 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph-Fused Vision-Language-Action for Policy Reasoning in Multi-Arm Robotic Manipulation
Sep 09, 2025



Acquiring dexterous robotic skills from human video demonstrations remains a significant challenge, largely due to conventional reliance on low-level trajectory replication, which often fails to generalize across varying objects, spatial layouts, and manipulator configurations. To address this limitation, we introduce Graph-Fused Vision-Language-Action (GF-VLA), a unified framework that enables dual-arm robotic systems to perform task-level reasoning and execution directly from RGB-D human demonstrations. GF-VLA employs an information-theoretic approach to extract task-relevant cues, selectively highlighting critical hand-object and object-object interactions. These cues are structured into temporally ordered scene graphs, which are subsequently integrated with a language-conditioned transformer to produce hierarchical behavior trees and interpretable Cartesian motion primitives. To enhance efficiency in bimanual execution, we propose a cross-arm allocation strategy that autonomously determines gripper assignment without requiring explicit geometric modeling. We validate GF-VLA on four dual-arm block assembly benchmarks involving symbolic structure construction and spatial generalization. Empirical results demonstrate that the proposed representation achieves over 95% graph accuracy and 93% subtask segmentation, enabling the language-action planner to generate robust, interpretable task policies. When deployed on a dual-arm robot, these policies attain 94% grasp reliability, 89% placement accuracy, and 90% overall task success across stacking, letter-formation, and geometric reconfiguration tasks, evidencing strong generalization and robustness under diverse spatial and semantic variations.
Exploring Non-Local Spatial-Angular Correlations with a Hybrid Mamba-Transformer Framework for Light Field Super-Resolution
Sep 05, 2025Recently, Mamba-based methods, with its advantage in long-range information modeling and linear complexity, have shown great potential in optimizing both computational cost and performance of light field image super-resolution (LFSR). However, current multi-directional scanning strategies lead to inefficient and redundant feature extraction when applied to complex LF data. To overcome this challenge, we propose a Subspace Simple Scanning (Sub-SS) strategy, based on which we design the Subspace Simple Mamba Block (SSMB) to achieve more efficient and precise feature extraction. Furthermore, we propose a dual-stage modeling strategy to address the limitation of state space in preserving spatial-angular and disparity information, thereby enabling a more comprehensive exploration of non-local spatial-angular correlations. Specifically, in stage I, we introduce the Spatial-Angular Residual Subspace Mamba Block (SA-RSMB) for shallow spatial-angular feature extraction; in stage II, we use a dual-branch parallel structure combining the Epipolar Plane Mamba Block (EPMB) and Epipolar Plane Transformer Block (EPTB) for deep epipolar feature refinement. Building upon meticulously designed modules and strategies, we introduce a hybrid Mamba-Transformer framework, termed LFMT. LFMT integrates the strengths of Mamba and Transformer models for LFSR, enabling comprehensive information exploration across spatial, angular, and epipolar-plane domains. Experimental results demonstrate that LFMT significantly outperforms current state-of-the-art methods in LFSR, achieving substantial improvements in performance while maintaining low computational complexity on both real-word and synthetic LF datasets.
Information-Theoretic Graph Fusion with Vision-Language-Action Model for Policy Reasoning and Dual Robotic Control
Aug 07, 2025Teaching robots dexterous skills from human videos remains challenging due to the reliance on low-level trajectory imitation, which fails to generalize across object types, spatial layouts, and manipulator configurations. We propose Graph-Fused Vision-Language-Action (GF-VLA), a framework that enables dual-arm robotic systems to perform task-level reasoning and execution directly from RGB and Depth human demonstrations. GF-VLA first extracts Shannon-information-based cues to identify hands and objects with the highest task relevance, then encodes these cues into temporally ordered scene graphs that capture both hand-object and object-object interactions. These graphs are fused with a language-conditioned transformer that generates hierarchical behavior trees and interpretable Cartesian motion commands. To improve execution efficiency in bimanual settings, we further introduce a cross-hand selection policy that infers optimal gripper assignment without explicit geometric reasoning. We evaluate GF-VLA on four structured dual-arm block assembly tasks involving symbolic shape construction and spatial generalization. Experimental results show that the information-theoretic scene representation achieves over 95 percent graph accuracy and 93 percent subtask segmentation, supporting the LLM planner in generating reliable and human-readable task policies. When executed by the dual-arm robot, these policies yield 94 percent grasp success, 89 percent placement accuracy, and 90 percent overall task success across stacking, letter-building, and geometric reconfiguration scenarios, demonstrating strong generalization and robustness across diverse spatial and semantic variations.
DDistill-SR: Reparameterized Dynamic Distillation Network for Lightweight Image Super-Resolution
Dec 22, 2023



Recent research on deep convolutional neural networks (CNNs) has provided a significant performance boost on efficient super-resolution (SR) tasks by trading off the performance and applicability. However, most existing methods focus on subtracting feature processing consumption to reduce the parameters and calculations without refining the immediate features, which leads to inadequate information in the restoration. In this paper, we propose a lightweight network termed DDistill-SR, which significantly improves the SR quality by capturing and reusing more helpful information in a static-dynamic feature distillation manner. Specifically, we propose a plug-in reparameterized dynamic unit (RDU) to promote the performance and inference cost trade-off. During the training phase, the RDU learns to linearly combine multiple reparameterizable blocks by analyzing varied input statistics to enhance layer-level representation. In the inference phase, the RDU is equally converted to simple dynamic convolutions that explicitly capture robust dynamic and static feature maps. Then, the information distillation block is constructed by several RDUs to enforce hierarchical refinement and selective fusion of spatial context information. Furthermore, we propose a dynamic distillation fusion (DDF) module to enable dynamic signals aggregation and communication between hierarchical modules to further improve performance. Empirical results show that our DDistill-SR outperforms the baselines and achieves state-of-the-art results on most super-resolution domains with much fewer parameters and less computational overhead. We have released the code of DDistill-SR at https://github.com/icandle/DDistill-SR.
* Accepted by IEEE Transactions on Multimedia (TMM)
Generative Artificial Intelligence in Healthcare: Ethical Considerations and Assessment Checklist
Nov 02, 2023


The widespread use of ChatGPT and other emerging technology powered by generative artificial intelligence (AI) has drawn much attention to potential ethical issues, especially in high-stakes applications such as healthcare. However, less clear is how to resolve such issues beyond following guidelines and regulations that are still under discussion and development. On the other hand, other types of generative AI have been used to synthesize images and other types of data for research and practical purposes, which have resolved some ethical issues and exposed other ethical issues, but such technology is less often the focus of ongoing ethical discussions. Here we highlight gaps in current ethical discussions of generative AI via a systematic scoping review of relevant existing research in healthcare, and reduce the gaps by proposing an ethics checklist for comprehensive assessment and transparent documentation of ethical discussions in generative AI development. While the checklist can be readily integrated into the current peer review and publication system to enhance generative AI research, it may also be used in broader settings to disclose ethics-related considerations in generative AI-powered products (or real-life applications of such products) to help users establish reasonable trust in their capabilities.
LBL: Logarithmic Barrier Loss Function for One-class Classification
Jul 20, 2023



One-class classification (OCC) aims to train a classifier only with the target class data and attracts great attention for its strong applicability in real-world application. Despite a lot of advances have been made in OCC, it still lacks the effective OCC loss functions for deep learning. In this paper, a novel logarithmic barrier function based OCC loss (LBL) that assigns large gradients to the margin samples and thus derives more compact hypersphere, is first proposed by approximating the OCC objective smoothly. But the optimization of LBL may be instability especially when samples lie on the boundary leading to the infinity loss. To address this issue, then, a unilateral relaxation Sigmoid function is introduced into LBL and a novel OCC loss named LBLSig is proposed. The LBLSig can be seen as the fusion of the mean square error (MSE) and the cross entropy (CE) and the optimization of LBLSig is smoother owing to the unilateral relaxation Sigmoid function. The effectiveness of the proposed LBL and LBLSig is experimentally demonstrated in comparisons with several state-of-the-art OCC algorithms on different network structures. The source code can be found at https://github.com/ML-HDU/LBL_LBLSig.
Random VLAD based Deep Hashing for Efficient Image Retrieval
Feb 06, 2020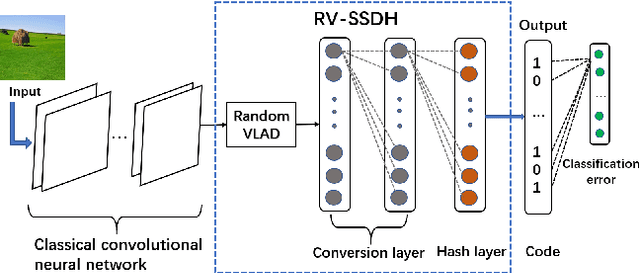
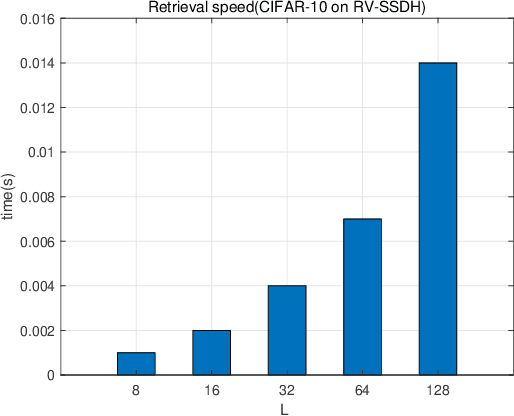
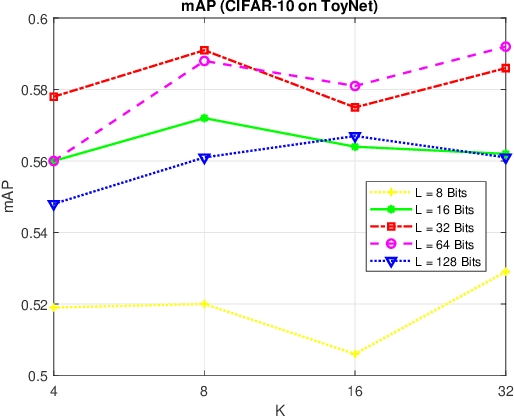
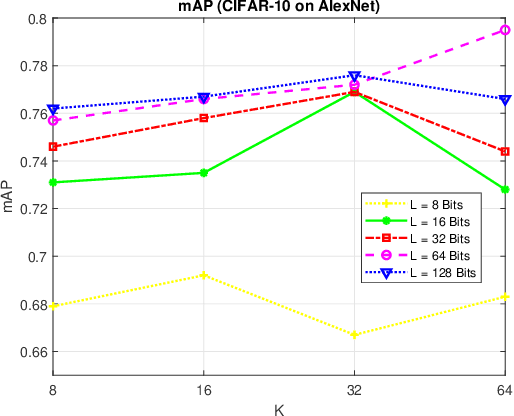
Image hash algorithms generate compact binary representations that can be quickly matched by Hamming distance, thus become an efficient solution for large-scale image retrieval. This paper proposes RV-SSDH, a deep image hash algorithm that incorporates the classical VLAD (vector of locally aggregated descriptors) architecture into neural networks. Specifically, a novel neural network component is formed by coupling a random VLAD layer with a latent hash layer through a transform layer. This component can be combined with convolutional layers to realize a hash algorithm. We implement RV-SSDH as a point-wise algorithm that can be efficiently trained by minimizing classification error and quantization loss. Comprehensive experiments show this new architecture significantly outperforms baselines such as NetVLAD and SSDH, and offers a cost-effective trade-off in the state-of-the-art. In addition, the proposed random VLAD layer leads to satisfactory accuracy with low complexity, thus shows promising potentials as an alternative to NetVLAD.