 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Odometry
Papers and Code
Feature points evaluation on omnidirectional vision with a photorealistic fisheye sequence -- A report on experiments done in 2014
Feb 05, 2026What is this report: This is a scientific report, contributing with a detailed bibliography, a dataset which we will call now PFSeq for ''Photorealistic Fisheye Sequence'' and make available at https://doi.org/10. 57745/DYIVVU, and comprehensive experiments. This work should be considered as a draft, and has been done during my PhD thesis ''Construction of 3D models from fisheye video data-Application to the localisation in urban area'' in 2014 [Mor16]. These results have never been published. The aim was to find the best features detector and descriptor for fisheye images, in the context of selfcalibration, with cameras mounted on the top of a car and aiming at the zenith (to proceed then fisheye visual odometry and stereovision in urban scenes). We face a chicken and egg problem, because we can not take advantage of an accurate projection model for an optimal features detection and description, and we rightly need good features to perform the calibration (i.e. to compute the accurate projection model of the camera). What is not this report: It does not contribute with new features algorithm. It does not compare standard features algorithms to algorithms designed for omnidirectional images (unfortunately). It has not been peer-reviewed. Discussions have been translated and enhanced but the experiments have not been run again and the report has not been updated accordingly to the evolution of the state-of-the-art (read this as a 2014 report).
LEVIO: Lightweight Embedded Visual Inertial Odometry for Resource-Constrained Devices
Feb 03, 2026Accurate, infrastructure-less sensor systems for motion tracking are essential for mobile robotics and augmented reality (AR) applications. The most popular state-of-the-art visual-inertial odometry (VIO) systems, however, are too computationally demanding for resource-constrained hardware, such as micro-drones and smart glasses. This work presents LEVIO, a fully featured VIO pipeline optimized for ultra-low-power compute platforms, allowing six-degrees-of-freedom (DoF) real-time sensing. LEVIO incorporates established VIO components such as Oriented FAST and Rotated BRIEF (ORB) feature tracking and bundle adjustment, while emphasizing a computationally efficient architecture with parallelization and low memory usage to suit embedded microcontrollers and low-power systems-on-chip (SoCs). The paper proposes and details the algorithmic design choices and the hardware-software co-optimization approach, and presents real-time performance on resource-constrained hardware. LEVIO is validated on a parallel-processing ultra-low-power RISC-V SoC, achieving 20 FPS while consuming less than 100 mW, and benchmarked against public VIO datasets, offering a compelling balance between efficiency and accuracy. To facilitate reproducibility and adoption, the complete implementation is released as open-source.
* This article has been accepted for publication in the IEEE Sensors Journal (JSEN)
Vision-only UAV State Estimation for Fast Flights Without External Localization Systems: A2RL Drone Racing Finalist Approach
Feb 02, 2026Fast flights with aggressive maneuvers in cluttered GNSS-denied environments require fast, reliable, and accurate UAV state estimation. In this paper, we present an approach for onboard state estimation of a high-speed UAV using a monocular RGB camera and an IMU. Our approach fuses data from Visual-Inertial Odometry (VIO), an onboard landmark-based camera measurement system, and an IMU to produce an accurate state estimate. Using onboard measurement data, we estimate and compensate for VIO drift through a novel mathematical drift model. State-of-the-art approaches often rely on more complex hardware (e.g., stereo cameras or rangefinders) and use uncorrected drifting VIO velocities, orientation, and angular rates, leading to errors during fast maneuvers. In contrast, our method corrects all VIO states (position, orientation, linear and angular velocity), resulting in accurate state estimation even during rapid and dynamic motion. Our approach was thoroughly validated through 1600 simulations and numerous real-world experiments. Furthermore, we applied the proposed method in the A2RL Drone Racing Challenge 2025, where our team advanced to the final four out of 210 teams and earned a medal.
Keyframe-Based Feed-Forward Visual Odometry
Jan 22, 2026The emergence of visual foundation models has revolutionized visual odometry~(VO) and SLAM, enabling pose estimation and dense reconstruction within a single feed-forward network. However, unlike traditional pipelines that leverage keyframe methods to enhance efficiency and accuracy, current foundation model based methods, such as VGGT-Long, typically process raw image sequences indiscriminately. This leads to computational redundancy and degraded performance caused by low inter-frame parallax, which provides limited contextual stereo information. Integrating traditional geometric heuristics into these methods is non-trivial, as their performance depends on high-dimensional latent representations rather than explicit geometric metrics. To bridge this gap, we propose a novel keyframe-based feed-forward VO. Instead of relying on hand-crafted rules, our approach employs reinforcement learning to derive an adaptive keyframe policy in a data-driven manner, aligning selection with the intrinsic characteristics of the underlying foundation model. We train our agent on TartanAir dataset and conduct extensive evaluations across several real-world datasets. Experimental results demonstrate that the proposed method achieves consistent and substantial improvements over state-of-the-art feed-forward VO methods.
360DVO: Deep Visual Odometry for Monocular 360-Degree Camera
Jan 05, 2026Monocular omnidirectional visual odometry (OVO) systems leverage 360-degree cameras to overcome field-of-view limitations of perspective VO systems. However, existing methods, reliant on handcrafted features or photometric objectives, often lack robustness in challenging scenarios, such as aggressive motion and varying illumination. To address this, we present 360DVO, the first deep learning-based OVO framework. Our approach introduces a distortion-aware spherical feature extractor (DAS-Feat) that adaptively learns distortion-resistant features from 360-degree images. These sparse feature patches are then used to establish constraints for effective pose estimation within a novel omnidirectional differentiable bundle adjustment (ODBA) module. To facilitate evaluation in realistic settings, we also contribute a new real-world OVO benchmark. Extensive experiments on this benchmark and public synthetic datasets (TartanAir V2 and 360VO) demonstrate that 360DVO surpasses state-of-the-art baselines (including 360VO and OpenVSLAM), improving robustness by 50% and accuracy by 37.5%. Homepage: https://chris1004336379.github.io/360DVO-homepage
DefVINS: Visual-Inertial Odometry for Deformable Scenes
Jan 02, 2026Deformable scenes violate the rigidity assumptions underpinning classical visual-inertial odometry (VIO), often leading to over-fitting to local non-rigid motion or severe drift when deformation dominates visual parallax. We introduce DefVINS, a visual-inertial odometry framework that explicitly separates a rigid, IMU-anchored state from a non--rigid warp represented by an embedded deformation graph. The system is initialized using a standard VIO procedure that fixes gravity, velocity, and IMU biases, after which non-rigid degrees of freedom are activated progressively as the estimation becomes well conditioned. An observability analysis is included to characterize how inertial measurements constrain the rigid motion and render otherwise unobservable modes identifiable in the presence of deformation. This analysis motivates the use of IMU anchoring and informs a conditioning-based activation strategy that prevents ill-posed updates under poor excitation. Ablation studies demonstrate the benefits of combining inertial constraints with observability-aware deformation activation, resulting in improved robustness under non-rigid environments.
InsSo3D: Inertial Navigation System and 3D Sonar SLAM for turbid environment inspection
Jan 09, 2026This paper presents InsSo3D, an accurate and efficient method for large-scale 3D Simultaneous Localisation and Mapping (SLAM) using a 3D Sonar and an Inertial Navigation System (INS). Unlike traditional sonar, which produces 2D images containing range and azimuth information but lacks elevation information, 3D Sonar produces a 3D point cloud, which therefore does not suffer from elevation ambiguity. We introduce a robust and modern SLAM framework adapted to the 3D Sonar data using INS as prior, detecting loop closure and performing pose graph optimisation. We evaluated InsSo3D performance inside a test tank with access to ground truth data and in an outdoor flooded quarry. Comparisons to reference trajectories and maps obtained from an underwater motion tracking system and visual Structure From Motion (SFM) demonstrate that InsSo3D efficiently corrects odometry drift. The average trajectory error is below 21cm during a 50-minute-long mission, producing a map of 10m by 20m with a 9cm average reconstruction error, enabling safe inspection of natural or artificial underwater structures even in murky water conditions.
AME-2: Agile and Generalized Legged Locomotion via Attention-Based Neural Map Encoding
Jan 13, 2026Achieving agile and generalized legged locomotion across terrains requires tight integration of perception and control, especially under occlusions and sparse footholds. Existing methods have demonstrated agility on parkour courses but often rely on end-to-end sensorimotor models with limited generalization and interpretability. By contrast, methods targeting generalized locomotion typically exhibit limited agility and struggle with visual occlusions. We introduce AME-2, a unified reinforcement learning (RL) framework for agile and generalized locomotion that incorporates a novel attention-based map encoder in the control policy. This encoder extracts local and global mapping features and uses attention mechanisms to focus on salient regions, producing an interpretable and generalized embedding for RL-based control. We further propose a learning-based mapping pipeline that provides fast, uncertainty-aware terrain representations robust to noise and occlusions, serving as policy inputs. It uses neural networks to convert depth observations into local elevations with uncertainties, and fuses them with odometry. The pipeline also integrates with parallel simulation so that we can train controllers with online mapping, aiding sim-to-real transfer. We validate AME-2 with the proposed mapping pipeline on a quadruped and a biped robot, and the resulting controllers demonstrate strong agility and generalization to unseen terrains in simulation and in real-world experiments.
Differential Barometric Altimetry for Submeter Vertical Localization and Floor Recognition Indoors
Jan 05, 2026Accurate altitude estimation and reliable floor recognition are critical for mobile robot localization and navigation within complex multi-storey environments. In this paper, we present a robust, low-cost vertical estimation framework leveraging differential barometric sensing integrated within a fully ROS-compliant software package. Our system simultaneously publishes real-time altitude data from both a stationary base station and a mobile sensor, enabling precise and drift-free vertical localization. Empirical evaluations conducted in challenging scenarios -- such as fully enclosed stairwells and elevators, demonstrate that our proposed barometric pipeline achieves sub-meter vertical accuracy (RMSE: 0.29 m) and perfect (100%) floor-level identification. In contrast, our results confirm that standalone height estimates, obtained solely from visual- or LiDAR-based SLAM odometry, are insufficient for reliable vertical localization. The proposed ROS-compatible barometric module thus provides a practical and cost-effective solution for robust vertical awareness in real-world robotic deployments. The implementation of our method is released as open source at https://github.com/witsir/differential-barometric.
FAR-AVIO: Fast and Robust Schur-Complement Based Acoustic-Visual-Inertial Fusion Odometry with Sensor Calibration
Dec 23, 2025
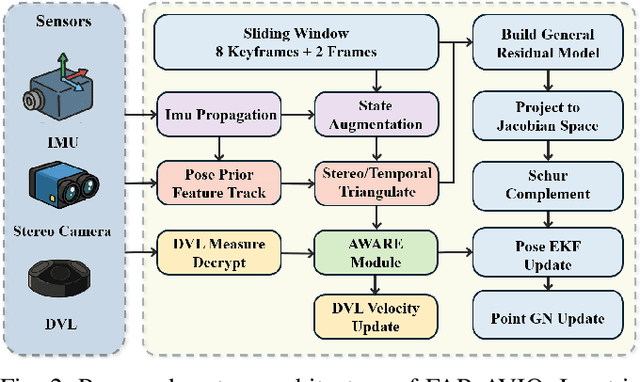
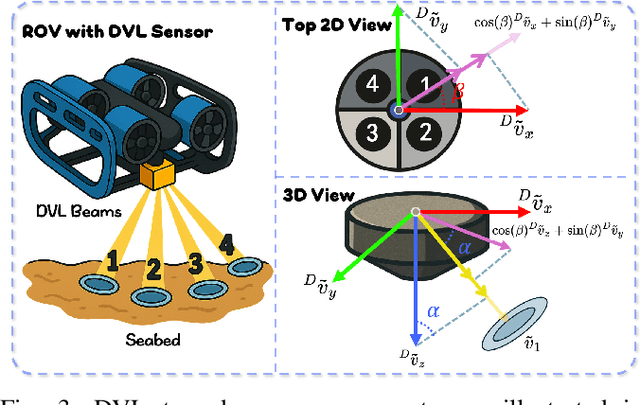
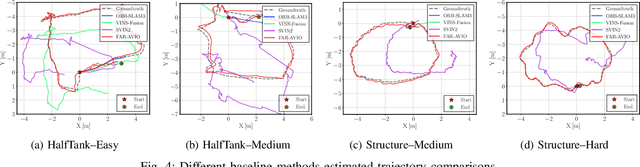
Underwater environments impose severe challenges to visual-inertial odometry systems, as strong light attenuation, marine snow and turbidity, together with weakly exciting motions, degrade inertial observability and cause frequent tracking failures over long-term operation. While tightly coupled acoustic-visual-inertial fusion, typically implemented through an acoustic Doppler Velocity Log (DVL) integrated with visual-inertial measurements, can provide accurate state estimation, the associated graph-based optimization is often computationally prohibitive for real-time deployment on resource-constrained platforms. Here we present FAR-AVIO, a Schur-Complement based, tightly coupled acoustic-visual-inertial odometry framework tailored for underwater robots. FAR-AVIO embeds a Schur complement formulation into an Extended Kalman Filter(EKF), enabling joint pose-landmark optimization for accuracy while maintaining constant-time updates by efficiently marginalizing landmark states. On top of this backbone, we introduce Adaptive Weight Adjustment and Reliability Evaluation(AWARE), an online sensor health module that continuously assesses the reliability of visual, inertial and DVL measurements and adaptively regulates their sigma weights, and we develop an efficient online calibration scheme that jointly estimates DVL-IMU extrinsics, without dedicated calibration manoeuvres. Numerical simulations and real-world underwater experiments consistently show that FAR-AVIO outperforms state-of-the-art underwater SLAM baselines in both localization accuracy and computational efficiency, enabling robust operation on low-power embedded platforms. Our implementation has been released as open source software at https://far-vido.gitbook.io/far-vido-docs.