 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePromptformer: Prompted Conformer Transducer for ASR
Jan 14, 2024



Context cues carry information which can improve multi-turn interactions in automatic speech recognition (ASR) systems. In this paper, we introduce a novel mechanism inspired by hyper-prompting to fuse textual context with acoustic representations in the attention mechanism. Results on a test set with multi-turn interactions show that our method achieves 5.9% relative word error rate reduction (rWERR) over a strong baseline. We show that our method does not degrade in the absence of context and leads to improvements even if the model is trained without context. We further show that leveraging a pre-trained sentence-piece model for context embedding generation can outperform an external BERT model.
Multi-View Frequency-Attention Alternative to CNN Frontends for Automatic Speech Recognition
Jun 12, 2023



Convolutional frontends are a typical choice for Transformer-based automatic speech recognition to preprocess the spectrogram, reduce its sequence length, and combine local information in time and frequency similarly. However, the width and height of an audio spectrogram denote different information, e.g., due to reverberation as well as the articulatory system, the time axis has a clear left-to-right dependency. On the contrary, vowels and consonants demonstrate very different patterns and occupy almost disjoint frequency ranges. Therefore, we hypothesize, global attention over frequencies is beneficial over local convolution. We obtain 2.4 % relative word error rate reduction (rWERR) on a production scale Conformer transducer replacing its convolutional neural network frontend by the proposed F-Attention module on Alexa traffic. To demonstrate generalizability, we validate this on public LibriSpeech data with a long short term memory-based listen attend and spell architecture obtaining 4.6 % rWERR and demonstrate robustness to (simulated) noisy conditions.
Contextual-Utterance Training for Automatic Speech Recognition
Oct 27, 2022



Recent studies of streaming automatic speech recognition (ASR) recurrent neural network transducer (RNN-T)-based systems have fed the encoder with past contextual information in order to improve its word error rate (WER) performance. In this paper, we first propose a contextual-utterance training technique which makes use of the previous and future contextual utterances in order to do an implicit adaptation to the speaker, topic and acoustic environment. Also, we propose a dual-mode contextual-utterance training technique for streaming automatic speech recognition (ASR) systems. This proposed approach allows to make a better use of the available acoustic context in streaming models by distilling "in-place" the knowledge of a teacher, which is able to see both past and future contextual utterances, to the student which can only see the current and past contextual utterances. The experimental results show that a conformer-transducer system trained with the proposed techniques outperforms the same system trained with the classical RNN-T loss. Specifically, the proposed technique is able to reduce both the WER and the average last token emission latency by more than 6% and 40ms relative, respectively.
Multi-channel Opus compression for far-field automatic speech recognition with a fixed bitrate budget
Jun 15, 2021

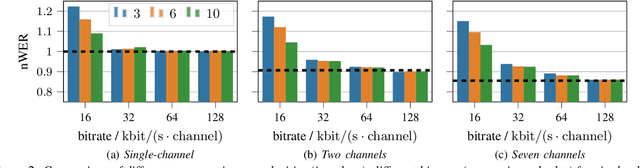
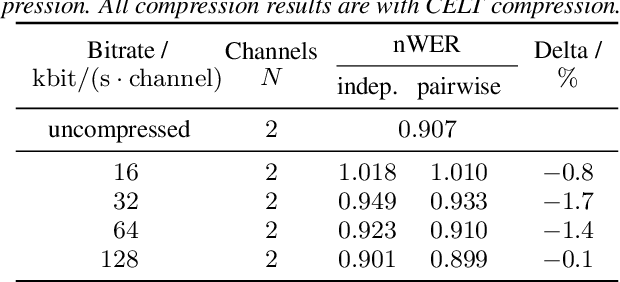
Automatic speech recognition (ASR) in the cloud allows the use of larger models and more powerful multi-channel signal processing front-ends compared to on-device processing. However, it also adds an inherent latency due to the transmission of the audio signal, especially when transmitting multiple channels of a microphone array. One way to reduce the network bandwidth requirements is client-side compression with a lossy codec such as Opus. However, this compression can have a detrimental effect especially on multi-channel ASR front-ends, due to the distortion and loss of spatial information introduced by the codec. In this publication, we propose an improved approach for the compression of microphone array signals based on Opus, using a modified joint channel coding approach and additionally introducing a multi-channel spatial decorrelating transform to reduce redundancy in the transmission. We illustrate the effect of the proposed approach on the spatial information retained in multi-channel signals after compression, and evaluate the performance on far-field ASR with a multi-channel beamforming front-end. We demonstrate that our approach can lead to a 37.5 % bitrate reduction or a 5.1 % relative word error rate reduction for a fixed bitrate budget in a seven channel setup.
Multi-talker ASR for an unknown number of sources: Joint training of source counting, separation and ASR
Jun 04, 2020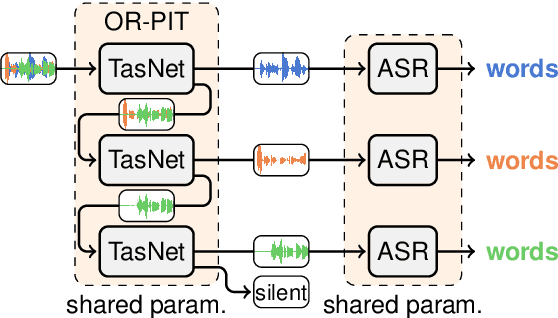
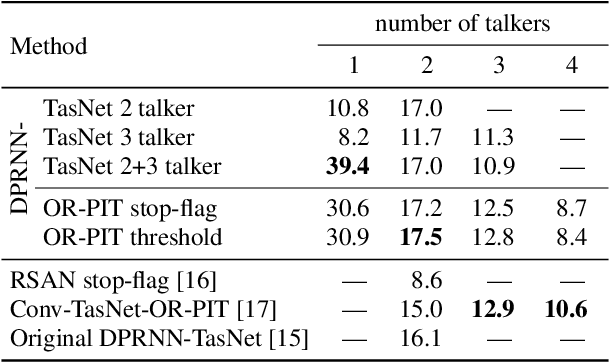
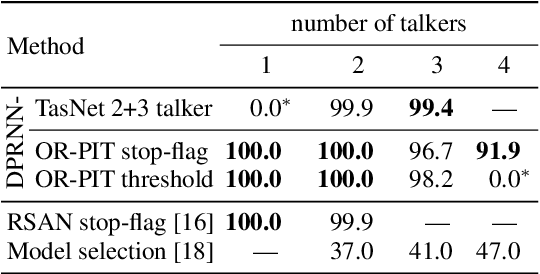
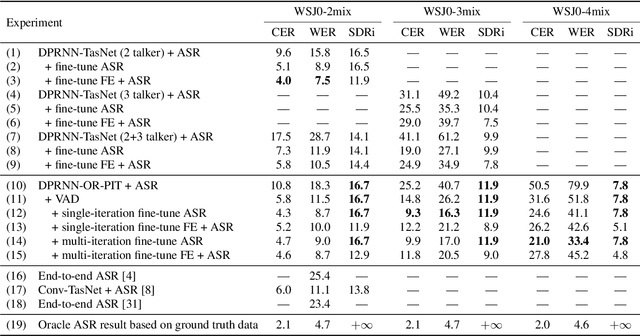
Most approaches to multi-talker overlapped speech separation and recognition assume that the number of simultaneously active speakers is given, but in realistic situations, it is typically unknown. To cope with this, we extend an iterative speech extraction system with mechanisms to count the number of sources and combine it with a single-talker speech recognizer to form the first end-to-end multi-talker automatic speech recognition system for an unknown number of active speakers. Our experiments show very promising performance in counting accuracy, source separation and speech recognition on simulated clean mixtures from WSJ0-2mix and WSJ0-3mix. Among others, we set a new state-of-the-art word error rate on the WSJ0-2mix database. Furthermore, our system generalizes well to a larger number of speakers than it ever saw during training, as shown in experiments with the WSJ0-4mix database.
End-to-end training of time domain audio separation and recognition
Dec 25, 2019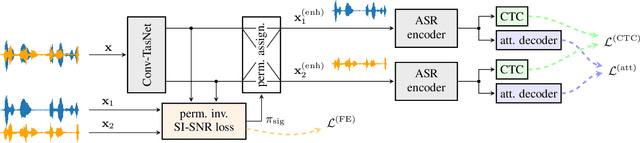


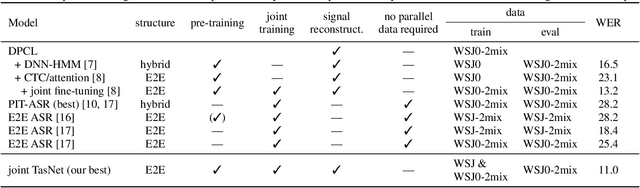
The rising interest in single-channel multi-speaker speech separation sparked development of End-to-End (E2E) approaches to multi-speaker speech recognition. However, up until now, state-of-the-art neural network-based time domain source separation has not yet been combined with E2E speech recognition. We here demonstrate how to combine a separation module based on a Convolutional Time domain Audio Separation Network (Conv-TasNet) with an E2E speech recognizer and how to train such a model jointly by distributing it over multiple GPUs or by approximating truncated back-propagation for the convolutional front-end. To put this work into perspective and illustrate the complexity of the design space, we provide a compact overview of single-channel multi-speaker recognition systems. Our experiments show a word error rate of 11.0% on WSJ0-2mix and indicate that our joint time domain model can yield substantial improvements over cascade DNN-HMM and monolithic E2E frequency domain systems proposed so far.
Demystifying TasNet: A Dissecting Approach
Nov 20, 2019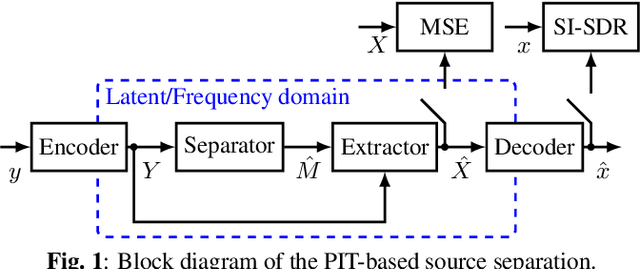
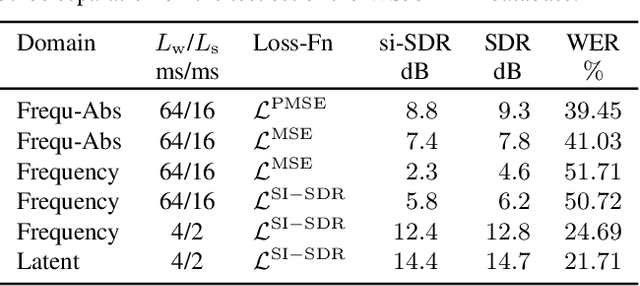
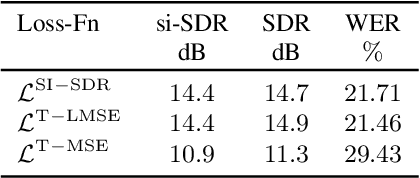
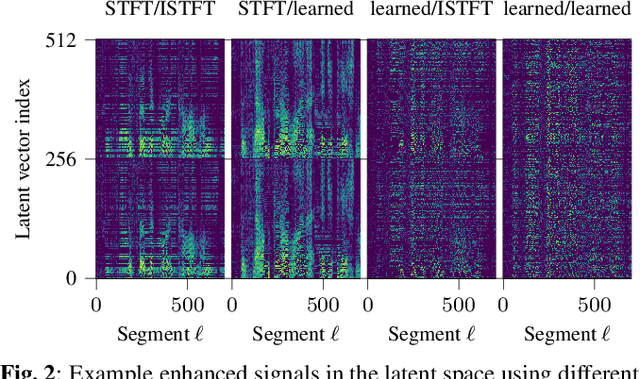
In recent years time domain speech separation has excelled over frequency domain separation in single channel scenarios and noise-free environments. In this paper we dissect the gains of the time-domain audio separation network (TasNet) approach by gradually replacing components of an utterance-level permutation invariant training (u-PIT) based separation system in the frequency domain until the TasNet system is reached, thus blending components of frequency domain approaches with those of time domain approaches. Some of the intermediate variants achieve comparable signal-to-distortion ratio (SDR) gains to TasNet, but retain the advantage of frequency domain processing: compatibility with classic signal processing tools such as frequency-domain beamforming and the human interpretability of the masks. Furthermore, we show that the scale invariant signal-to-distortion ratio (si-SDR) criterion used as loss function in TasNet is related to a logarithmic mean square error criterion and that it is this criterion which contributes most reliable to the performance advantage of TasNet. Finally, we critically assess which gains in a noise-free single channel environment generalize to more realistic reverberant conditions.
SMS-WSJ: Database, performance measures, and baseline recipe for multi-channel source separation and recognition
Oct 30, 2019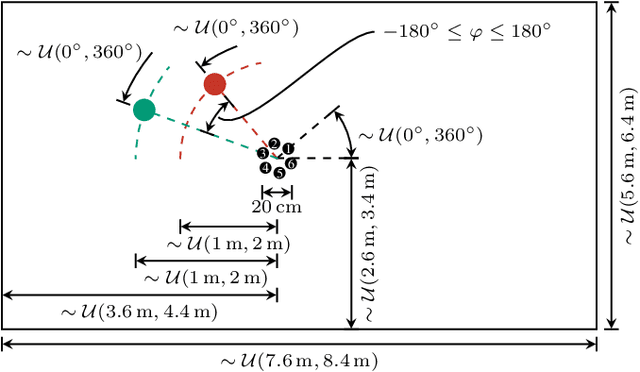
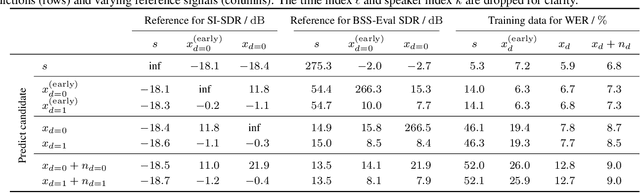
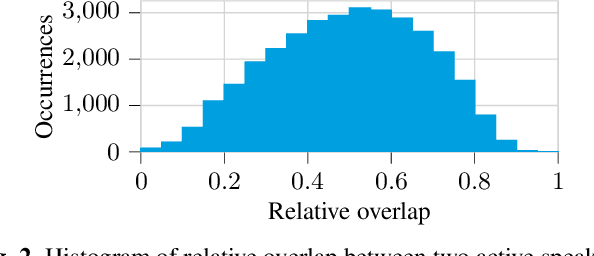
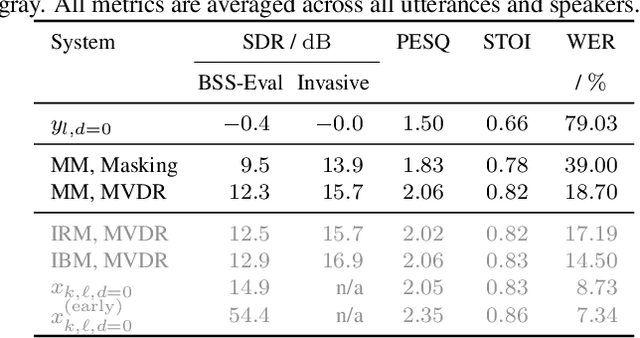
We present a multi-channel database of overlapping speech for training, evaluation, and detailed analysis of source separation and extraction algorithms: SMS-WSJ -- Spatialized Multi-Speaker Wall Street Journal. It consists of artificially mixed speech taken from the WSJ database, but unlike earlier databases we consider all WSJ0+1 utterances and take care of strictly separating the speaker sets present in the training, validation and test sets. When spatializing the data we ensure a high degree of randomness w.r.t. room size, array center and rotation, as well as speaker position. Furthermore, this paper offers a critical assessment of recently proposed measures of source separation performance. Alongside the code to generate the database we provide a source separation baseline and a Kaldi recipe with competitive word error rates to provide common ground for evaluation.
Unsupervised training of neural mask-based beamforming
Apr 08, 2019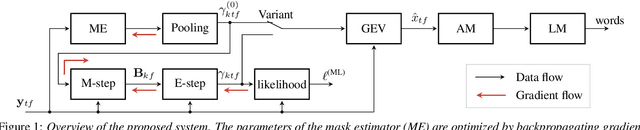
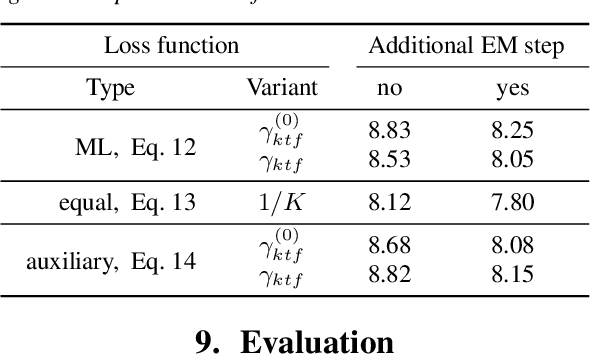
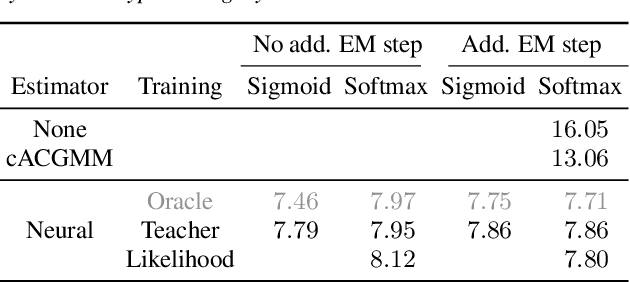
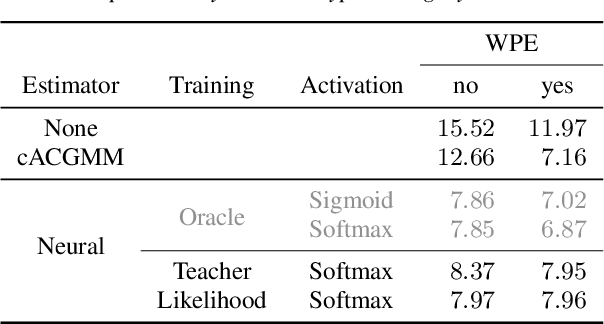
We present an unsupervised training approach for a neural network-based mask estimator in an acoustic beamforming application. The network is trained to maximize a likelihood criterion derived from a spatial mixture model of the observations. It is trained from scratch without requiring any parallel data consisting of degraded input and clean training targets. Thus, training can be carried out on real recordings of noisy speech rather than simulated ones. In contrast to previous work on unsupervised training of neural mask estimators, our approach avoids the need for a possibly pre-trained teacher model entirely. We demonstrate the effectiveness of our approach by speech recognition experiments on two different datasets: one mainly deteriorated by noise (CHiME 4) and one by reverberation (REVERB). The results show that the performance of the proposed system is on par with a supervised system using oracle target masks for training and with a system trained using a model-based teacher.
Unsupervised training of a deep clustering model for multichannel blind source separation
Apr 02, 2019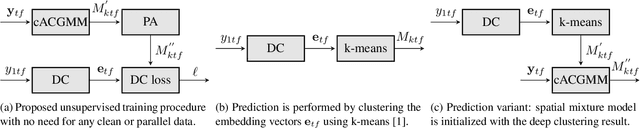
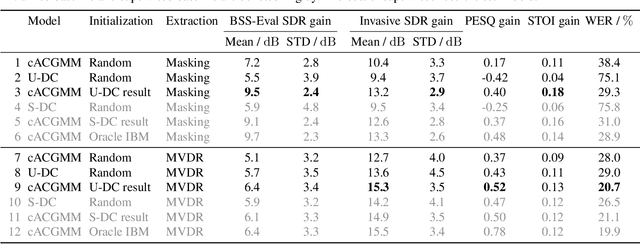
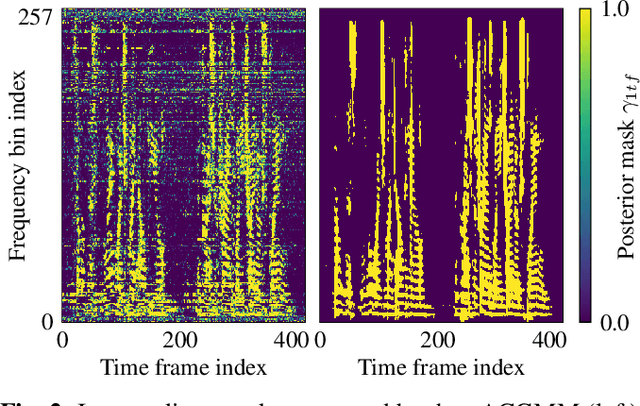
We propose a training scheme to train neural network-based source separation algorithms from scratch when parallel clean data is unavailable. In particular, we demonstrate that an unsupervised spatial clustering algorithm is sufficient to guide the training of a deep clustering system. We argue that previous work on deep clustering requires strong supervision and elaborate on why this is a limitation. We demonstrate that (a) the single-channel deep clustering system trained according to the proposed scheme alone is able to achieve a similar performance as the multi-channel teacher in terms of word error rates and (b) initializing the spatial clustering approach with the deep clustering result yields a relative word error rate reduction of 26 % over the unsupervised teacher.