 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeT2t Vit
Papers and Code
Changing Base Without Losing Pace: A GPU-Efficient Alternative to MatMul in DNNs
Mar 15, 2025



We propose a cheaper alternative bilinear operator to matrix-multiplication in deep neural networks (DNNs). Unlike many stubborn attempts to accelerate MatMuls in DNN inference, this operator is supported by capabilities of existing GPU hardware, most notably NVIDIA TensorCores. To our knowledge, this is the first GPU-native acceleration technique which \emph{does not decrease} (in fact, increases) the number of trainable parameters of the network, mitigating the accuracy-loss of compression-based techniques. Hence, this operator is at the same time more expressive than MatMul, yet requires substantially \emph{fewer} FLOPs to evaluate. We term this new operator \emph{Strassen-Tile} (STL). The main idea behind STL$(X,W)$ is a \emph{local} change-of-basis (learnable encoder) on weights and activation \emph{tiles}, after which we perform batched \emph{elementwise} products between tiles, and a final decoding transformation (inspired by algebraic pipelines from fast matrix and polynomial multiplication). We compare STL against two benchmarks. The first one is SoTA T2T-ViT on Imagenet-1K. Here we show that replacing \emph{all} linear layers with STL and training from scratch, results in factor x2.7 reduction in FLOPs with a 0.5 \emph{accuracy improvement}. Our second speed-accuracy comparison benchmark for pretrained LLMs is the most practical GPU-acceleration technique, \twofour structured Sparsity. Finetuning TinyLlama \cite{tinyllama24} with STL layers on the Slim Pajama dataset, achieves similar accuracy to 2:4, with x2.2 FLOP speedup compared to x1.7 of the latter. Finally, we discuss a group-theoretic approach for discovering \emph{universal} encoders for STL, which could lead to fast \emph{black-box} acceleration via approximate matrix-multiplication (AMM).
Multi-criteria Token Fusion with One-step-ahead Attention for Efficient Vision Transformers
Apr 01, 2024Vision Transformer (ViT) has emerged as a prominent backbone for computer vision. For more efficient ViTs, recent works lessen the quadratic cost of the self-attention layer by pruning or fusing the redundant tokens. However, these works faced the speed-accuracy trade-off caused by the loss of information. Here, we argue that token fusion needs to consider diverse relations between tokens to minimize information loss. In this paper, we propose a Multi-criteria Token Fusion (MCTF), that gradually fuses the tokens based on multi-criteria (e.g., similarity, informativeness, and size of fused tokens). Further, we utilize the one-step-ahead attention, which is the improved approach to capture the informativeness of the tokens. By training the model equipped with MCTF using a token reduction consistency, we achieve the best speed-accuracy trade-off in the image classification (ImageNet1K). Experimental results prove that MCTF consistently surpasses the previous reduction methods with and without training. Specifically, DeiT-T and DeiT-S with MCTF reduce FLOPs by about 44% while improving the performance (+0.5%, and +0.3%) over the base model, respectively. We also demonstrate the applicability of MCTF in various Vision Transformers (e.g., T2T-ViT, LV-ViT), achieving at least 31% speedup without performance degradation. Code is available at https://github.com/mlvlab/MCTF.
USDC: Unified Static and Dynamic Compression for Visual Transformer
Oct 17, 2023



Visual Transformers have achieved great success in almost all vision tasks, such as classification, detection, and so on. However, the model complexity and the inference speed of the visual transformers hinder their deployments in industrial products. Various model compression techniques focus on directly compressing the visual transformers into a smaller one while maintaining the model performance, however, the performance drops dramatically when the compression ratio is large. Furthermore, several dynamic network techniques have also been applied to dynamically compress the visual transformers to obtain input-adaptive efficient sub-structures during the inference stage, which can achieve a better trade-off between the compression ratio and the model performance. The upper bound of memory of dynamic models is not reduced in the practical deployment since the whole original visual transformer model and the additional control gating modules should be loaded onto devices together for inference. To alleviate two disadvantages of two categories of methods, we propose to unify the static compression and dynamic compression techniques jointly to obtain an input-adaptive compressed model, which can further better balance the total compression ratios and the model performances. Moreover, in practical deployment, the batch sizes of the training and inference stage are usually different, which will cause the model inference performance to be worse than the model training performance, which is not touched by all previous dynamic network papers. We propose a sub-group gates augmentation technique to solve this performance drop problem. Extensive experiments demonstrate the superiority of our method on various baseline visual transformers such as DeiT, T2T-ViT, and so on.
A Layer-Wise Tokens-to-Token Transformer Network for Improved Historical Document Image Enhancement
Dec 06, 2023Document image enhancement is a fundamental and important stage for attaining the best performance in any document analysis assignment because there are many degradation situations that could harm document images, making it more difficult to recognize and analyze them. In this paper, we propose \textbf{T2T-BinFormer} which is a novel document binarization encoder-decoder architecture based on a Tokens-to-token vision transformer. Each image is divided into a set of tokens with a defined length using the ViT model, which is then applied several times to model the global relationship between the tokens. However, the conventional tokenization of input data does not adequately reflect the crucial local structure between adjacent pixels of the input image, which results in low efficiency. Instead of using a simple ViT and hard splitting of images for the document image enhancement task, we employed a progressive tokenization technique to capture this local information from an image to achieve more effective results. Experiments on various DIBCO and H-DIBCO benchmarks demonstrate that the proposed model outperforms the existing CNN and ViT-based state-of-the-art methods. In this research, the primary area of examination is the application of the proposed architecture to the task of document binarization. The source code will be made available at https://github.com/RisabBiswas/T2T-BinFormer.
KDEformer: Accelerating Transformers via Kernel Density Estimation
Feb 05, 2023



Dot-product attention mechanism plays a crucial role in modern deep architectures (e.g., Transformer) for sequence modeling, however, na\"ive exact computation of this model incurs quadratic time and memory complexities in sequence length, hindering the training of long-sequence models. Critical bottlenecks are due to the computation of partition functions in the denominator of softmax function as well as the multiplication of the softmax matrix with the matrix of values. Our key observation is that the former can be reduced to a variant of the kernel density estimation (KDE) problem, and an efficient KDE solver can be further utilized to accelerate the latter via subsampling-based fast matrix products. Our proposed KDEformer can approximate the attention in sub-quadratic time with provable spectral norm bounds, while all prior results merely provide entry-wise error bounds. Empirically, we verify that KDEformer outperforms other attention approximations in terms of accuracy, memory, and runtime on various pre-trained models. On BigGAN image generation, we achieve better generative scores than the exact computation with over $4\times$ speedup. For ImageNet classification with T2T-ViT, KDEformer shows over $18\times$ speedup while the accuracy drop is less than $0.5\%$.
SiaTrans: Siamese Transformer Network for RGB-D Salient Object Detection with Depth Image Classification
Jul 09, 2022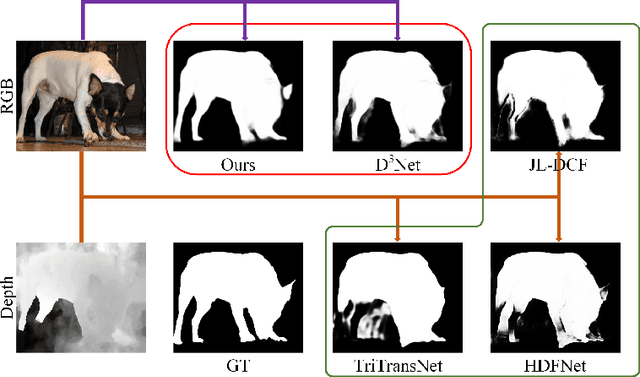
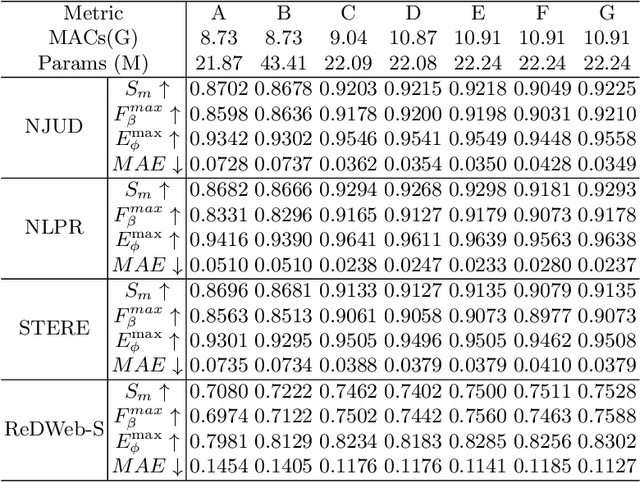
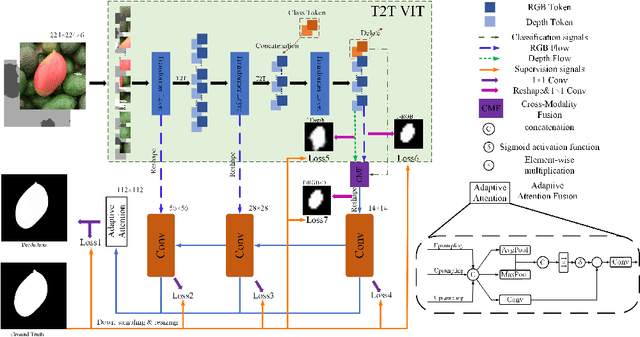
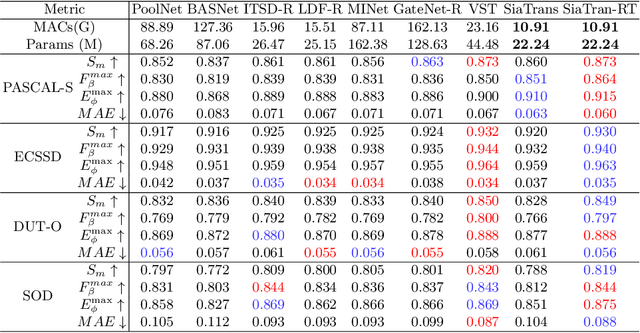
RGB-D SOD uses depth information to handle challenging scenes and obtain high-quality saliency maps. Existing state-of-the-art RGB-D saliency detection methods overwhelmingly rely on the strategy of directly fusing depth information. Although these methods improve the accuracy of saliency prediction through various cross-modality fusion strategies, misinformation provided by some poor-quality depth images can affect the saliency prediction result. To address this issue, a novel RGB-D salient object detection model (SiaTrans) is proposed in this paper, which allows training on depth image quality classification at the same time as training on SOD. In light of the common information between RGB and depth images on salient objects, SiaTrans uses a Siamese transformer network with shared weight parameters as the encoder and extracts RGB and depth features concatenated on the batch dimension, saving space resources without compromising performance. SiaTrans uses the Class token in the backbone network (T2T-ViT) to classify the quality of depth images without preventing the token sequence from going on with the saliency detection task. Transformer-based cross-modality fusion module (CMF) can effectively fuse RGB and depth information. And in the testing process, CMF can choose to fuse cross-modality information or enhance RGB information according to the quality classification signal of the depth image. The greatest benefit of our designed CMF and decoder is that they maintain the consistency of RGB and RGB-D information decoding: SiaTrans decodes RGB-D or RGB information under the same model parameters according to the classification signal during testing. Comprehensive experiments on nine RGB-D SOD benchmark datasets show that SiaTrans has the best overall performance and the least computation compared with recent state-of-the-art methods.
DropKey
Aug 08, 2022

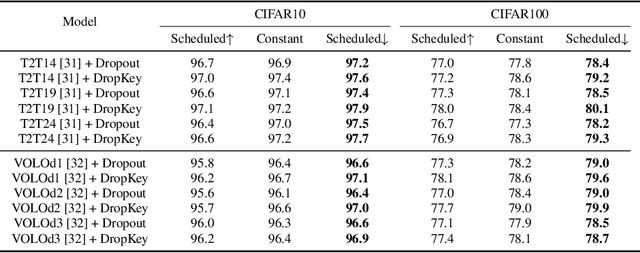
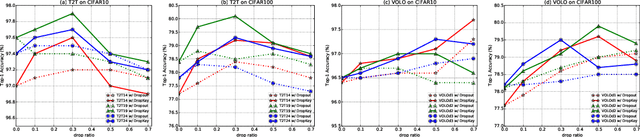
In this paper, we focus on analyzing and improving the dropout technique for self-attention layers of Vision Transformer, which is important while surprisingly ignored by prior works. In particular, we conduct researches on three core questions: First, what to drop in self-attention layers? Different from dropping attention weights in literature, we propose to move dropout operations forward ahead of attention matrix calculation and set the Key as the dropout unit, yielding a novel dropout-before-softmax scheme. We theoretically verify that this scheme helps keep both regularization and probability features of attention weights, alleviating the overfittings problem to specific patterns and enhancing the model to globally capture vital information; Second, how to schedule the drop ratio in consecutive layers? In contrast to exploit a constant drop ratio for all layers, we present a new decreasing schedule that gradually decreases the drop ratio along the stack of self-attention layers. We experimentally validate the proposed schedule can avoid overfittings in low-level features and missing in high-level semantics, thus improving the robustness and stableness of model training; Third, whether need to perform structured dropout operation as CNN? We attempt patch-based block-version of dropout operation and find that this useful trick for CNN is not essential for ViT. Given exploration on the above three questions, we present the novel DropKey method that regards Key as the drop unit and exploits decreasing schedule for drop ratio, improving ViTs in a general way. Comprehensive experiments demonstrate the effectiveness of DropKey for various ViT architectures, e.g. T2T and VOLO, as well as for various vision tasks, e.g., image classification, object detection, human-object interaction detection and human body shape recovery. Codes will be released upon acceptance.
Unified Visual Transformer Compression
Mar 15, 2022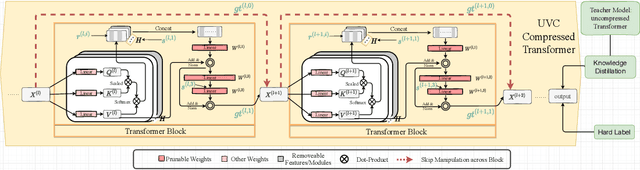
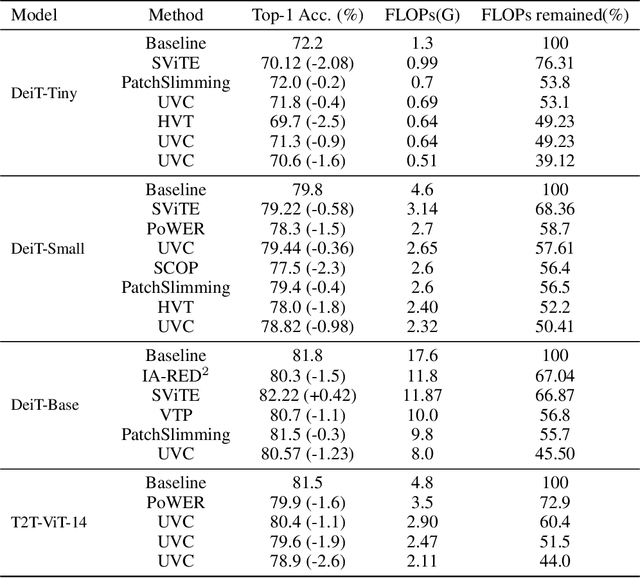
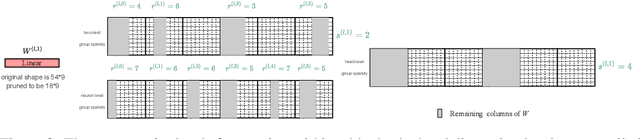
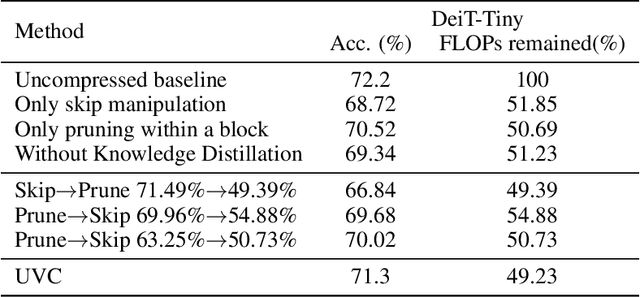
Vision transformers (ViTs) have gained popularity recently. Even without customized image operators such as convolutions, ViTs can yield competitive performance when properly trained on massive data. However, the computational overhead of ViTs remains prohibitive, due to stacking multi-head self-attention modules and else. Compared to the vast literature and prevailing success in compressing convolutional neural networks, the study of Vision Transformer compression has also just emerged, and existing works focused on one or two aspects of compression. This paper proposes a unified ViT compression framework that seamlessly assembles three effective techniques: pruning, layer skipping, and knowledge distillation. We formulate a budget-constrained, end-to-end optimization framework, targeting jointly learning model weights, layer-wise pruning ratios/masks, and skip configurations, under a distillation loss. The optimization problem is then solved using the primal-dual algorithm. Experiments are conducted with several ViT variants, e.g. DeiT and T2T-ViT backbones on the ImageNet dataset, and our approach consistently outperforms recent competitors. For example, DeiT-Tiny can be trimmed down to 50\% of the original FLOPs almost without losing accuracy. Codes are available online:~\url{https://github.com/VITA-Group/UVC}.
BViT: Broad Attention based Vision Transformer
Feb 13, 2022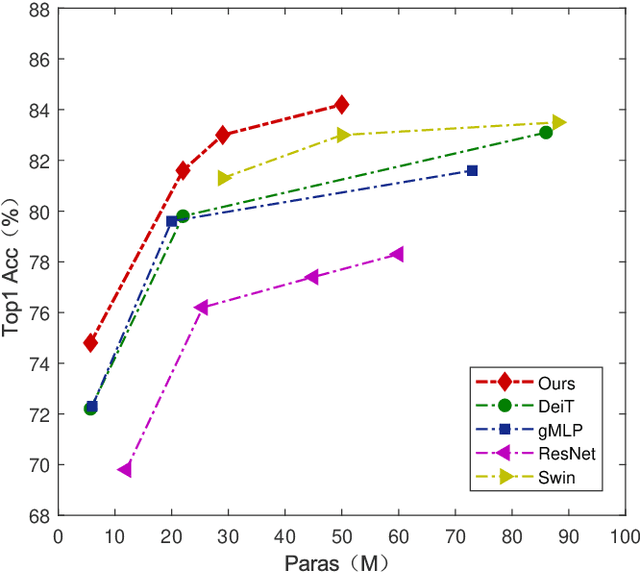
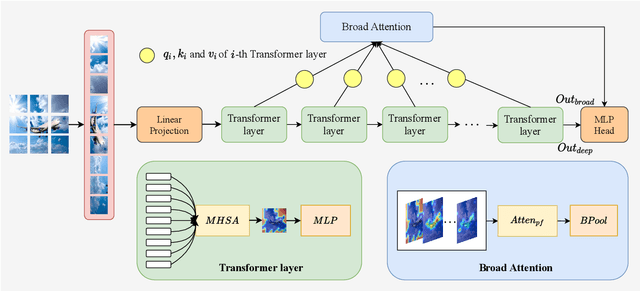
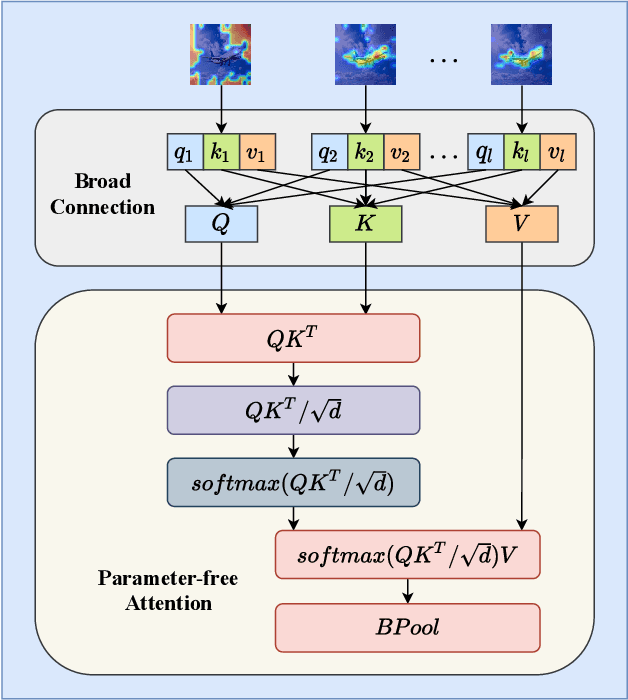
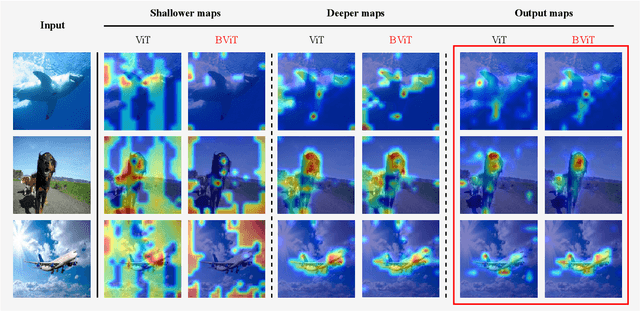
Recent works have demonstrated that transformer can achieve promising performance in computer vision, by exploiting the relationship among image patches with self-attention. While they only consider the attention in a single feature layer, but ignore the complementarity of attention in different levels. In this paper, we propose the broad attention to improve the performance by incorporating the attention relationship of different layers for vision transformer, which is called BViT. The broad attention is implemented by broad connection and parameter-free attention. Broad connection of each transformer layer promotes the transmission and integration of information for BViT. Without introducing additional trainable parameters, parameter-free attention jointly focuses on the already available attention information in different layers for extracting useful information and building their relationship. Experiments on image classification tasks demonstrate that BViT delivers state-of-the-art accuracy of 74.8\%/81.6\% top-1 accuracy on ImageNet with 5M/22M parameters. Moreover, we transfer BViT to downstream object recognition benchmarks to achieve 98.9\% and 89.9\% on CIFAR10 and CIFAR100 respectively that exceed ViT with fewer parameters. For the generalization test, the broad attention in Swin Transformer and T2T-ViT also bring an improvement of more than 1\%. To sum up, broad attention is promising to promote the performance of attention based models. Code and pre-trained models are available at https://github.com/DRL-CASIA/Broad_ViT.
Multi-Dimensional Model Compression of Vision Transformer
Dec 31, 2021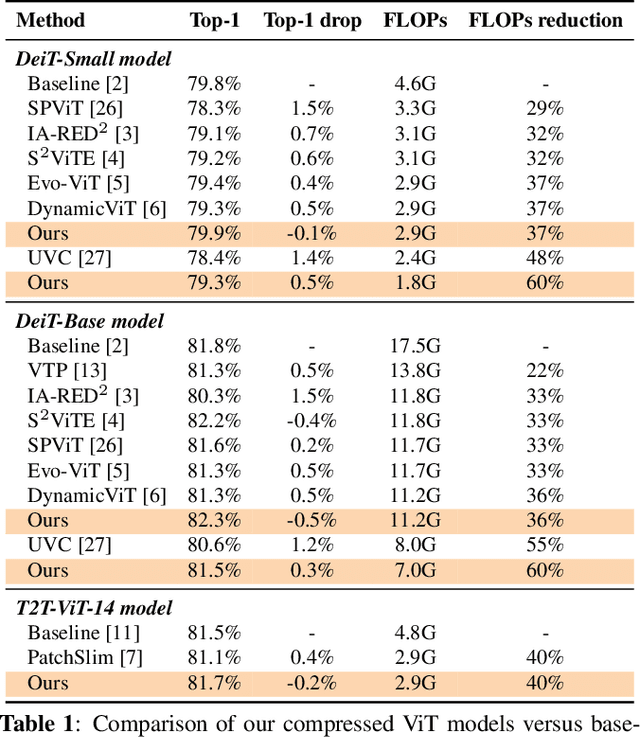
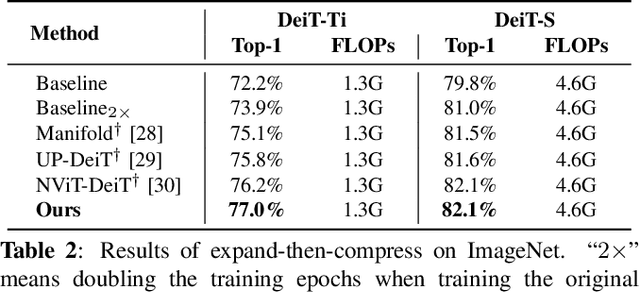


Vision transformers (ViT) have recently attracted considerable attentions, but the huge computational cost remains an issue for practical deployment. Previous ViT pruning methods tend to prune the model along one dimension solely, which may suffer from excessive reduction and lead to sub-optimal model quality. In contrast, we advocate a multi-dimensional ViT compression paradigm, and propose to harness the redundancy reduction from attention head, neuron and sequence dimensions jointly. We firstly propose a statistical dependence based pruning criterion that is generalizable to different dimensions for identifying deleterious components. Moreover, we cast the multi-dimensional compression as an optimization, learning the optimal pruning policy across the three dimensions that maximizes the compressed model's accuracy under a computational budget. The problem is solved by our adapted Gaussian process search with expected improvement. Experimental results show that our method effectively reduces the computational cost of various ViT models. For example, our method reduces 40\% FLOPs without top-1 accuracy loss for DeiT and T2T-ViT models, outperforming previous state-of-the-arts.