 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Keyword Spotting
Papers and Code
VE-KWS: Visual Modality Enhanced End-to-End Keyword Spotting
Mar 14, 2023



The performance of the keyword spotting (KWS) system based on audio modality, commonly measured in false alarms and false rejects, degrades significantly under the far field and noisy conditions. Therefore, audio-visual keyword spotting, which leverages complementary relationships over multiple modalities, has recently gained much attention. However, current studies mainly focus on combining the exclusively learned representations of different modalities, instead of exploring the modal relationships during each respective modeling. In this paper, we propose a novel visual modality enhanced end-to-end KWS framework (VE-KWS), which fuses audio and visual modalities from two aspects. The first one is utilizing the speaker location information obtained from the lip region in videos to assist the training of multi-channel audio beamformer. By involving the beamformer as an audio enhancement module, the acoustic distortions, caused by the far field or noisy environments, could be significantly suppressed. The other one is conducting cross-attention between different modalities to capture the inter-modal relationships and help the representation learning of each modality. Experiments on the MSIP challenge corpus show that our proposed model achieves 2.79% false rejection rate and 2.95% false alarm rate on the Eval set, resulting in a new SOTA performance compared with the top-ranking systems in the ICASSP2022 MISP challenge.
LipLearner: Customizable Silent Speech Interactions on Mobile Devices
Feb 14, 2023


Silent speech interface is a promising technology that enables private communications in natural language. However, previous approaches only support a small and inflexible vocabulary, which leads to limited expressiveness. We leverage contrastive learning to learn efficient lipreading representations, enabling few-shot command customization with minimal user effort. Our model exhibits high robustness to different lighting, posture, and gesture conditions on an in-the-wild dataset. For 25-command classification, an F1-score of 0.8947 is achievable only using one shot, and its performance can be further boosted by adaptively learning from more data. This generalizability allowed us to develop a mobile silent speech interface empowered with on-device fine-tuning and visual keyword spotting. A user study demonstrated that with LipLearner, users could define their own commands with high reliability guaranteed by an online incremental learning scheme. Subjective feedback indicated that our system provides essential functionalities for customizable silent speech interactions with high usability and learnability.
Visual Keyword Spotting with Attention
Oct 29, 2021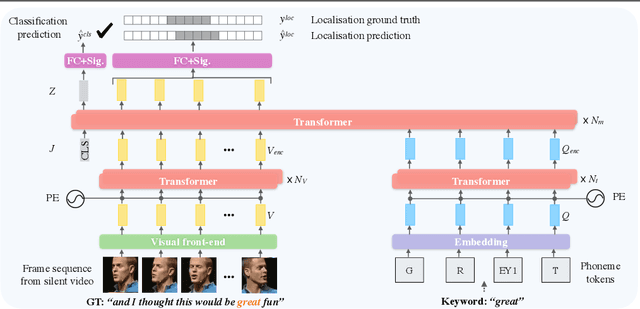
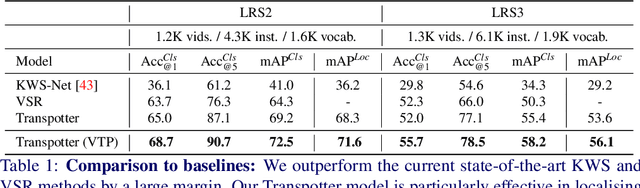

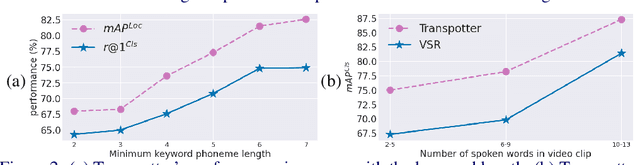
In this paper, we consider the task of spotting spoken keywords in silent video sequences -- also known as visual keyword spotting. To this end, we investigate Transformer-based models that ingest two streams, a visual encoding of the video and a phonetic encoding of the keyword, and output the temporal location of the keyword if present. Our contributions are as follows: (1) We propose a novel architecture, the Transpotter, that uses full cross-modal attention between the visual and phonetic streams; (2) We show through extensive evaluations that our model outperforms the prior state-of-the-art visual keyword spotting and lip reading methods on the challenging LRW, LRS2, LRS3 datasets by a large margin; (3) We demonstrate the ability of our model to spot words under the extreme conditions of isolated mouthings in sign language videos.
T-RECX: Tiny-Resource Efficient Convolutional Neural Networks with Early-Exit
Jul 14, 2022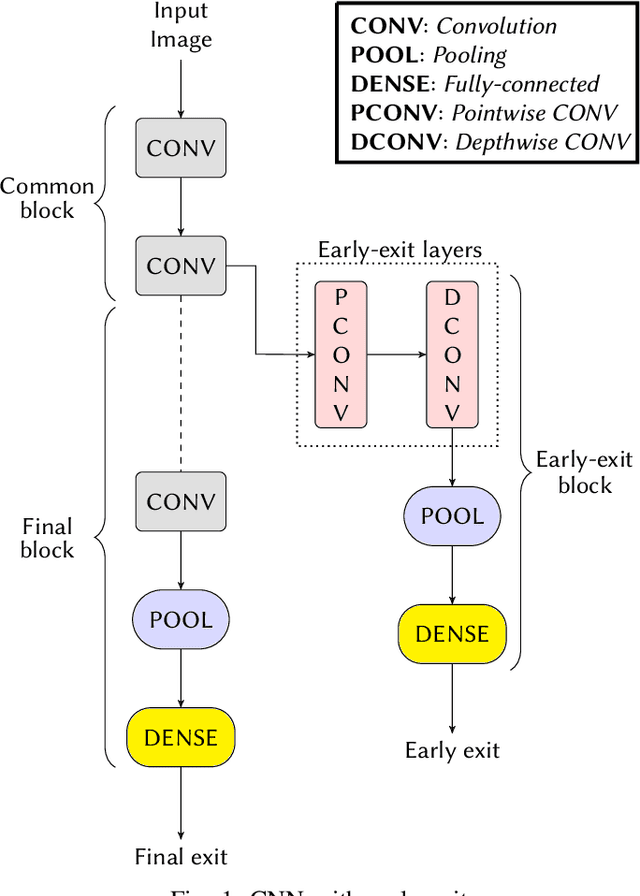
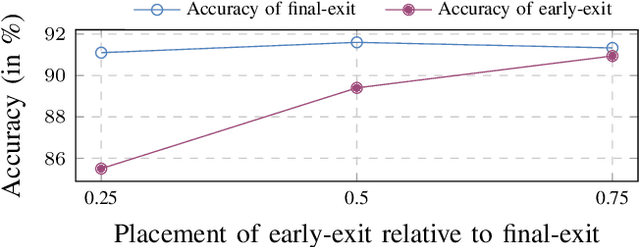
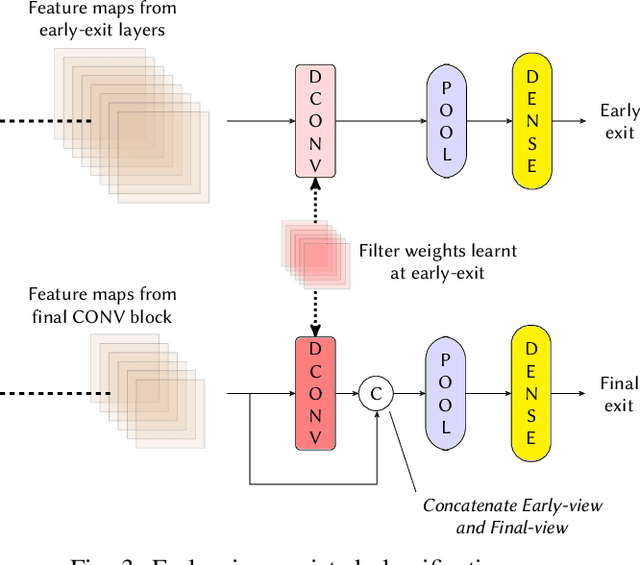
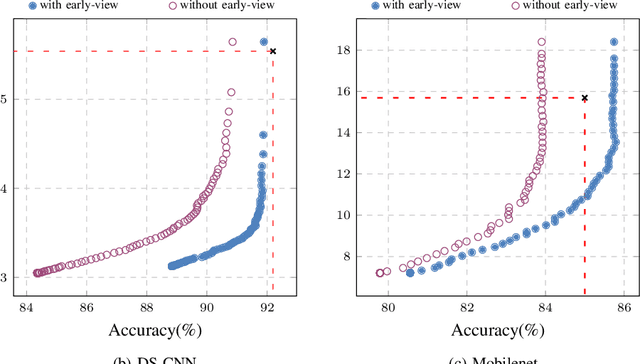
Deploying Machine learning (ML) on the milliwatt-scale edge devices (tinyML) is gaining popularity due to recent breakthroughs in ML and IoT. However, the capabilities of tinyML are restricted by strict power and compute constraints. The majority of the contemporary research in tinyML focuses on model compression techniques such as model pruning and quantization to fit ML models on low-end devices. Nevertheless, the improvements in energy consumption and inference time obtained by existing techniques are limited because aggressive compression quickly shrinks model capacity and accuracy. Another approach to improve inference time and/or reduce power while preserving its model capacity is through early-exit networks. These networks place intermediate classifiers along a baseline neural network that facilitate early exit from neural network computation if an intermediate classifier exhibits sufficient confidence in its prediction. Previous work on early-exit networks have focused on large networks, beyond what would typically be used for tinyML applications. In this paper, we discuss the challenges of adding early-exits to state-of-the-art tiny-CNNs and devise an early-exit architecture, T-RECX, that addresses these challenges. In addition, we develop a method to alleviate the effect of network overthinking at the final exit by leveraging the high-level representations learned by the early-exit. We evaluate T-RECX on three CNNs from the MLPerf tiny benchmark suite for image classification, keyword spotting and visual wake word detection tasks. Our results demonstrate that T-RECX improves the accuracy of baseline network and significantly reduces the average inference time of tiny-CNNs. T-RECX achieves 32.58% average reduction in FLOPS in exchange for 1% accuracy across all evaluated models. Also, our techniques increase the accuracy of baseline network in two out of three models we evaluate
Depth Pruning with Auxiliary Networks for TinyML
Apr 22, 2022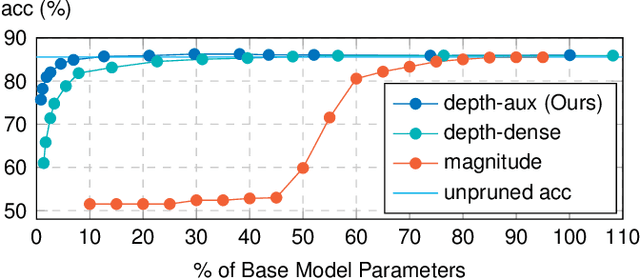

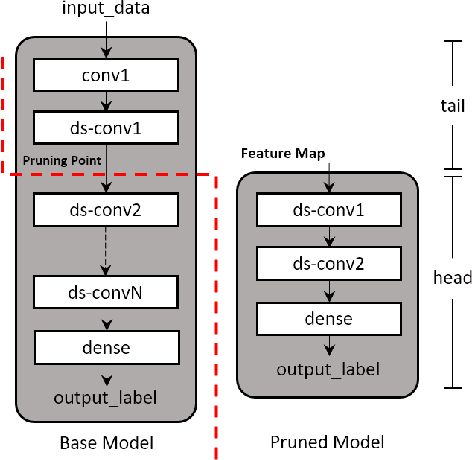

Pruning is a neural network optimization technique that sacrifices accuracy in exchange for lower computational requirements. Pruning has been useful when working with extremely constrained environments in tinyML. Unfortunately, special hardware requirements and limited study on its effectiveness on already compact models prevent its wider adoption. Depth pruning is a form of pruning that requires no specialized hardware but suffers from a large accuracy falloff. To improve this, we propose a modification that utilizes a highly efficient auxiliary network as an effective interpreter of intermediate feature maps. Our results show a parameter reduction of 93% on the MLPerfTiny Visual Wakewords (VWW) task and 28% on the Keyword Spotting (KWS) task with accuracy cost of 0.65% and 1.06% respectively. When evaluated on a Cortex-M0 microcontroller, our proposed method reduces the VWW model size by 4.7x and latency by 1.6x while counter intuitively gaining 1% accuracy. KWS model size on Cortex-M0 was also reduced by 1.2x and latency by 1.2x at the cost of 2.21% accuracy.
MLPerf Tiny Benchmark
Jun 28, 2021
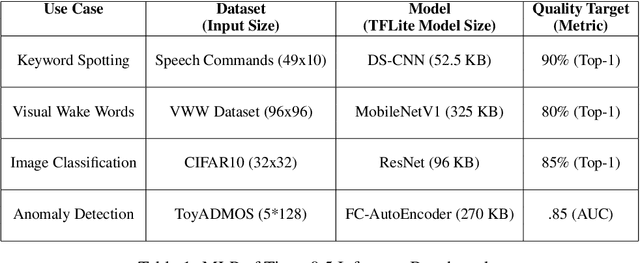
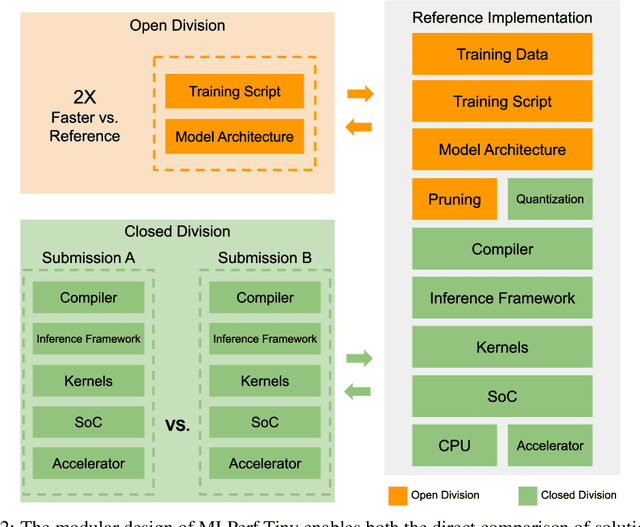
Advancements in ultra-low-power tiny machine learning (TinyML) systems promise to unlock an entirely new class of smart applications. However, continued progress is limited by the lack of a widely accepted and easily reproducible benchmark for these systems. To meet this need, we present MLPerf Tiny, the first industry-standard benchmark suite for ultra-low-power tiny machine learning systems. The benchmark suite is the collaborative effort of more than 50 organizations from industry and academia and reflects the needs of the community. MLPerf Tiny measures the accuracy, latency, and energy of machine learning inference to properly evaluate the tradeoffs between systems. Additionally, MLPerf Tiny implements a modular design that enables benchmark submitters to show the benefits of their product, regardless of where it falls on the ML deployment stack, in a fair and reproducible manner. The suite features four benchmarks: keyword spotting, visual wake words, image classification, and anomaly detection.
AnalogNets: ML-HW Co-Design of Noise-robust TinyML Models and Always-On Analog Compute-in-Memory Accelerator
Nov 10, 2021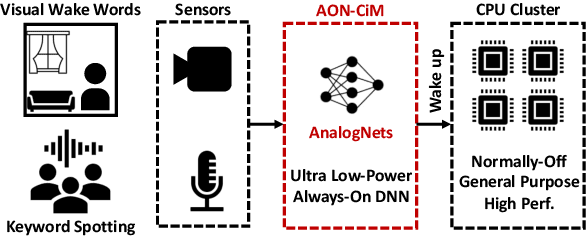
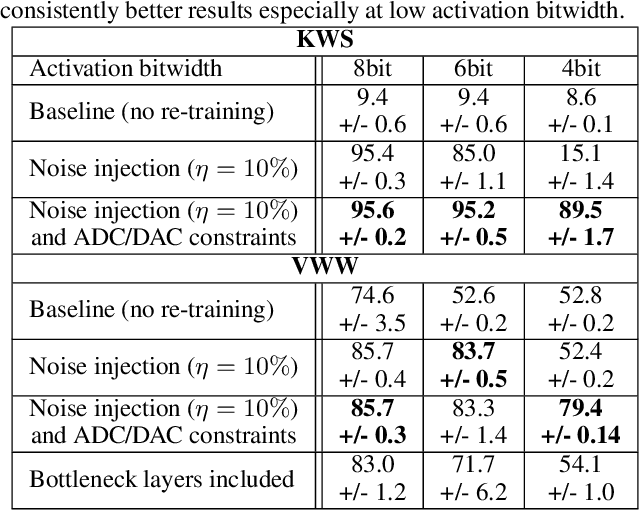
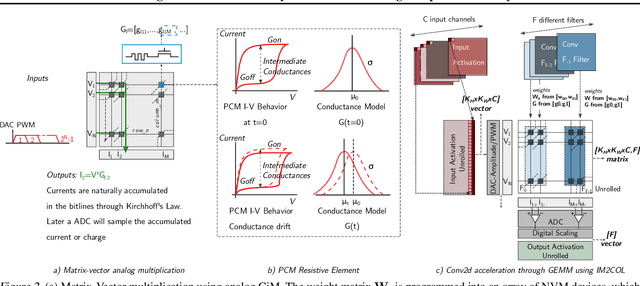
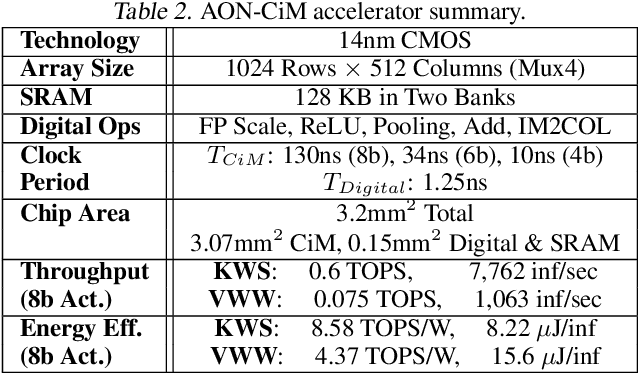
Always-on TinyML perception tasks in IoT applications require very high energy efficiency. Analog compute-in-memory (CiM) using non-volatile memory (NVM) promises high efficiency and also provides self-contained on-chip model storage. However, analog CiM introduces new practical considerations, including conductance drift, read/write noise, fixed analog-to-digital (ADC) converter gain, etc. These additional constraints must be addressed to achieve models that can be deployed on analog CiM with acceptable accuracy loss. This work describes $\textit{AnalogNets}$: TinyML models for the popular always-on applications of keyword spotting (KWS) and visual wake words (VWW). The model architectures are specifically designed for analog CiM, and we detail a comprehensive training methodology, to retain accuracy in the face of analog non-idealities, and low-precision data converters at inference time. We also describe AON-CiM, a programmable, minimal-area phase-change memory (PCM) analog CiM accelerator, with a novel layer-serial approach to remove the cost of complex interconnects associated with a fully-pipelined design. We evaluate the AnalogNets on a calibrated simulator, as well as real hardware, and find that accuracy degradation is limited to 0.8$\%$/1.2$\%$ after 24 hours of PCM drift (8-bit) for KWS/VWW. AnalogNets running on the 14nm AON-CiM accelerator demonstrate 8.58/4.37 TOPS/W for KWS/VWW workloads using 8-bit activations, respectively, and increasing to 57.39/25.69 TOPS/W with $4$-bit activations.
Seeing wake words: Audio-visual Keyword Spotting
Sep 02, 2020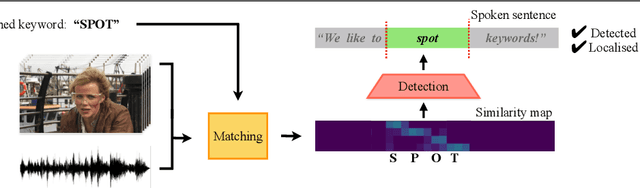
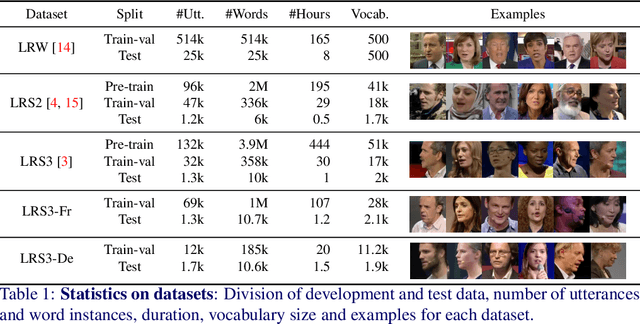
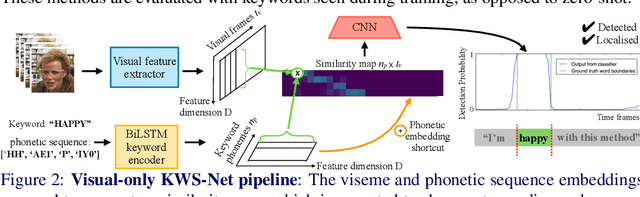
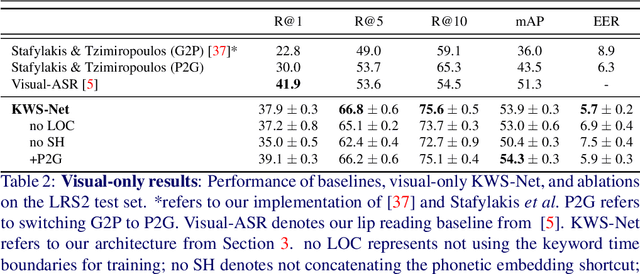
The goal of this work is to automatically determine whether and when a word of interest is spoken by a talking face, with or without the audio. We propose a zero-shot method suitable for in the wild videos. Our key contributions are: (1) a novel convolutional architecture, KWS-Net, that uses a similarity map intermediate representation to separate the task into (i) sequence matching, and (ii) pattern detection, to decide whether the word is there and when; (2) we demonstrate that if audio is available, visual keyword spotting improves the performance both for a clean and noisy audio signal. Finally, (3) we show that our method generalises to other languages, specifically French and German, and achieves a comparable performance to English with less language specific data, by fine-tuning the network pre-trained on English. The method exceeds the performance of the previous state-of-the-art visual keyword spotting architecture when trained and tested on the same benchmark, and also that of a state-of-the-art lip reading method.
A Twitter-Driven Deep Learning Mechanism for the Determination of Vehicle Hijacking Spots in Cities
Aug 11, 2022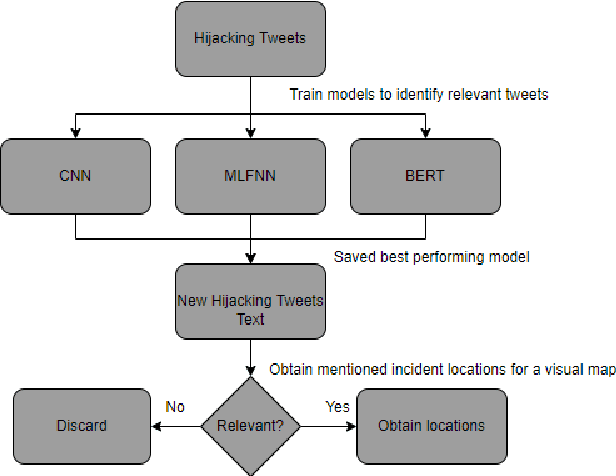
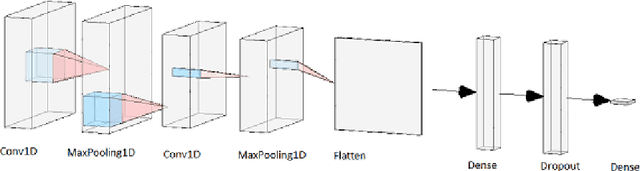
Vehicle hijacking is one of the leading crimes in many cities. For instance, in South Africa, drivers must constantly remain vigilant on the road in order to ensure that they do not become hijacking victims. This work is aimed at developing a map depicting hijacking spots in a city by using Twitter data. Tweets, which include the keyword "hijacking", are obtained in a designated city of Cape Town, in this work. In order to extract relevant tweets, these tweets are analyzed by using the following machine learning techniques: 1) a Multi-layer Feed-forward Neural Network (MLFNN); 2) Convolutional Neural Network; and Bidirectional Encoder Representations from Transformers (BERT). Through training and testing, CNN achieved an accuracy of 99.66%, while MLFNN and BERT achieve accuracies of 98.99% and 73.99% respectively. In terms of Recall, Precision and F1-score, CNN also achieved the best results. Therefore, CNN was used for the identification of relevant tweets. The relevant reports that it generates are visually presented on a points map of the City of Cape Town. This work used a small dataset of 426 tweets. In future, the use of evolutionary computation will be explored for purposes of optimizing the deep learning models. A mobile application is under development to make this information usable by the general public.
Keyword localisation in untranscribed speech using visually grounded speech models
Feb 02, 2022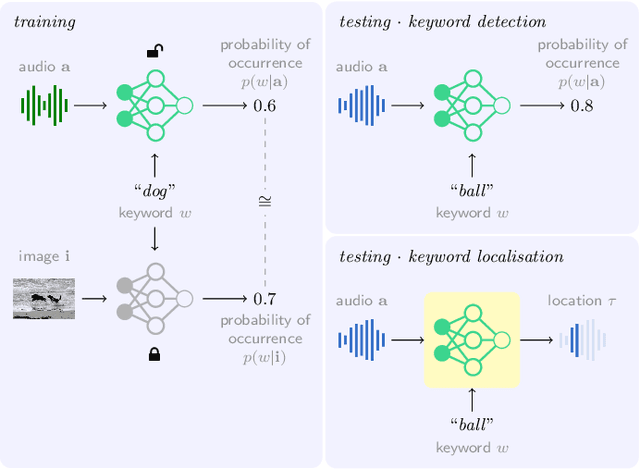
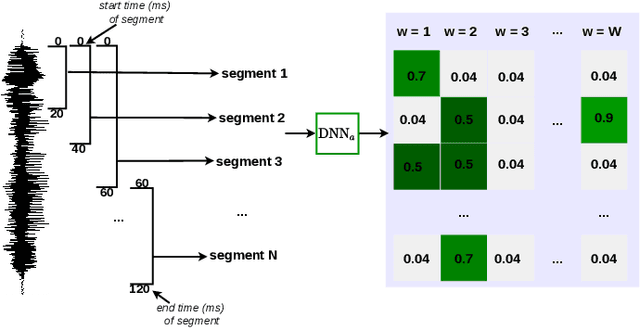
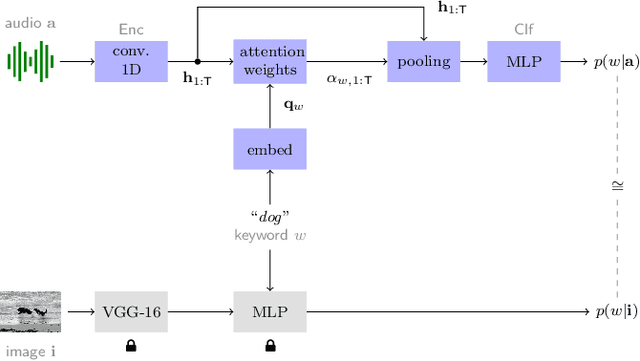
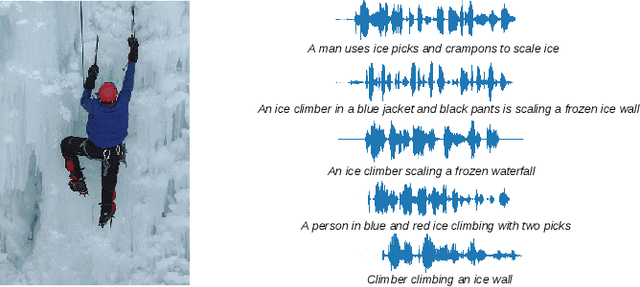
Keyword localisation is the task of finding where in a speech utterance a given query keyword occurs. We investigate to what extent keyword localisation is possible using a visually grounded speech (VGS) model. VGS models are trained on unlabelled images paired with spoken captions. These models are therefore self-supervised -- trained without any explicit textual label or location information. To obtain training targets, we first tag training images with soft text labels using a pretrained visual classifier with a fixed vocabulary. This enables a VGS model to predict the presence of a written keyword in an utterance, but not its location. We consider four ways to equip VGS models with localisations capabilities. Two of these -- a saliency approach and input masking -- can be applied to an arbitrary prediction model after training, while the other two -- attention and a score aggregation approach -- are incorporated directly into the structure of the model. Masked-based localisation gives some of the best reported localisation scores from a VGS model, with an accuracy of 57% when the system knows that a keyword occurs in an utterance and need to predict its location. In a setting where localisation is performed after detection, an $F_1$ of 25% is achieved, and in a setting where a keyword spotting ranking pass is first performed, we get a localisation P@10 of 32%. While these scores are modest compared to the idealised setting with unordered bag-of-word-supervision (from transcriptions), these models do not receive any textual or location supervision. Further analyses show that these models are limited by the first detection or ranking pass. Moreover, individual keyword localisation performance is correlated with the tagging performance from the visual classifier. We also show qualitatively how and where semantic mistakes occur, e.g. that the model locates surfer when queried with ocean.