 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRGB Stacking
Papers and Code
Real-Time 2D LiDAR Object Detection Using Three-Frame RGB Scan Encoding
Feb 02, 2026Indoor service robots need perception that is robust, more privacy-friendly than RGB video, and feasible on embedded hardware. We present a camera-free 2D LiDAR object detection pipeline that encodes short-term temporal context by stacking three consecutive scans as RGB channels, yielding a compact YOLOv8n input without occupancy-grid construction while preserving angular structure and motion cues. Evaluated in Webots across 160 randomized indoor scenarios with strict scenario-level holdout, the method achieves 98.4% mAP@0.5 (0.778 mAP@0.5:0.95) with 94.9% precision and 94.7% recall on four object classes. On a Raspberry Pi 5, it runs in real time with a mean post-warm-up end-to-end latency of 47.8ms per frame, including scan encoding and postprocessing. Relative to a closely related occupancy-grid LiDAR-YOLO pipeline reported on the same platform, the proposed representation is associated with substantially lower reported end-to-end latency. Although results are simulation-based, they suggest that lightweight temporal encoding can enable accurate and real-time LiDAR-only detection for embedded indoor robotics without capturing RGB appearance.
SMc2f: Robust Scenario Mining for Robotic Autonomy from Coarse to Fine
Jan 17, 2026The safety validation of autonomous robotic vehicles hinges on systematically testing their planning and control stacks against rare, safety-critical scenarios. Mining these long-tail events from massive real-world driving logs is therefore a critical step in the robotic development lifecycle. The goal of the Scenario Mining task is to retrieve useful information to enable targeted re-simulation, regression testing, and failure analysis of the robot's decision-making algorithms. RefAV, introduced by the Argoverse team, is an end-to-end framework that uses large language models (LLMs) to spatially and temporally localize scenarios described in natural language. However, this process performs retrieval on trajectory labels, ignoring the direct connection between natural language and raw RGB images, which runs counter to the intuition of video retrieval; it also depends on the quality of upstream 3D object detection and tracking. Further, inaccuracies in trajectory data lead to inaccuracies in downstream spatial and temporal localization. To address these issues, we propose Robust Scenario Mining for Robotic Autonomy from Coarse to Fine (SMc2f), a coarse-to-fine pipeline that employs vision-language models (VLMs) for coarse image-text filtering, builds a database of successful mining cases on top of RefAV and automatically retrieves exemplars to few-shot condition the LLM for more robust retrieval, and introduces text-trajectory contrastive learning to pull matched pairs together and push mismatched pairs apart in a shared embedding space, yielding a fine-grained matcher that refines the LLM's candidate trajectories. Experiments on public datasets demonstrate substantial gains in both retrieval quality and efficiency.
Diffusion Knows Transparency: Repurposing Video Diffusion for Transparent Object Depth and Normal Estimation
Dec 29, 2025Transparent objects remain notoriously hard for perception systems: refraction, reflection and transmission break the assumptions behind stereo, ToF and purely discriminative monocular depth, causing holes and temporally unstable estimates. Our key observation is that modern video diffusion models already synthesize convincing transparent phenomena, suggesting they have internalized the optical rules. We build TransPhy3D, a synthetic video corpus of transparent/reflective scenes: 11k sequences rendered with Blender/Cycles. Scenes are assembled from a curated bank of category-rich static assets and shape-rich procedural assets paired with glass/plastic/metal materials. We render RGB + depth + normals with physically based ray tracing and OptiX denoising. Starting from a large video diffusion model, we learn a video-to-video translator for depth (and normals) via lightweight LoRA adapters. During training we concatenate RGB and (noisy) depth latents in the DiT backbone and co-train on TransPhy3D and existing frame-wise synthetic datasets, yielding temporally consistent predictions for arbitrary-length input videos. The resulting model, DKT, achieves zero-shot SOTA on real and synthetic video benchmarks involving transparency: ClearPose, DREDS (CatKnown/CatNovel), and TransPhy3D-Test. It improves accuracy and temporal consistency over strong image/video baselines, and a normal variant sets the best video normal estimation results on ClearPose. A compact 1.3B version runs at ~0.17 s/frame. Integrated into a grasping stack, DKT's depth boosts success rates across translucent, reflective and diffuse surfaces, outperforming prior estimators. Together, these results support a broader claim: "Diffusion knows transparency." Generative video priors can be repurposed, efficiently and label-free, into robust, temporally coherent perception for challenging real-world manipulation.
Multi-scale Attention-Guided Intrinsic Decomposition and Rendering Pass Prediction for Facial Images
Dec 18, 2025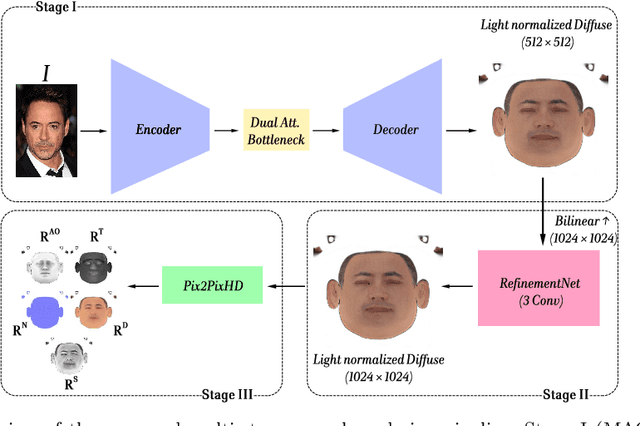

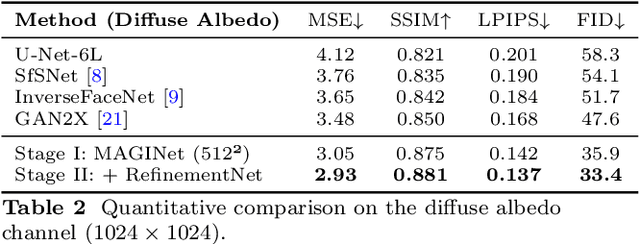
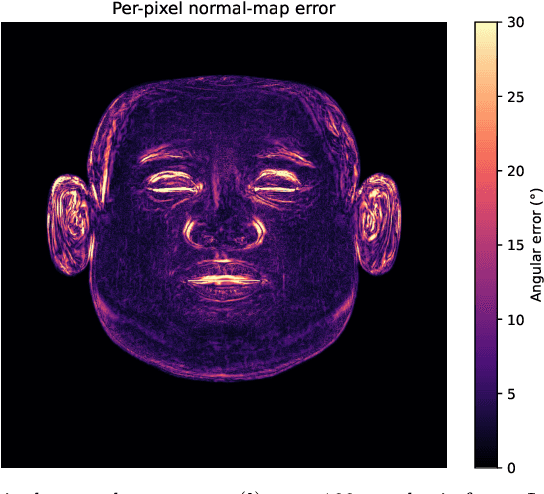
Accurate intrinsic decomposition of face images under unconstrained lighting is a prerequisite for photorealistic relighting, high-fidelity digital doubles, and augmented-reality effects. This paper introduces MAGINet, a Multi-scale Attention-Guided Intrinsics Network that predicts a $512\times512$ light-normalized diffuse albedo map from a single RGB portrait. MAGINet employs hierarchical residual encoding, spatial-and-channel attention in a bottleneck, and adaptive multi-scale feature fusion in the decoder, yielding sharper albedo boundaries and stronger lighting invariance than prior U-Net variants. The initial albedo prediction is upsampled to $1024\times1024$ and refined by a lightweight three-layer CNN (RefinementNet). Conditioned on this refined albedo, a Pix2PixHD-based translator then predicts a comprehensive set of five additional physically based rendering passes: ambient occlusion, surface normal, specular reflectance, translucency, and raw diffuse colour (with residual lighting). Together with the refined albedo, these six passes form the complete intrinsic decomposition. Trained with a combination of masked-MSE, VGG, edge, and patch-LPIPS losses on the FFHQ-UV-Intrinsics dataset, the full pipeline achieves state-of-the-art performance for diffuse albedo estimation and demonstrates significantly improved fidelity for the complete rendering stack compared to prior methods. The resulting passes enable high-quality relighting and material editing of real faces.
Multimodal RGB-HSI Feature Fusion with Patient-Aware Incremental Heuristic Meta-Learning for Oral Lesion Classification
Nov 15, 2025


Early detection of oral cancer and potentially malignant disorders is challenging in low-resource settings due to limited annotated data. We present a unified four-class oral lesion classifier that integrates deep RGB embeddings, hyperspectral reconstruction, handcrafted spectral-textural descriptors, and demographic metadata. A pathologist-verified subset of oral cavity images was curated and processed using a fine-tuned ConvNeXt-v2 encoder, followed by RGB-to-HSI reconstruction into 31-band hyperspectral cubes. Haemoglobin-sensitive indices, texture features, and spectral-shape measures were extracted and fused with deep and clinical features. Multiple machine-learning models were assessed with patient-wise validation. We further introduce an incremental heuristic meta-learner (IHML) that combines calibrated base classifiers through probabilistic stacking and patient-level posterior smoothing. On an unseen patient split, the proposed framework achieved a macro F1 of 66.23% and an accuracy of 64.56%. Results demonstrate that hyperspectral reconstruction and uncertainty-aware meta-learning substantially improve robustness for real-world oral lesion screening.
Real-Time Obstacle Avoidance for a Mobile Robot Using CNN-Based Sensor Fusion
Sep 09, 2025Obstacle avoidance is a critical component of the navigation stack required for mobile robots to operate effectively in complex and unknown environments. In this research, three end-to-end Convolutional Neural Networks (CNNs) were trained and evaluated offline and deployed on a differential-drive mobile robot for real-time obstacle avoidance to generate low-level steering commands from synchronized color and depth images acquired by an Intel RealSense D415 RGB-D camera in diverse environments. Offline evaluation showed that the NetConEmb model achieved the best performance with a notably low MedAE of $0.58 \times 10^{-3}$ rad/s. In comparison, the lighter NetEmb architecture adopted in this study, which reduces the number of trainable parameters by approximately 25\% and converges faster, produced comparable results with an RMSE of $21.68 \times 10^{-3}$ rad/s, close to the $21.42 \times 10^{-3}$ rad/s obtained by NetConEmb. Real-time navigation further confirmed NetConEmb's robustness, achieving a 100\% success rate in both known and unknown environments, while NetEmb and NetGated succeeded only in navigating the known environment.
Graph-Fused Vision-Language-Action for Policy Reasoning in Multi-Arm Robotic Manipulation
Sep 09, 2025



Acquiring dexterous robotic skills from human video demonstrations remains a significant challenge, largely due to conventional reliance on low-level trajectory replication, which often fails to generalize across varying objects, spatial layouts, and manipulator configurations. To address this limitation, we introduce Graph-Fused Vision-Language-Action (GF-VLA), a unified framework that enables dual-arm robotic systems to perform task-level reasoning and execution directly from RGB-D human demonstrations. GF-VLA employs an information-theoretic approach to extract task-relevant cues, selectively highlighting critical hand-object and object-object interactions. These cues are structured into temporally ordered scene graphs, which are subsequently integrated with a language-conditioned transformer to produce hierarchical behavior trees and interpretable Cartesian motion primitives. To enhance efficiency in bimanual execution, we propose a cross-arm allocation strategy that autonomously determines gripper assignment without requiring explicit geometric modeling. We validate GF-VLA on four dual-arm block assembly benchmarks involving symbolic structure construction and spatial generalization. Empirical results demonstrate that the proposed representation achieves over 95% graph accuracy and 93% subtask segmentation, enabling the language-action planner to generate robust, interpretable task policies. When deployed on a dual-arm robot, these policies attain 94% grasp reliability, 89% placement accuracy, and 90% overall task success across stacking, letter-formation, and geometric reconfiguration tasks, evidencing strong generalization and robustness under diverse spatial and semantic variations.
MonoMPC: Monocular Vision Based Navigation with Learned Collision Model and Risk-Aware Model Predictive Control
Aug 10, 2025Navigating unknown environments with a single RGB camera is challenging, as the lack of depth information prevents reliable collision-checking. While some methods use estimated depth to build collision maps, we found that depth estimates from vision foundation models are too noisy for zero-shot navigation in cluttered environments. We propose an alternative approach: instead of using noisy estimated depth for direct collision-checking, we use it as a rich context input to a learned collision model. This model predicts the distribution of minimum obstacle clearance that the robot can expect for a given control sequence. At inference, these predictions inform a risk-aware MPC planner that minimizes estimated collision risk. Our joint learning pipeline co-trains the collision model and risk metric using both safe and unsafe trajectories. Crucially, our joint-training ensures optimal variance in our collision model that improves navigation in highly cluttered environments. Consequently, real-world experiments show 9x and 7x improvements in success rates over NoMaD and the ROS stack, respectively. Ablation studies further validate the effectiveness of our design choices.
Information-Theoretic Graph Fusion with Vision-Language-Action Model for Policy Reasoning and Dual Robotic Control
Aug 07, 2025Teaching robots dexterous skills from human videos remains challenging due to the reliance on low-level trajectory imitation, which fails to generalize across object types, spatial layouts, and manipulator configurations. We propose Graph-Fused Vision-Language-Action (GF-VLA), a framework that enables dual-arm robotic systems to perform task-level reasoning and execution directly from RGB and Depth human demonstrations. GF-VLA first extracts Shannon-information-based cues to identify hands and objects with the highest task relevance, then encodes these cues into temporally ordered scene graphs that capture both hand-object and object-object interactions. These graphs are fused with a language-conditioned transformer that generates hierarchical behavior trees and interpretable Cartesian motion commands. To improve execution efficiency in bimanual settings, we further introduce a cross-hand selection policy that infers optimal gripper assignment without explicit geometric reasoning. We evaluate GF-VLA on four structured dual-arm block assembly tasks involving symbolic shape construction and spatial generalization. Experimental results show that the information-theoretic scene representation achieves over 95 percent graph accuracy and 93 percent subtask segmentation, supporting the LLM planner in generating reliable and human-readable task policies. When executed by the dual-arm robot, these policies yield 94 percent grasp success, 89 percent placement accuracy, and 90 percent overall task success across stacking, letter-building, and geometric reconfiguration scenarios, demonstrating strong generalization and robustness across diverse spatial and semantic variations.
UAVD-Mamba: Deformable Token Fusion Vision Mamba for Multimodal UAV Detection
Jul 01, 2025Unmanned Aerial Vehicle (UAV) object detection has been widely used in traffic management, agriculture, emergency rescue, etc. However, it faces significant challenges, including occlusions, small object sizes, and irregular shapes. These challenges highlight the necessity for a robust and efficient multimodal UAV object detection method. Mamba has demonstrated considerable potential in multimodal image fusion. Leveraging this, we propose UAVD-Mamba, a multimodal UAV object detection framework based on Mamba architectures. To improve geometric adaptability, we propose the Deformable Token Mamba Block (DTMB) to generate deformable tokens by incorporating adaptive patches from deformable convolutions alongside normal patches from normal convolutions, which serve as the inputs to the Mamba Block. To optimize the multimodal feature complementarity, we design two separate DTMBs for the RGB and infrared (IR) modalities, with the outputs from both DTMBs integrated into the Mamba Block for feature extraction and into the Fusion Mamba Block for feature fusion. Additionally, to improve multiscale object detection, especially for small objects, we stack four DTMBs at different scales to produce multiscale feature representations, which are then sent to the Detection Neck for Mamba (DNM). The DNM module, inspired by the YOLO series, includes modifications to the SPPF and C3K2 of YOLOv11 to better handle the multiscale features. In particular, we employ cross-enhanced spatial attention before the DTMB and cross-channel attention after the Fusion Mamba Block to extract more discriminative features. Experimental results on the DroneVehicle dataset show that our method outperforms the baseline OAFA method by 3.6% in the mAP metric. Codes will be released at https://github.com/GreatPlum-hnu/UAVD-Mamba.git.