 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScene Text Recognition Models Explainability Using Local Features
Oct 14, 2023



Explainable AI (XAI) is the study on how humans can be able to understand the cause of a model's prediction. In this work, the problem of interest is Scene Text Recognition (STR) Explainability, using XAI to understand the cause of an STR model's prediction. Recent XAI literatures on STR only provide a simple analysis and do not fully explore other XAI methods. In this study, we specifically work on data explainability frameworks, called attribution-based methods, that explain the important parts of an input data in deep learning models. However, integrating them into STR produces inconsistent and ineffective explanations, because they only explain the model in the global context. To solve this problem, we propose a new method, STRExp, to take into consideration the local explanations, i.e. the individual character prediction explanations. This is then benchmarked across different attribution-based methods on different STR datasets and evaluated across different STR models.
EfficientSpeech: An On-Device Text to Speech Model
May 23, 2023State of the art (SOTA) neural text to speech (TTS) models can generate natural-sounding synthetic voices. These models are characterized by large memory footprints and substantial number of operations due to the long-standing focus on speech quality with cloud inference in mind. Neural TTS models are generally not designed to perform standalone speech syntheses on resource-constrained and no Internet access edge devices. In this work, an efficient neural TTS called EfficientSpeech that synthesizes speech on an ARM CPU in real-time is proposed. EfficientSpeech uses a shallow non-autoregressive pyramid-structure transformer forming a U-Network. EfficientSpeech has 266k parameters and consumes 90 MFLOPS only or about 1% of the size and amount of computation in modern compact models such as Mixer-TTS. EfficientSpeech achieves an average mel generation real-time factor of 104.3 on an RPi4. Human evaluation shows only a slight degradation in audio quality as compared to FastSpeech2.
Scene Text Recognition with Permuted Autoregressive Sequence Models
Jul 14, 2022

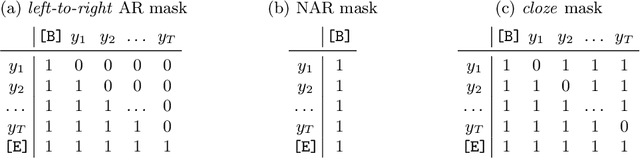
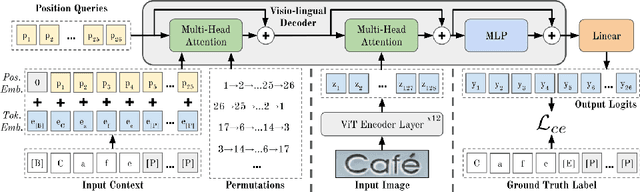
Context-aware STR methods typically use internal autoregressive (AR) language models (LM). Inherent limitations of AR models motivated two-stage methods which employ an external LM. The conditional independence of the external LM on the input image may cause it to erroneously rectify correct predictions, leading to significant inefficiencies. Our method, PARSeq, learns an ensemble of internal AR LMs with shared weights using Permutation Language Modeling. It unifies context-free non-AR and context-aware AR inference, and iterative refinement using bidirectional context. Using synthetic training data, PARSeq achieves state-of-the-art (SOTA) results in STR benchmarks (91.9% accuracy) and more challenging datasets. It establishes new SOTA results (96.0% accuracy) when trained on real data. PARSeq is optimal on accuracy vs parameter count, FLOPS, and latency because of its simple, unified structure and parallel token processing. Due to its extensive use of attention, it is robust on arbitrarily-oriented text which is common in real-world images. Code, pretrained weights, and data are available at: https://github.com/baudm/parseq.
Depth Pruning with Auxiliary Networks for TinyML
Apr 22, 2022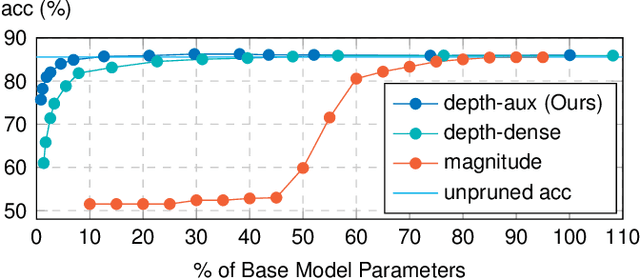

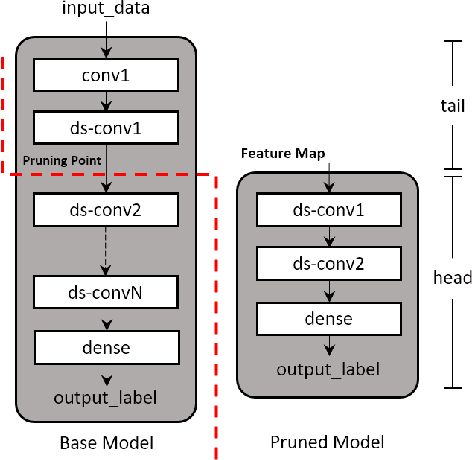

Pruning is a neural network optimization technique that sacrifices accuracy in exchange for lower computational requirements. Pruning has been useful when working with extremely constrained environments in tinyML. Unfortunately, special hardware requirements and limited study on its effectiveness on already compact models prevent its wider adoption. Depth pruning is a form of pruning that requires no specialized hardware but suffers from a large accuracy falloff. To improve this, we propose a modification that utilizes a highly efficient auxiliary network as an effective interpreter of intermediate feature maps. Our results show a parameter reduction of 93% on the MLPerfTiny Visual Wakewords (VWW) task and 28% on the Keyword Spotting (KWS) task with accuracy cost of 0.65% and 1.06% respectively. When evaluated on a Cortex-M0 microcontroller, our proposed method reduces the VWW model size by 4.7x and latency by 1.6x while counter intuitively gaining 1% accuracy. KWS model size on Cortex-M0 was also reduced by 1.2x and latency by 1.2x at the cost of 2.21% accuracy.
Improving Model Generalization by Agreement of Learned Representations from Data Augmentation
Oct 20, 2021
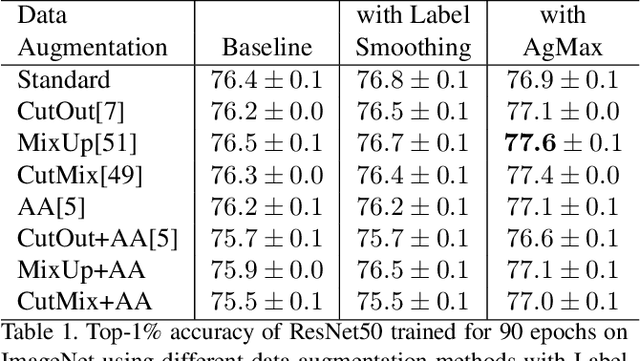
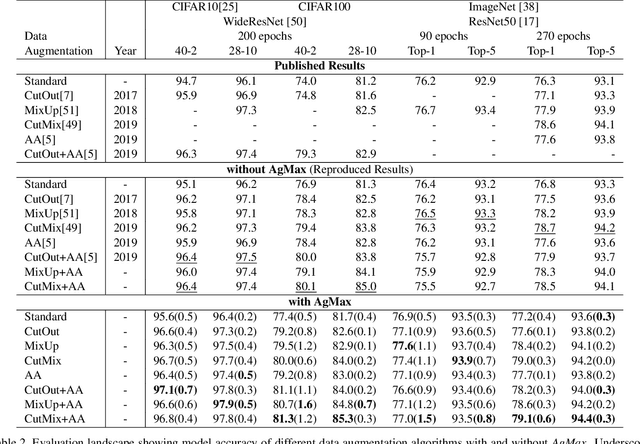
Data augmentation reduces the generalization error by forcing a model to learn invariant representations given different transformations of the input image. In computer vision, on top of the standard image processing functions, data augmentation techniques based on regional dropout such as CutOut, MixUp, and CutMix and policy-based selection such as AutoAugment demonstrated state-of-the-art (SOTA) results. With an increasing number of data augmentation algorithms being proposed, the focus is always on optimizing the input-output mapping while not realizing that there might be an untapped value in the transformed images with the same label. We hypothesize that by forcing the representations of two transformations to agree, we can further reduce the model generalization error. We call our proposed method Agreement Maximization or simply AgMax. With this simple constraint applied during training, empirical results show that data augmentation algorithms can further improve the classification accuracy of ResNet50 on ImageNet by up to 1.5%, WideResNet40-2 on CIFAR10 by up to 0.7%, WideResNet40-2 on CIFAR100 by up to 1.6%, and LeNet5 on Speech Commands Dataset by up to 1.4%. Experimental results further show that unlike other regularization terms such as label smoothing, AgMax can take advantage of the data augmentation to consistently improve model generalization by a significant margin. On downstream tasks such as object detection and segmentation on PascalVOC and COCO, AgMax pre-trained models outperforms other data augmentation methods by as much as 1.0mAP (box) and 0.5mAP (mask). Code is available at https://github.com/roatienza/agmax.
Data Augmentation for Scene Text Recognition
Aug 16, 2021


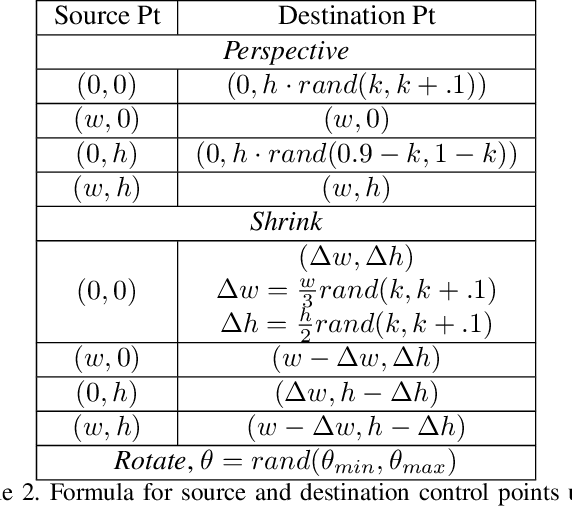
Scene text recognition (STR) is a challenging task in computer vision due to the large number of possible text appearances in natural scenes. Most STR models rely on synthetic datasets for training since there are no sufficiently big and publicly available labelled real datasets. Since STR models are evaluated using real data, the mismatch between training and testing data distributions results into poor performance of models especially on challenging text that are affected by noise, artifacts, geometry, structure, etc. In this paper, we introduce STRAug which is made of 36 image augmentation functions designed for STR. Each function mimics certain text image properties that can be found in natural scenes, caused by camera sensors, or induced by signal processing operations but poorly represented in the training dataset. When applied to strong baseline models using RandAugment, STRAug significantly increases the overall absolute accuracy of STR models across regular and irregular test datasets by as much as 2.10% on Rosetta, 1.48% on R2AM, 1.30% on CRNN, 1.35% on RARE, 1.06% on TRBA and 0.89% on GCRNN. The diversity and simplicity of API provided by STRAug functions enable easy replication and validation of existing data augmentation methods for STR. STRAug is available at https://github.com/roatienza/straug.
GOO: A Dataset for Gaze Object Prediction in Retail Environments
May 22, 2021
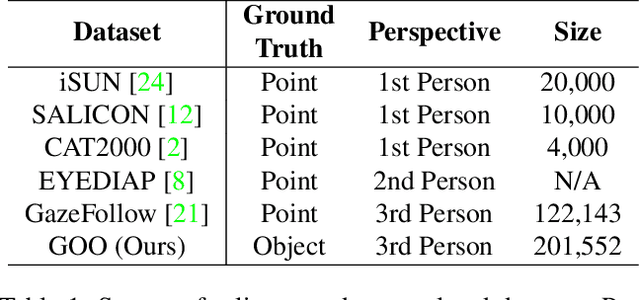
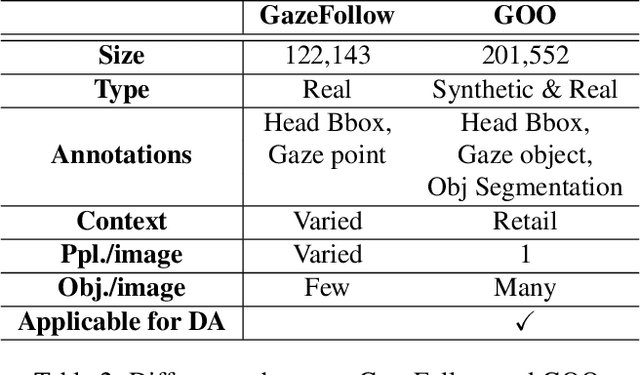

One of the most fundamental and information-laden actions humans do is to look at objects. However, a survey of current works reveals that existing gaze-related datasets annotate only the pixel being looked at, and not the boundaries of a specific object of interest. This lack of object annotation presents an opportunity for further advancing gaze estimation research. To this end, we present a challenging new task called gaze object prediction, where the goal is to predict a bounding box for a person's gazed-at object. To train and evaluate gaze networks on this task, we present the Gaze On Objects (GOO) dataset. GOO is composed of a large set of synthetic images (GOO Synth) supplemented by a smaller subset of real images (GOO-Real) of people looking at objects in a retail environment. Our work establishes extensive baselines on GOO by re-implementing and evaluating selected state-of-the art models on the task of gaze following and domain adaptation. Code is available on github.
Vision Transformer for Fast and Efficient Scene Text Recognition
May 18, 2021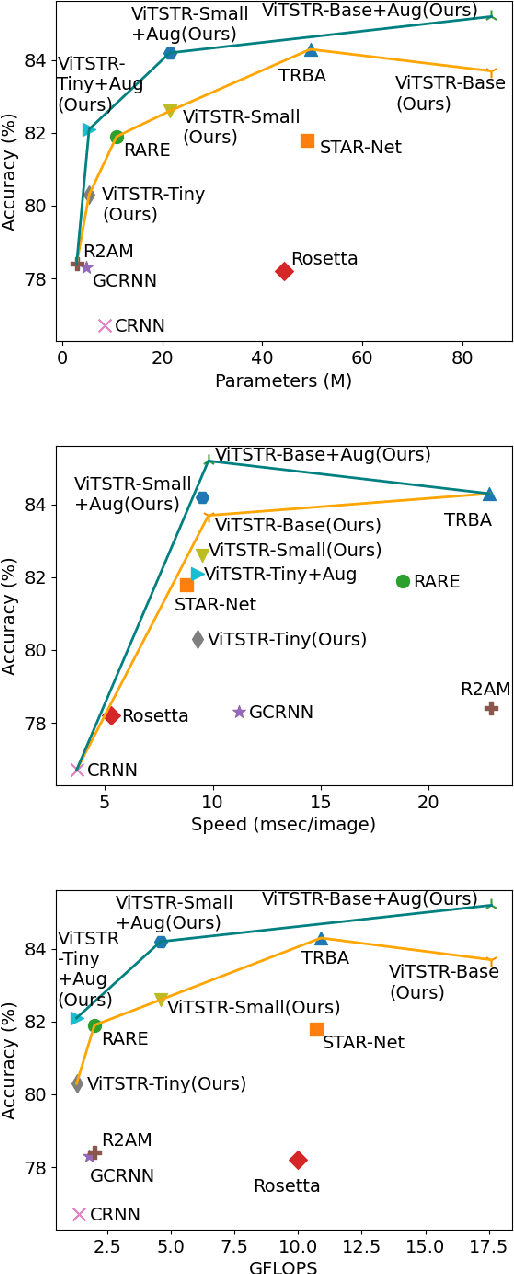


Scene text recognition (STR) enables computers to read text in natural scenes such as object labels, road signs and instructions. STR helps machines perform informed decisions such as what object to pick, which direction to go, and what is the next step of action. In the body of work on STR, the focus has always been on recognition accuracy. There is little emphasis placed on speed and computational efficiency which are equally important especially for energy-constrained mobile machines. In this paper we propose ViTSTR, an STR with a simple single stage model architecture built on a compute and parameter efficient vision transformer (ViT). On a comparable strong baseline method such as TRBA with accuracy of 84.3%, our small ViTSTR achieves a competitive accuracy of 82.6% (84.2% with data augmentation) at 2.4x speed up, using only 43.4% of the number of parameters and 42.2% FLOPS. The tiny version of ViTSTR achieves 80.3% accuracy (82.1% with data augmentation), at 2.5x the speed, requiring only 10.9% of the number of parameters and 11.9% FLOPS. With data augmentation, our base ViTSTR outperforms TRBA at 85.2% accuracy (83.7% without augmentation) at 2.3x the speed but requires 73.2% more parameters and 61.5% more FLOPS. In terms of trade-offs, nearly all ViTSTR configurations are at or near the frontiers to maximize accuracy, speed and computational efficiency all at the same time.
* To appear at ICDAR2021 Springer Lecture Notes in Computer Science series
Next-Best View Policy for 3D Reconstruction
Sep 06, 2020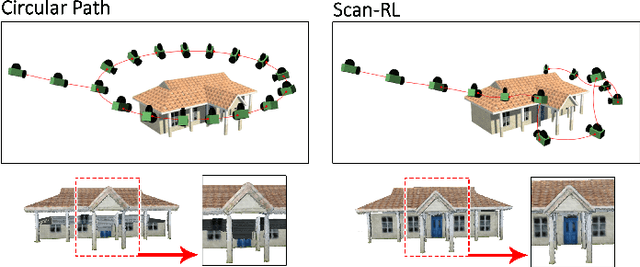

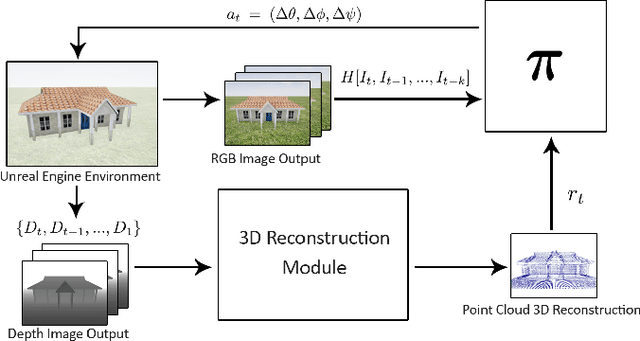

Manually selecting viewpoints or using commonly available flight planners like circular path for large-scale 3D reconstruction using drones often results in incomplete 3D models. Recent works have relied on hand-engineered heuristics such as information gain to select the Next-Best Views. In this work, we present a learning-based algorithm called Scan-RL to learn a Next-Best View (NBV) Policy. To train and evaluate the agent, we created Houses3K, a dataset of 3D house models. Our experiments show that using Scan-RL, the agent can scan houses with fewer number of steps and a shorter distance compared to our baseline circular path. Experimental results also demonstrate that a single NBV policy can be used to scan multiple houses including those that were not seen during training. The link to Scan-RL is available at https://github.com/darylperalta/ScanRL and Houses3K dataset can be found at https://github.com/darylperalta/Houses3K.
Fast Disparity Estimation using Dense Networks
May 19, 2018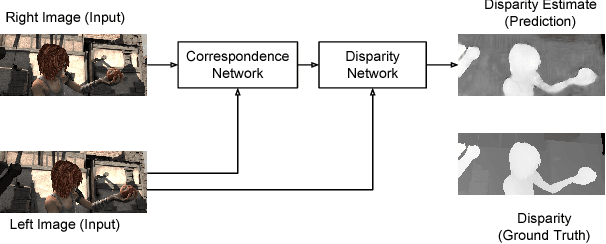
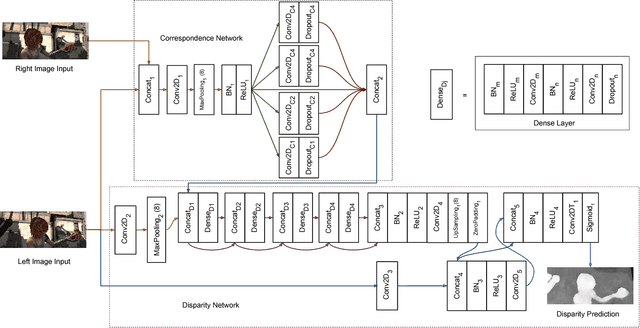

Disparity estimation is a difficult problem in stereo vision because the correspondence technique fails in images with textureless and repetitive regions. Recent body of work using deep convolutional neural networks (CNN) overcomes this problem with semantics. Most CNN implementations use an autoencoder method; stereo images are encoded, merged and finally decoded to predict the disparity map. In this paper, we present a CNN implementation inspired by dense networks to reduce the number of parameters. Furthermore, our approach takes into account semantic reasoning in disparity estimation. Our proposed network, called DenseMapNet, is compact, fast and can be trained end-to-end. DenseMapNet requires 290k parameters only and runs at 30Hz or faster on color stereo images in full resolution. Experimental results show that DenseMapNet accuracy is comparable with other significantly bigger CNN-based methods.