 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParkour Dataset
Papers and Code
OmniRetarget: Interaction-Preserving Data Generation for Humanoid Whole-Body Loco-Manipulation and Scene Interaction
Sep 30, 2025A dominant paradigm for teaching humanoid robots complex skills is to retarget human motions as kinematic references to train reinforcement learning (RL) policies. However, existing retargeting pipelines often struggle with the significant embodiment gap between humans and robots, producing physically implausible artifacts like foot-skating and penetration. More importantly, common retargeting methods neglect the rich human-object and human-environment interactions essential for expressive locomotion and loco-manipulation. To address this, we introduce OmniRetarget, an interaction-preserving data generation engine based on an interaction mesh that explicitly models and preserves the crucial spatial and contact relationships between an agent, the terrain, and manipulated objects. By minimizing the Laplacian deformation between the human and robot meshes while enforcing kinematic constraints, OmniRetarget generates kinematically feasible trajectories. Moreover, preserving task-relevant interactions enables efficient data augmentation, from a single demonstration to different robot embodiments, terrains, and object configurations. We comprehensively evaluate OmniRetarget by retargeting motions from OMOMO, LAFAN1, and our in-house MoCap datasets, generating over 8-hour trajectories that achieve better kinematic constraint satisfaction and contact preservation than widely used baselines. Such high-quality data enables proprioceptive RL policies to successfully execute long-horizon (up to 30 seconds) parkour and loco-manipulation skills on a Unitree G1 humanoid, trained with only 5 reward terms and simple domain randomization shared by all tasks, without any learning curriculum.
PARC: Physics-based Augmentation with Reinforcement Learning for Character Controllers
May 06, 2025



Humans excel in navigating diverse, complex environments with agile motor skills, exemplified by parkour practitioners performing dynamic maneuvers, such as climbing up walls and jumping across gaps. Reproducing these agile movements with simulated characters remains challenging, in part due to the scarcity of motion capture data for agile terrain traversal behaviors and the high cost of acquiring such data. In this work, we introduce PARC (Physics-based Augmentation with Reinforcement Learning for Character Controllers), a framework that leverages machine learning and physics-based simulation to iteratively augment motion datasets and expand the capabilities of terrain traversal controllers. PARC begins by training a motion generator on a small dataset consisting of core terrain traversal skills. The motion generator is then used to produce synthetic data for traversing new terrains. However, these generated motions often exhibit artifacts, such as incorrect contacts or discontinuities. To correct these artifacts, we train a physics-based tracking controller to imitate the motions in simulation. The corrected motions are then added to the dataset, which is used to continue training the motion generator in the next iteration. PARC's iterative process jointly expands the capabilities of the motion generator and tracker, creating agile and versatile models for interacting with complex environments. PARC provides an effective approach to develop controllers for agile terrain traversal, which bridges the gap between the scarcity of motion data and the need for versatile character controllers.
Learning to Estimate External Forces of Human Motion in Video
Jul 12, 2022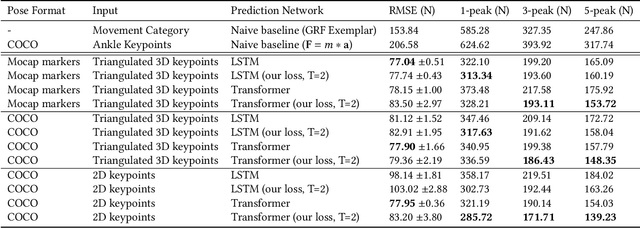


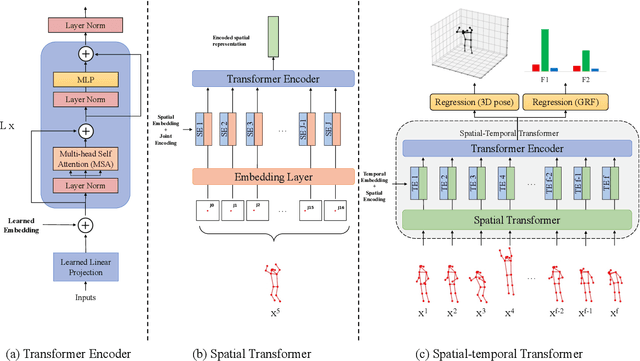
Analyzing sports performance or preventing injuries requires capturing ground reaction forces (GRFs) exerted by the human body during certain movements. Standard practice uses physical markers paired with force plates in a controlled environment, but this is marred by high costs, lengthy implementation time, and variance in repeat experiments; hence, we propose GRF inference from video. While recent work has used LSTMs to estimate GRFs from 2D viewpoints, these can be limited in their modeling and representation capacity. First, we propose using a transformer architecture to tackle the GRF from video task, being the first to do so. Then we introduce a new loss to minimize high impact peaks in regressed curves. We also show that pre-training and multi-task learning on 2D-to-3D human pose estimation improves generalization to unseen motions. And pre-training on this different task provides good initial weights when finetuning on smaller (rarer) GRF datasets. We evaluate on LAAS Parkour and a newly collected ForcePose dataset; we show up to 19% decrease in error compared to prior approaches.
Learning Multimodal Bipedal Locomotion and Implicit Transitions: A Versatile Policy Approach
Mar 10, 2023In this paper, we propose a novel framework for synthesizing a single multimodal control policy capable of generating diverse behaviors (or modes) and emergent inherent transition maneuvers for bipedal locomotion. In our method, we first learn efficient latent encodings for each behavior by training an autoencoder from a dataset of rough reference motions. These latent encodings are used as commands to train a multimodal policy through an adaptive sampling of modes and transitions to ensure consistent performance across different behaviors. We validate the policy performance in simulation for various distinct locomotion modes such as walking, leaping, jumping on a block, standing idle, and all possible combinations of inter-mode transitions. Finally, we integrate a task-based planner to rapidly generate open-loop mode plans for the trained multimodal policy to solve high-level tasks like reaching a goal position on a challenging terrain. Complex parkour-like motions by smoothly combining the discrete locomotion modes were generated in 3 min. to traverse tracks with a gap of width 0.45 m, a plateau of height 0.2 m, and a block of height 0.4 m, which are all significant compared to the dimensions of our mini-biped platform.
Estimating 3D Motion and Forces of Human-Object Interactions from Internet Videos
Nov 02, 2021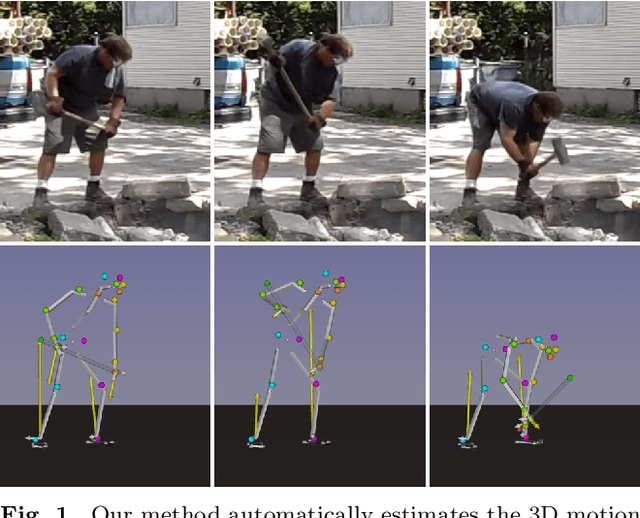

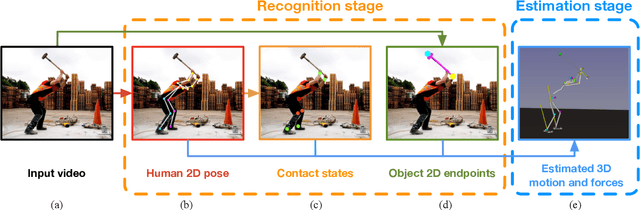

In this paper, we introduce a method to automatically reconstruct the 3D motion of a person interacting with an object from a single RGB video. Our method estimates the 3D poses of the person together with the object pose, the contact positions and the contact forces exerted on the human body. The main contributions of this work are three-fold. First, we introduce an approach to jointly estimate the motion and the actuation forces of the person on the manipulated object by modeling contacts and the dynamics of the interactions. This is cast as a large-scale trajectory optimization problem. Second, we develop a method to automatically recognize from the input video the 2D position and timing of contacts between the person and the object or the ground, thereby significantly simplifying the complexity of the optimization. Third, we validate our approach on a recent video+MoCap dataset capturing typical parkour actions, and demonstrate its performance on a new dataset of Internet videos showing people manipulating a variety of tools in unconstrained environments.
From Universal Humanoid Control to Automatic Physically Valid Character Creation
Jun 18, 2022

Automatically designing virtual humans and humanoids holds great potential in aiding the character creation process in games, movies, and robots. In some cases, a character creator may wish to design a humanoid body customized for certain motions such as karate kicks and parkour jumps. In this work, we propose a humanoid design framework to automatically generate physically valid humanoid bodies conditioned on sequence(s) of pre-specified human motions. First, we learn a generalized humanoid controller trained on a large-scale human motion dataset that features diverse human motion and body shapes. Second, we use a design-and-control framework to optimize a humanoid's physical attributes to find body designs that can better imitate the pre-specified human motion sequence(s). Leveraging the pre-trained humanoid controller and physics simulation as guidance, our method is able to discover new humanoid designs that are customized to perform pre-specified human motions.