novel speech separation model designed to separate mixtures with an unknown number of speakers. The proposed model stacks 1) a dual-path processing block that can model spectro-temporal patterns, 2) a transformer decoder-based attractor (TDA) calculation module that can deal with an unknown number of speakers, and 3) triple-path processing blocks that can model inter-speaker relations. Given a fixed, small set of learned speaker queries and the mixture embedding produced by the dual-path blocks, TDA infers the relations of these queries and generates an attractor vector for each speaker. The estimated attractors are then combined with the mixture embedding by feature-wise linear modulation conditioning, creating a speaker dimension. The mixture embedding, conditioned with speaker information produced by TDA, is fed to the final triple-path blocks, which augment the dual-path blocks with an additional pathway dedicated to inter-speaker processing. The proposed approach outperforms the previous best reported in the literature, achieving 24.0 and 23.7 dB SI-SDR improvement (SI-SDRi) on WSJ0-2 and 3mix respectively, with a single model trained to separate 2- and 3-speaker mixtures. The proposed model also exhibits strong performance and generalizability at counting sources and separating mixtures with up to 5 speakers.
Conformer-based Target-Speaker Automatic Speech Recognition for Single-Channel Audio
Aug 09, 2023



We propose CONF-TSASR, a non-autoregressive end-to-end time-frequency domain architecture for single-channel target-speaker automatic speech recognition (TS-ASR). The model consists of a TitaNet based speaker embedding module, a Conformer based masking as well as ASR modules. These modules are jointly optimized to transcribe a target-speaker, while ignoring speech from other speakers. For training we use Connectionist Temporal Classification (CTC) loss and introduce a scale-invariant spectrogram reconstruction loss to encourage the model better separate the target-speaker's spectrogram from mixture. We obtain state-of-the-art target-speaker word error rate (TS-WER) on WSJ0-2mix-extr (4.2%). Further, we report for the first time TS-WER on WSJ0-3mix-extr (12.4%), LibriSpeech2Mix (4.2%) and LibriSpeech3Mix (7.6%) datasets, establishing new benchmarks for TS-ASR. The proposed model will be open-sourced through NVIDIA NeMo toolkit.
Speech Separation based on Contrastive Learning and Deep Modularization
May 18, 2023


The current monaural state of the art tools for speech separation relies on supervised learning. This means that they must deal with permutation problem, they are impacted by the mismatch on the number of speakers used in training and inference. Moreover, their performance heavily relies on the presence of high-quality labelled data. These problems can be effectively addressed by employing a fully unsupervised technique for speech separation. In this paper, we use contrastive learning to establish the representations of frames then use the learned representations in the downstream deep modularization task. Concretely, we demonstrate experimentally that in speech separation, different frames of a speaker can be viewed as augmentations of a given hidden standard frame of that speaker. The frames of a speaker contain enough prosodic information overlap which is key in speech separation. Based on this, we implement a self-supervised learning to learn to minimize the distance between frames belonging to a given speaker. The learned representations are used in a downstream deep modularization task to cluster frames based on speaker identity. Evaluation of the developed technique on WSJ0-2mix and WSJ0-3mix shows that the technique attains SI-SNRi and SDRi of 20.8 and 21.0 respectively in WSJ0-2mix. In WSJ0-3mix, it attains SI-SNRi and SDRi of 20.7 and 20.7 respectively in WSJ0-2mix. Its greatest strength being that as the number of speakers increase, its performance does not degrade significantly.
MossFormer: Pushing the Performance Limit of Monaural Speech Separation using Gated Single-Head Transformer with Convolution-Augmented Joint Self-Attentions
Feb 23, 2023



Transformer based models have provided significant performance improvements in monaural speech separation. However, there is still a performance gap compared to a recent proposed upper bound. The major limitation of the current dual-path Transformer models is the inefficient modelling of long-range elemental interactions and local feature patterns. In this work, we achieve the upper bound by proposing a gated single-head transformer architecture with convolution-augmented joint self-attentions, named \textit{MossFormer} (\textit{Mo}naural \textit{s}peech \textit{s}eparation Trans\textit{Former}). To effectively solve the indirect elemental interactions across chunks in the dual-path architecture, MossFormer employs a joint local and global self-attention architecture that simultaneously performs a full-computation self-attention on local chunks and a linearised low-cost self-attention over the full sequence. The joint attention enables MossFormer model full-sequence elemental interaction directly. In addition, we employ a powerful attentive gating mechanism with simplified single-head self-attentions. Besides the attentive long-range modelling, we also augment MossFormer with convolutions for the position-wise local pattern modelling. As a consequence, MossFormer significantly outperforms the previous models and achieves the state-of-the-art results on WSJ0-2/3mix and WHAM!/WHAMR! benchmarks. Our model achieves the SI-SDRi upper bound of 21.2 dB on WSJ0-3mix and only 0.3 dB below the upper bound of 23.1 dB on WSJ0-2mix.
Multi-Speaker ASR Combining Non-Autoregressive Conformer CTC and Conditional Speaker Chain
Jun 16, 2021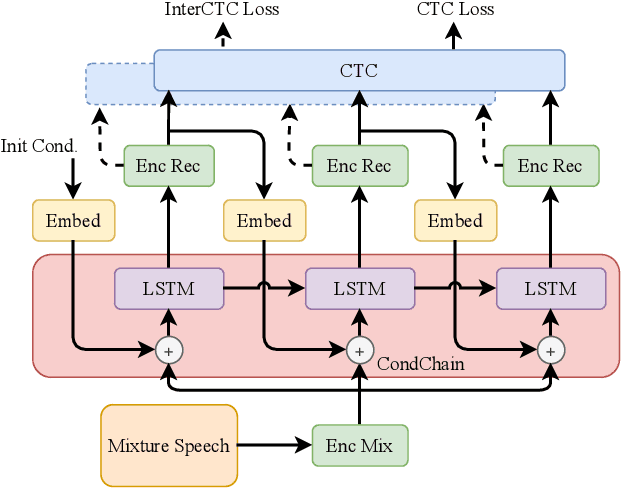



Non-autoregressive (NAR) models have achieved a large inference computation reduction and comparable results with autoregressive (AR) models on various sequence to sequence tasks. However, there has been limited research aiming to explore the NAR approaches on sequence to multi-sequence problems, like multi-speaker automatic speech recognition (ASR). In this study, we extend our proposed conditional chain model to NAR multi-speaker ASR. Specifically, the output of each speaker is inferred one-by-one using both the input mixture speech and previously-estimated conditional speaker features. In each step, a NAR connectionist temporal classification (CTC) encoder is used to perform parallel computation. With this design, the total inference steps will be restricted to the number of mixed speakers. Besides, we also adopt the Conformer and incorporate an intermediate CTC loss to improve the performance. Experiments on WSJ0-Mix and LibriMix corpora show that our model outperforms other NAR models with only a slight increase of latency, achieving WERs of 22.3% and 24.9%, respectively. Moreover, by including the data of variable numbers of speakers, our model can even better than the PIT-Conformer AR model with only 1/7 latency, obtaining WERs of 19.9% and 34.3% on WSJ0-2mix and WSJ0-3mix sets. All of our codes are publicly available at https://github.com/pengchengguo/espnet/tree/conditional-multispk.
Speaker and Direction Inferred Dual-channel Speech Separation
Feb 08, 2021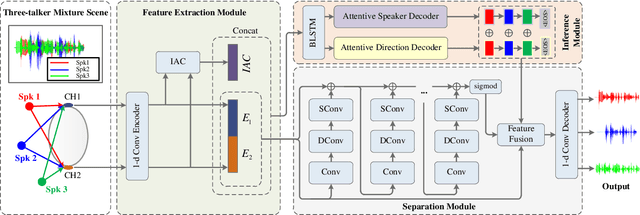
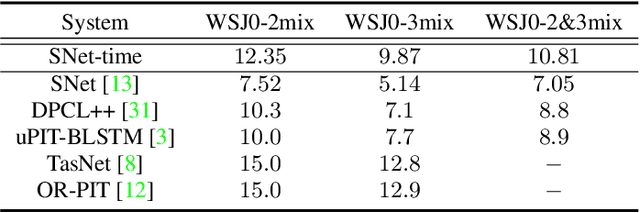
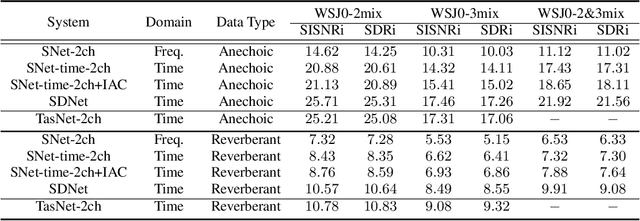
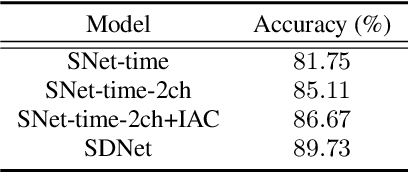
Most speech separation methods, trying to separate all channel sources simultaneously, are still far from having enough general- ization capabilities for real scenarios where the number of input sounds is usually uncertain and even dynamic. In this work, we employ ideas from auditory attention with two ears and propose a speaker and direction inferred speech separation network (dubbed SDNet) to solve the cocktail party problem. Specifically, our SDNet first parses out the respective perceptual representations with their speaker and direction characteristics from the mixture of the scene in a sequential manner. Then, the perceptual representations are utilized to attend to each corresponding speech. Our model gener- ates more precise perceptual representations with the help of spatial features and successfully deals with the problem of the unknown number of sources and the selection of outputs. The experiments on standard fully-overlapped speech separation benchmarks, WSJ0- 2mix, WSJ0-3mix, and WSJ0-2&3mix, show the effectiveness, and our method achieves SDR improvements of 25.31 dB, 17.26 dB, and 21.56 dB under anechoic settings. Our codes will be released at https://github.com/aispeech-lab/SDNet.
Sandglasset: A Light Multi-Granularity Self-attentive Network For Time-Domain Speech Separation
Mar 08, 2021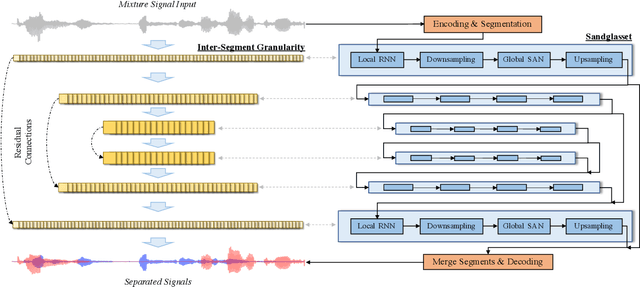
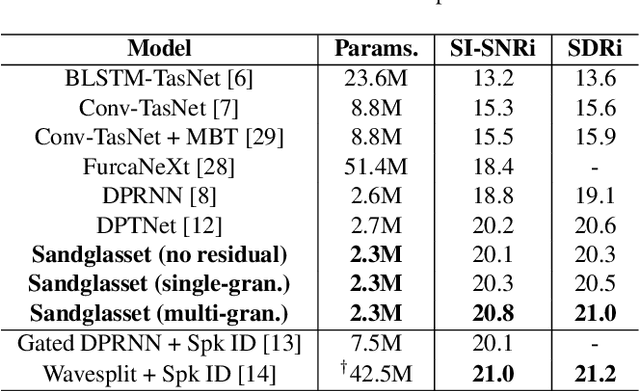
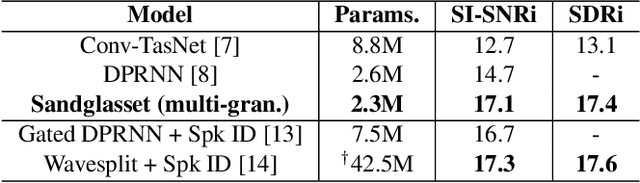
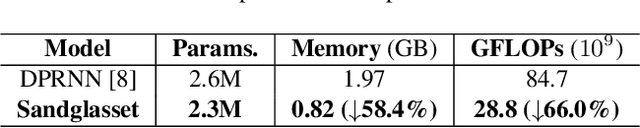
One of the leading single-channel speech separation (SS) models is based on a TasNet with a dual-path segmentation technique, where the size of each segment remains unchanged throughout all layers. In contrast, our key finding is that multi-granularity features are essential for enhancing contextual modeling and computational efficiency. We introduce a self-attentive network with a novel sandglass-shape, namely Sandglasset, which advances the state-of-the-art (SOTA) SS performance at significantly smaller model size and computational cost. Forward along each block inside Sandglasset, the temporal granularity of the features gradually becomes coarser until reaching half of the network blocks, and then successively turns finer towards the raw signal level. We also unfold that residual connections between features with the same granularity are critical for preserving information after passing through the bottleneck layer. Experiments show our Sandglasset with only 2.3M parameters has achieved the best results on two benchmark SS datasets -- WSJ0-2mix and WSJ0-3mix, where the SI-SNRi scores have been improved by absolute 0.8 dB and 2.4 dB, respectively, comparing to the prior SOTA results.
Attention is All You Need in Speech Separation
Oct 25, 2020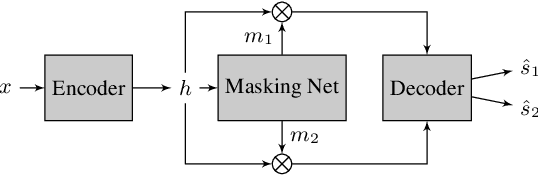
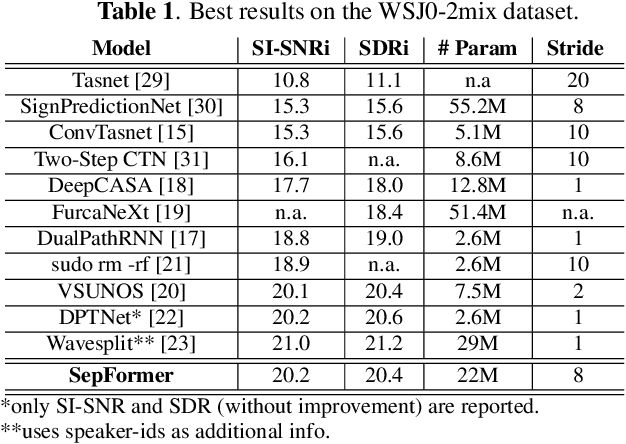
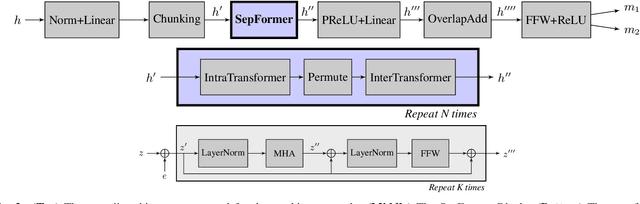
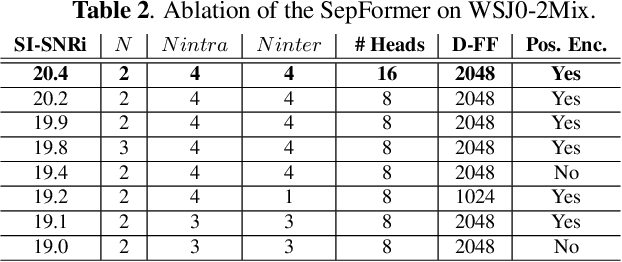
Recurrent Neural Networks (RNNs) have long been the dominant architecture in sequence-to-sequence learning. RNNs, however, are inherently sequential models that do not allow parallelization of their computations. Transformers are emerging as a natural alternative to standard RNNs, replacing recurrent computations with a multi-head attention mechanism. In this paper, we propose the `SepFormer', a novel RNN-free Transformer-based neural network for speech separation. The SepFormer learns short and long-term dependencies with a multi-scale approach that employs transformers. The proposed model matches or overtakes the state-of-the-art (SOTA) performance on the standard WSJ0-2/3mix datasets. It indeed achieves an SI-SNRi of 20.2 dB on WSJ0-2mix matching the SOTA, and an SI-SNRi of 17.6 dB on WSJ0-3mix, a SOTA result. The SepFormer inherits the parallelization advantages of Transformers and achieves a competitive performance even when downsampling the encoded representation by a factor of 8. It is thus significantly faster and it is less memory-demanding than the latest RNN-based systems.
Multi-talker ASR for an unknown number of sources: Joint training of source counting, separation and ASR
Jun 04, 2020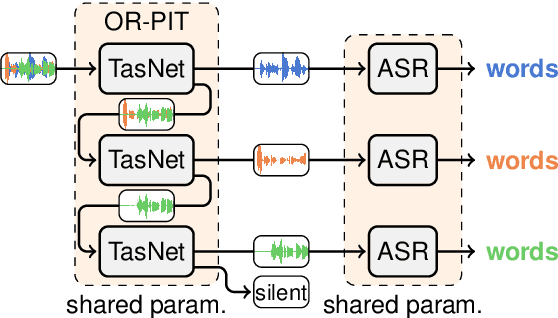
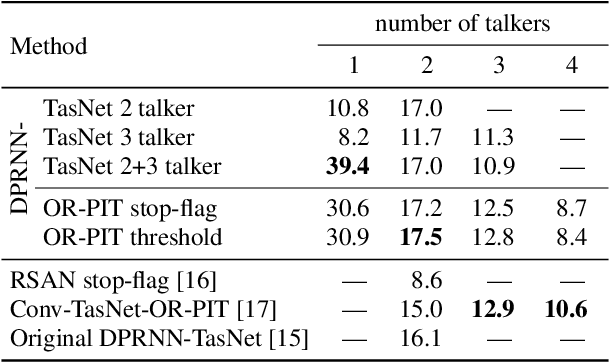
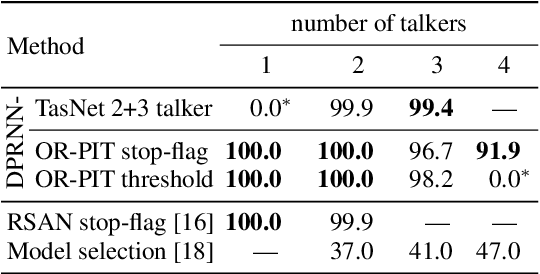
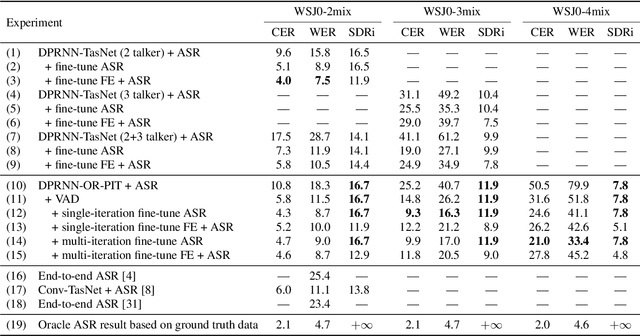
Most approaches to multi-talker overlapped speech separation and recognition assume that the number of simultaneously active speakers is given, but in realistic situations, it is typically unknown. To cope with this, we extend an iterative speech extraction system with mechanisms to count the number of sources and combine it with a single-talker speech recognizer to form the first end-to-end multi-talker automatic speech recognition system for an unknown number of active speakers. Our experiments show very promising performance in counting accuracy, source separation and speech recognition on simulated clean mixtures from WSJ0-2mix and WSJ0-3mix. Among others, we set a new state-of-the-art word error rate on the WSJ0-2mix database. Furthermore, our system generalizes well to a larger number of speakers than it ever saw during training, as shown in experiments with the WSJ0-4mix database.
Wavesplit: End-to-End Speech Separation by Speaker Clustering
Feb 20, 2020
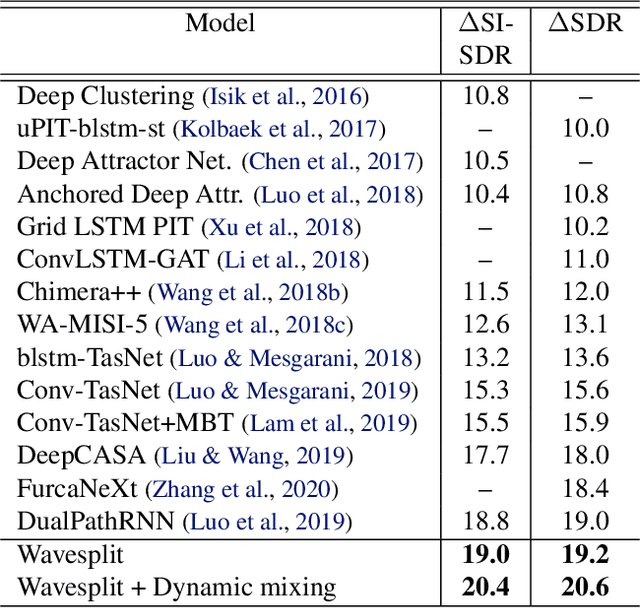
We introduce Wavesplit, an end-to-end speech separation system. From a single recording of mixed speech, the model infers and clusters representations of each speaker and then estimates each source signal conditioned on the inferred representations. The model is trained on the raw waveform to jointly perform the two tasks. Our model infers a set of speaker representations through clustering, which addresses the fundamental permutation problem of speech separation. Moreover, the sequence-wide speaker representations provide a more robust separation of long, challenging sequences, compared to previous approaches. We show that Wavesplit outperforms the previous state-of-the-art on clean mixtures of 2 or 3 speakers (WSJ0-2mix, WSJ0-3mix), as well as in noisy (WHAM!) and reverberated (WHAMR!) conditions. As an additional contribution, we further improve our model by introducing online data augmentation for separation.