 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasuring Physical Plausibility of 3D Human Poses Using Physics Simulation
Feb 06, 2025



Modeling humans in physical scenes is vital for understanding human-environment interactions for applications involving augmented reality or assessment of human actions from video (e.g. sports or physical rehabilitation). State-of-the-art literature begins with a 3D human pose, from monocular or multiple views, and uses this representation to ground the person within a 3D world space. While standard metrics for accuracy capture joint position errors, they do not consider physical plausibility of the 3D pose. This limitation has motivated researchers to propose other metrics evaluating jitter, floor penetration, and unbalanced postures. Yet, these approaches measure independent instances of errors and are not representative of balance or stability during motion. In this work, we propose measuring physical plausibility from within physics simulation. We introduce two metrics to capture the physical plausibility and stability of predicted 3D poses from any 3D Human Pose Estimation model. Using physics simulation, we discover correlations with existing plausibility metrics and measuring stability during motion. We evaluate and compare the performances of two state-of-the-art methods, a multi-view triangulated baseline, and ground truth 3D markers from the Human3.6m dataset.
Learning to Estimate External Forces of Human Motion in Video
Jul 12, 2022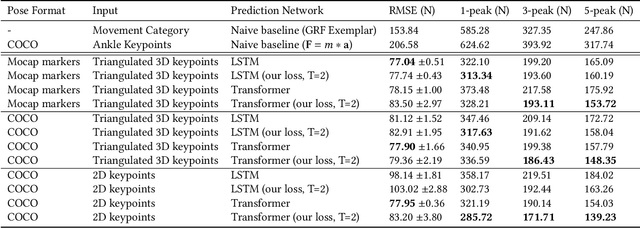


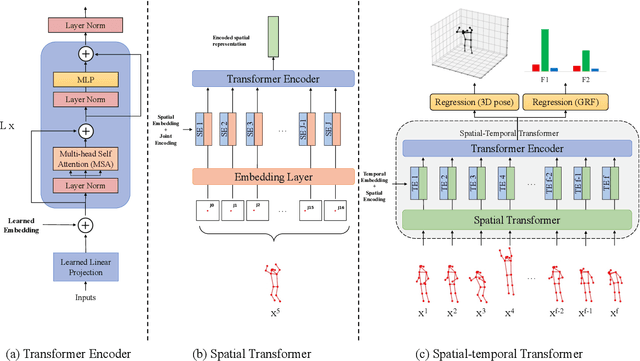
Analyzing sports performance or preventing injuries requires capturing ground reaction forces (GRFs) exerted by the human body during certain movements. Standard practice uses physical markers paired with force plates in a controlled environment, but this is marred by high costs, lengthy implementation time, and variance in repeat experiments; hence, we propose GRF inference from video. While recent work has used LSTMs to estimate GRFs from 2D viewpoints, these can be limited in their modeling and representation capacity. First, we propose using a transformer architecture to tackle the GRF from video task, being the first to do so. Then we introduce a new loss to minimize high impact peaks in regressed curves. We also show that pre-training and multi-task learning on 2D-to-3D human pose estimation improves generalization to unseen motions. And pre-training on this different task provides good initial weights when finetuning on smaller (rarer) GRF datasets. We evaluate on LAAS Parkour and a newly collected ForcePose dataset; we show up to 19% decrease in error compared to prior approaches.
Temporally Guided Articulated Hand Pose Tracking in Surgical Videos
Jan 12, 2021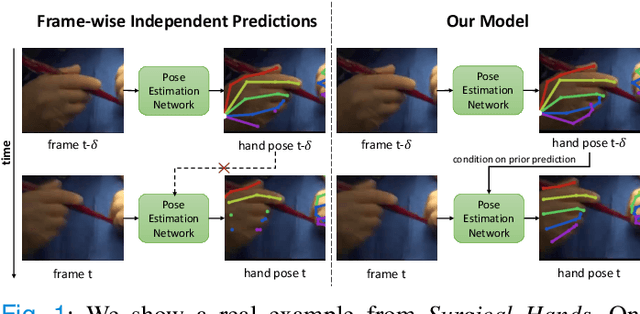
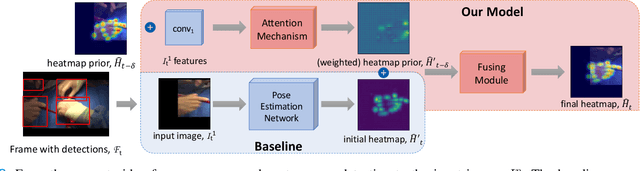
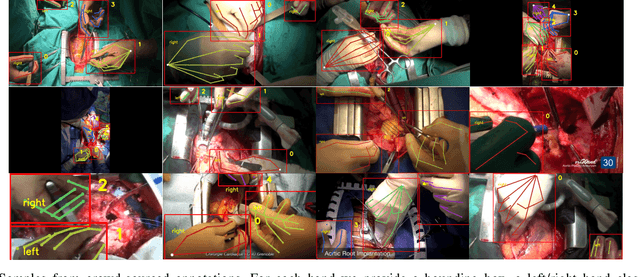
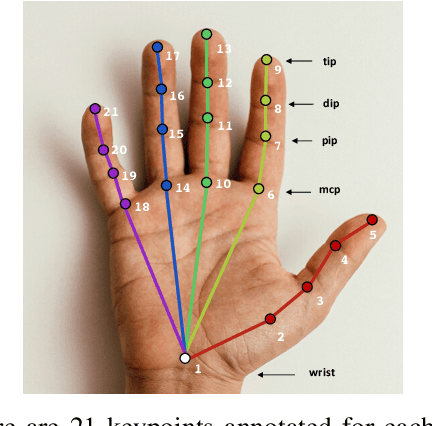
Articulated hand pose tracking is an underexplored problem that carries the potential for use in an extensive number of applications, especially in the medical domain. With a robust and accurate tracking system on in-vivo surgical videos, the motion dynamics and movement patterns of the hands can be captured and analyzed for rich tasks including skills assessment, training surgical residents, and temporal action recognition. In this work, we propose a novel hand pose estimation model, Res152- CondPose, which improves tracking accuracy by incorporating a hand pose prior into its pose prediction. We show improvements over state-of-the-art methods which provide frame-wise independent predictions, by following a temporally guided approach that effectively leverages past predictions. Additionally, we collect the first dataset, Surgical Hands, that provides multi-instance articulated hand pose annotations for in-vivo videos. Our dataset contains 76 video clips from 28 publicly available surgical videos and over 8.1k annotated hand pose instances. We provide bounding boxes, articulated hand pose annotations, and tracking IDs to enable multi-instance area-based and articulated tracking. When evaluated on Surgical Hands, we show our method outperforms the state-of-the-art method using mean Average Precision (mAP), to measure pose estimation accuracy, and Multiple Object Tracking Accuracy (MOTA), to assess pose tracking performance.
ViP: Video Platform for PyTorch
Oct 07, 2019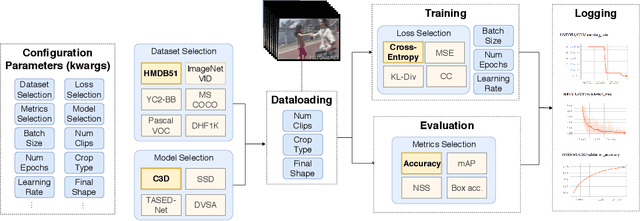

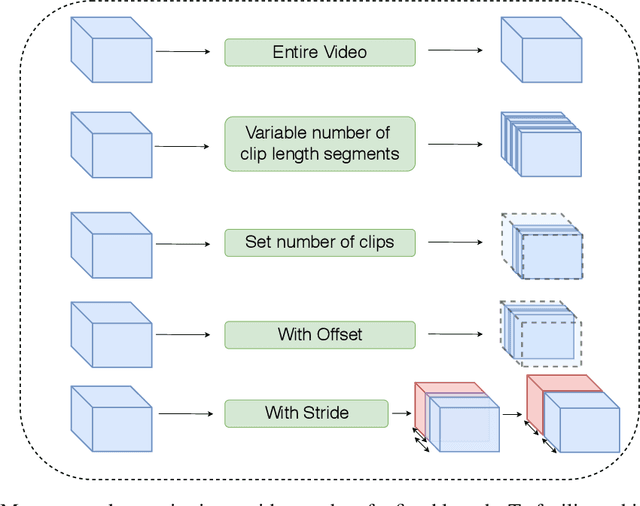
This work presents the Video Platform for PyTorch (ViP), a deep learning-based framework designed to handle and extend to any problem domain based on videos. ViP supports (1) a single unified interface applicable to all video problem domains, (2) quick prototyping of video models, (3) executing large-batch operations with reduced memory consumption, and (4) easy and reproducible experimental setups. ViP's core functionality is built with flexibility and modularity in mind to allow for smooth data flow between different parts of the platform and benchmarking against existing methods. In providing a software platform that supports multiple video-based problem domains, we allow for more cross-pollination of models, ideas and stronger generalization in the video understanding research community.
Weakly-Supervised Video Object Grounding from Text by Loss Weighting and Object Interaction
Jul 20, 2018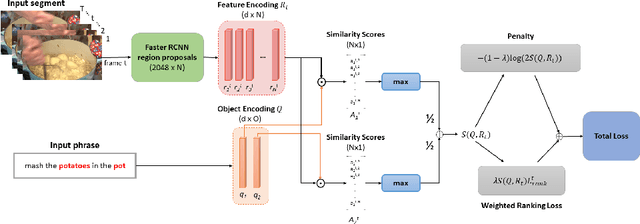
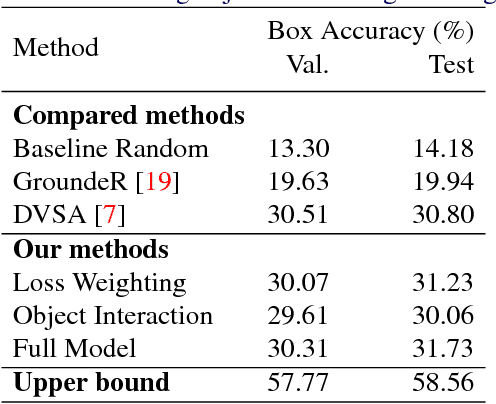
We study weakly-supervised video object grounding: given a video segment and a corresponding descriptive sentence, the goal is to localize objects that are mentioned from the sentence in the video. During training, no object bounding boxes are available, but the set of possible objects to be grounded is known beforehand. Existing approaches in the image domain use Multiple Instance Learning (MIL) to ground objects by enforcing matches between visual and semantic features. A naive extension of this approach to the video domain is to treat the entire segment as a bag of spatial object proposals. However, an object existing sparsely across multiple frames might not be detected completely since successfully spotting it from one single frame would trigger a satisfactory match. To this end, we propagate the weak supervisory signal from the segment level to frames that likely contain the target object. For frames that are unlikely to contain the target objects, we use an alternative penalty loss. We also leverage the interactions among objects as a textual guide for the grounding. We evaluate our model on the newly-collected benchmark YouCook2-BoundingBox and show improvements over competitive baselines.