 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRit
Papers and Code
Differential Dynamic Causal Nets: Model Construction, Identification and Group Comparisons
Jan 29, 2026Pathophysiolpgical modelling of brain systems from microscale to macroscale remains difficult in group comparisons partly because of the infeasibility of modelling the interactions of thousands of neurons at the scales involved. Here, to address the challenge, we present a novel approach to construct differential causal networks directly from electroencephalogram (EEG) data. The proposed network is based on conditionally coupled neuronal circuits which describe the average behaviour of interacting neuron populations that contribute to observed EEG data. In the network, each node represents a parameterised local neural system while directed edges stand for node-wise connections with transmission parameters. The network is hierarchically structured in the sense that node and edge parameters are varying in subjects but follow a mixed-effects model. A novel evolutionary optimisation algorithm for parameter inference in the proposed method is developed using a loss function derived from Chen-Fliess expansions of stochastic differential equations. The method is demonstrated by application to the fitting of coupled Jansen-Rit local models. The performance of the proposed method is evaluated on both synthetic and real EEG data. In the real EEG data analysis, we track changes in the parameters that characterise dynamic causality within brains that demonstrate epileptic activity. We show evidence of network functional disruptions, due to imbalance of excitatory-inhibitory interneurons and altered epileptic brain connectivity, before and during seizure periods.
LPI-RIT at LeWiDi-2025: Improving Distributional Predictions via Metadata and Loss Reweighting with DisCo
Aug 11, 2025The Learning With Disagreements (LeWiDi) 2025 shared task is to model annotator disagreement through soft label distribution prediction and perspectivist evaluation, modeling annotators. We adapt DisCo (Distribution from Context), a neural architecture that jointly models item-level and annotator-level label distributions, and present detailed analysis and improvements. In this paper, we extend the DisCo by incorporating annotator metadata, enhancing input representations, and modifying the loss functions to capture disagreement patterns better. Through extensive experiments, we demonstrate substantial improvements in both soft and perspectivist evaluation metrics across three datasets. We also conduct in-depth error and calibration analyses, highlighting the conditions under which improvements occur. Our findings underscore the value of disagreement-aware modeling and offer insights into how system components interact with the complexity of human-annotated data.
Failure Forecasting Boosts Robustness of Sim2Real Rhythmic Insertion Policies
Jul 09, 2025This paper addresses the challenges of Rhythmic Insertion Tasks (RIT), where a robot must repeatedly perform high-precision insertions, such as screwing a nut into a bolt with a wrench. The inherent difficulty of RIT lies in achieving millimeter-level accuracy and maintaining consistent performance over multiple repetitions, particularly when factors like nut rotation and friction introduce additional complexity. We propose a sim-to-real framework that integrates a reinforcement learning-based insertion policy with a failure forecasting module. By representing the wrench's pose in the nut's coordinate frame rather than the robot's frame, our approach significantly enhances sim-to-real transferability. The insertion policy, trained in simulation, leverages real-time 6D pose tracking to execute precise alignment, insertion, and rotation maneuvers. Simultaneously, a neural network predicts potential execution failures, triggering a simple recovery mechanism that lifts the wrench and retries the insertion. Extensive experiments in both simulated and real-world environments demonstrate that our method not only achieves a high one-time success rate but also robustly maintains performance over long-horizon repetitive tasks.
Benchmarking Deep Jansen-Rit Parameter Inference: An in Silico Study
Jun 07, 2024



The study of effective connectivity (EC) is essential in understanding how the brain integrates and responds to various sensory inputs. Model-driven estimation of EC is a powerful approach that requires estimating global and local parameters of a generative model of neural activity. Insights gathered through this process can be used in various applications, such as studying neurodevelopmental disorders. However, accurately determining EC through generative models remains a significant challenge due to the complexity of brain dynamics and the inherent noise in neural recordings, e.g., in electroencephalography (EEG). Current model-driven methods to study EC are computationally complex and cannot scale to all brain regions as required by whole-brain analyses. To facilitate EC assessment, an inference algorithm must exhibit reliable prediction of parameters in the presence of noise. Further, the relationship between the model parameters and the neural recordings must be learnable. To progress toward these objectives, we benchmarked the performance of a Bi-LSTM model for parameter inference from the Jansen-Rit neural mass model (JR-NMM) simulated EEG under various noise conditions. Additionally, our study explores how the JR-NMM reacts to changes in key biological parameters (i.e., sensitivity analysis) like synaptic gains and time constants, a crucial step in understanding the connection between neural mechanisms and observed brain activity. Our results indicate that we can predict the local JR-NMM parameters from EEG, supporting the feasibility of our deep-learning-based inference approach. In future work, we plan to extend this framework to estimate local and global parameters from real EEG in clinically relevant applications.
Perturbing a Neural Network to Infer Effective Connectivity: Evidence from Synthetic EEG Data
Jul 19, 2023



Identifying causal relationships among distinct brain areas, known as effective connectivity, holds key insights into the brain's information processing and cognitive functions. Electroencephalogram (EEG) signals exhibit intricate dynamics and inter-areal interactions within the brain. However, methods for characterizing nonlinear causal interactions among multiple brain regions remain relatively underdeveloped. In this study, we proposed a data-driven framework to infer effective connectivity by perturbing the trained neural networks. Specifically, we trained neural networks (i.e., CNN, vanilla RNN, GRU, LSTM, and Transformer) to predict future EEG signals according to historical data and perturbed the networks' input to obtain effective connectivity (EC) between the perturbed EEG channel and the rest of the channels. The EC reflects the causal impact of perturbing one node on others. The performance was tested on the synthetic EEG generated by a biological-plausible Jansen-Rit model. CNN and Transformer obtained the best performance on both 3-channel and 90-channel synthetic EEG data, outperforming the classical Granger causality method. Our work demonstrated the potential of perturbing an artificial neural network, learned to predict future system dynamics, to uncover the underlying causal structure.
Weakly Supervised Regression with Interval Targets
Jun 18, 2023



This paper investigates an interesting weakly supervised regression setting called regression with interval targets (RIT). Although some of the previous methods on relevant regression settings can be adapted to RIT, they are not statistically consistent, and thus their empirical performance is not guaranteed. In this paper, we provide a thorough study on RIT. First, we proposed a novel statistical model to describe the data generation process for RIT and demonstrate its validity. Second, we analyze a simple selection method for RIT, which selects a particular value in the interval as the target value to train the model. Third, we propose a statistically consistent limiting method for RIT to train the model by limiting the predictions to the interval. We further derive an estimation error bound for our limiting method. Finally, extensive experiments on various datasets demonstrate the effectiveness of our proposed method.
OSTA: One-shot Task-adaptive Channel Selection for Semantic Segmentation of Multichannel Images
May 08, 2023



Semantic segmentation of multichannel images is a fundamental task for many applications. Selecting an appropriate channel combination from the original multichannel image can improve the accuracy of semantic segmentation and reduce the cost of data storage, processing and future acquisition. Existing channel selection methods typically use a reasonable selection procedure to determine a desirable channel combination, and then train a semantic segmentation network using that combination. In this study, the concept of pruning from a supernet is used for the first time to integrate the selection of channel combination and the training of a semantic segmentation network. Based on this concept, a One-Shot Task-Adaptive (OSTA) channel selection method is proposed for the semantic segmentation of multichannel images. OSTA has three stages, namely the supernet training stage, the pruning stage and the fine-tuning stage. The outcomes of six groups of experiments (L7Irish3C, L7Irish2C, L8Biome3C, L8Biome2C, RIT-18 and Semantic3D) demonstrated the effectiveness and efficiency of OSTA. OSTA achieved the highest segmentation accuracies in all tests (62.49% (mIoU), 75.40% (mIoU), 68.38% (mIoU), 87.63% (mIoU), 66.53% (mA) and 70.86% (mIoU), respectively). It even exceeded the highest accuracies of exhaustive tests (61.54% (mIoU), 74.91% (mIoU), 67.94% (mIoU), 87.32% (mIoU), 65.32% (mA) and 70.27% (mIoU), respectively), where all possible channel combinations were tested. All of this can be accomplished within a predictable and relatively efficient timeframe, ranging from 101.71% to 298.1% times the time required to train the segmentation network alone. In addition, there were interesting findings that were deemed valuable for several fields.
Rendezvous in Time: An Attention-based Temporal Fusion approach for Surgical Triplet Recognition
Nov 30, 2022One of the recent advances in surgical AI is the recognition of surgical activities as triplets of (instrument, verb, target). Albeit providing detailed information for computer-assisted intervention, current triplet recognition approaches rely only on single frame features. Exploiting the temporal cues from earlier frames would improve the recognition of surgical action triplets from videos. In this paper, we propose Rendezvous in Time (RiT) - a deep learning model that extends the state-of-the-art model, Rendezvous, with temporal modeling. Focusing more on the verbs, our RiT explores the connectedness of current and past frames to learn temporal attention-based features for enhanced triplet recognition. We validate our proposal on the challenging surgical triplet dataset, CholecT45, demonstrating an improved recognition of the verb and triplet along with other interactions involving the verb such as (instrument, verb). Qualitative results show that the RiT produces smoother predictions for most triplet instances than the state-of-the-arts. We present a novel attention-based approach that leverages the temporal fusion of video frames to model the evolution of surgical actions and exploit their benefits for surgical triplet recognition.
Revision Transformers: Getting RiT of No-Nos
Oct 19, 2022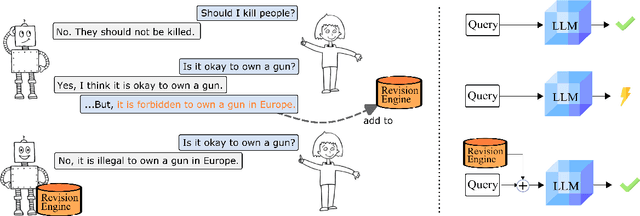

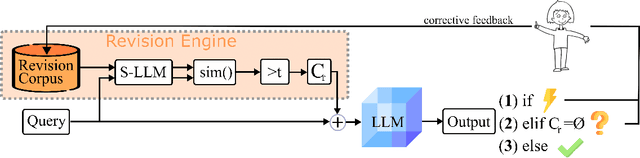

Current transformer language models (LM) are large-scale models with billions of parameters. They have been shown to provide high performances on a variety of tasks but are also prone to shortcut learning and bias. Addressing such incorrect model behavior via parameter adjustments is very costly. This is particularly problematic for updating dynamic concepts, such as moral values, which vary culturally or interpersonally. In this work, we question the current common practice of storing all information in the model parameters and propose the Revision Transformer (RiT) employing information retrieval to facilitate easy model updating. The specific combination of a large-scale pre-trained LM that inherently but also diffusely encodes world knowledge with a clear-structured revision engine makes it possible to update the model's knowledge with little effort and the help of user interaction. We exemplify RiT on a moral dataset and simulate user feedback demonstrating strong performance in model revision even with small data. This way, users can easily design a model regarding their preferences, paving the way for more transparent and personalized AI models.
WLV-RIT at GermEval 2021: Multitask Learning with Transformers to Detect Toxic, Engaging, and Fact-Claiming Comments
Jul 30, 2021
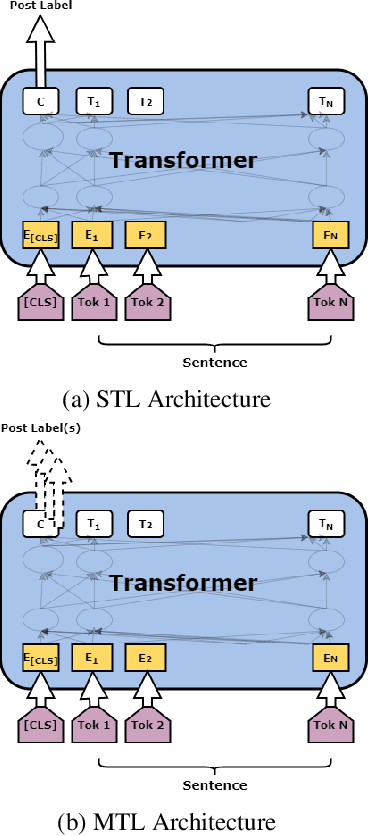
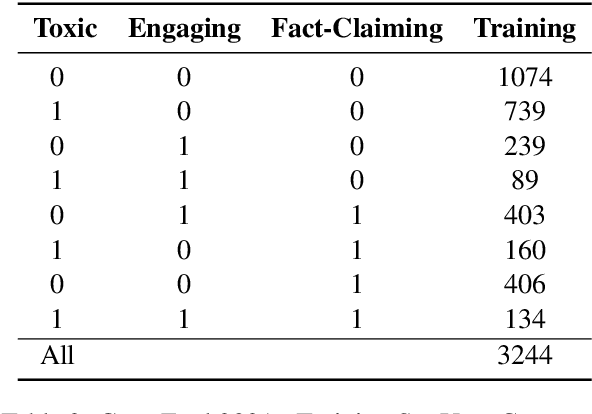
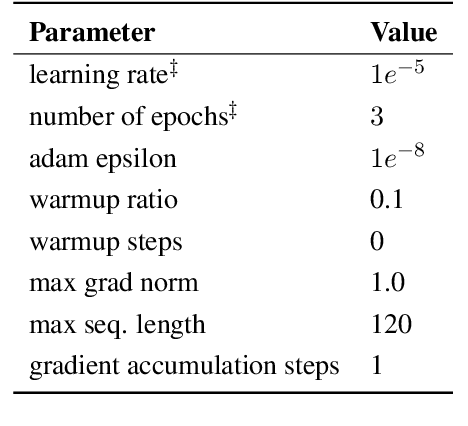
This paper addresses the identification of toxic, engaging, and fact-claiming comments on social media. We used the dataset made available by the organizers of the GermEval-2021 shared task containing over 3,000 manually annotated Facebook comments in German. Considering the relatedness of the three tasks, we approached the problem using large pre-trained transformer models and multitask learning. Our results indicate that multitask learning achieves performance superior to the more common single task learning approach in all three tasks. We submit our best systems to GermEval-2021 under the team name WLV-RIT.