 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Interactive Intelligence for Digital Humans
Dec 15, 2025We introduce Interactive Intelligence, a novel paradigm of digital human that is capable of personality-aligned expression, adaptive interaction, and self-evolution. To realize this, we present Mio (Multimodal Interactive Omni-Avatar), an end-to-end framework composed of five specialized modules: Thinker, Talker, Face Animator, Body Animator, and Renderer. This unified architecture integrates cognitive reasoning with real-time multimodal embodiment to enable fluid, consistent interaction. Furthermore, we establish a new benchmark to rigorously evaluate the capabilities of interactive intelligence. Extensive experiments demonstrate that our framework achieves superior performance compared to state-of-the-art methods across all evaluated dimensions. Together, these contributions move digital humans beyond superficial imitation toward intelligent interaction.
LipLearner: Customizable Silent Speech Interactions on Mobile Devices
Feb 14, 2023

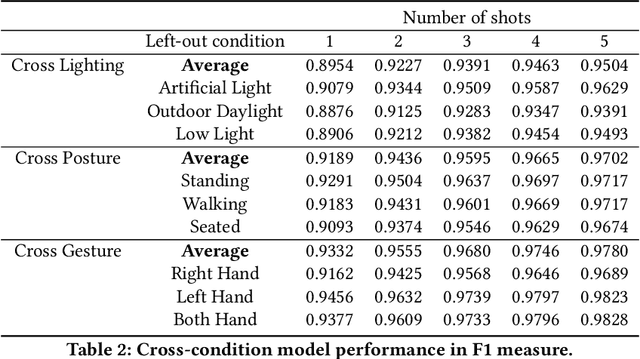

Silent speech interface is a promising technology that enables private communications in natural language. However, previous approaches only support a small and inflexible vocabulary, which leads to limited expressiveness. We leverage contrastive learning to learn efficient lipreading representations, enabling few-shot command customization with minimal user effort. Our model exhibits high robustness to different lighting, posture, and gesture conditions on an in-the-wild dataset. For 25-command classification, an F1-score of 0.8947 is achievable only using one shot, and its performance can be further boosted by adaptively learning from more data. This generalizability allowed us to develop a mobile silent speech interface empowered with on-device fine-tuning and visual keyword spotting. A user study demonstrated that with LipLearner, users could define their own commands with high reliability guaranteed by an online incremental learning scheme. Subjective feedback indicated that our system provides essential functionalities for customizable silent speech interactions with high usability and learnability.