 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne Stage Anchor Free Oriented Object Detection
Papers and Code
HA-RDet: Hybrid Anchor Rotation Detector for Oriented Object Detection
Dec 18, 2024



Oriented object detection in aerial images poses a significant challenge due to their varying sizes and orientations. Current state-of-the-art detectors typically rely on either two-stage or one-stage approaches, often employing Anchor-based strategies, which can result in computationally expensive operations due to the redundant number of generated anchors during training. In contrast, Anchor-free mechanisms offer faster processing but suffer from a reduction in the number of training samples, potentially impacting detection accuracy. To address these limitations, we propose the Hybrid-Anchor Rotation Detector (HA-RDet), which combines the advantages of both anchor-based and anchor-free schemes for oriented object detection. By utilizing only one preset anchor for each location on the feature maps and refining these anchors with our Orientation-Aware Convolution technique, HA-RDet achieves competitive accuracies, including 75.41 mAP on DOTA-v1, 65.3 mAP on DIOR-R, and 90.2 mAP on HRSC2016, against current anchor-based state-of-the-art methods, while significantly reducing computational resources.
DAFNe: A One-Stage Anchor-Free Deep Model for Oriented Object Detection
Sep 22, 2021
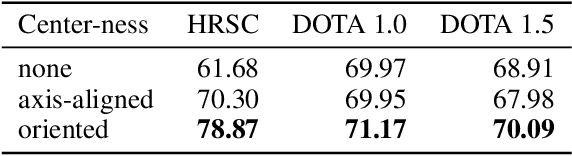
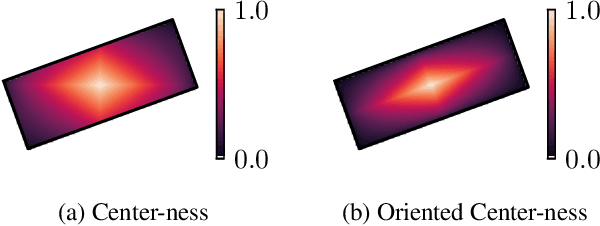
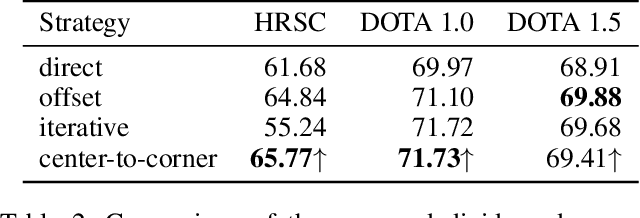
Object detection is a fundamental task in computer vision. While approaches for axis-aligned bounding box detection have made substantial progress in recent years, they perform poorly on oriented objects which are common in several real-world scenarios such as aerial view imagery and security camera footage. In these cases, a large part of a predicted bounding box will, undesirably, cover non-object related areas. Therefore, oriented object detection has emerged with the aim of generalizing object detection to arbitrary orientations. This enables a tighter fit to oriented objects, leading to a better separation of bounding boxes especially in case of dense object distributions. The vast majority of the work in this area has focused on complex two-stage anchor-based approaches. Anchors act as priors on the bounding box shape and require attentive hyper-parameter fine-tuning on a per-dataset basis, increased model size, and come with computational overhead. In this work, we present DAFNe: A Dense one-stage Anchor-Free deep Network for oriented object detection. As a one-stage model, DAFNe performs predictions on a dense grid over the input image, being architecturally simpler and faster, as well as easier to optimize than its two-stage counterparts. Furthermore, as an anchor-free model, DAFNe reduces the prediction complexity by refraining from employing bounding box anchors. Moreover, we introduce an orientation-aware generalization of the center-ness function for arbitrarily oriented bounding boxes to down-weight low-quality predictions and a center-to-corner bounding box prediction strategy that improves object localization performance. DAFNe improves the prediction accuracy over the previous best one-stage anchor-free model results on DOTA 1.0 by 4.65% mAP, setting the new state-of-the-art results by achieving 76.95% mAP.
TricubeNet: 2D Kernel-Based Object Representation for Weakly-Occluded Oriented Object Detection
Apr 23, 2021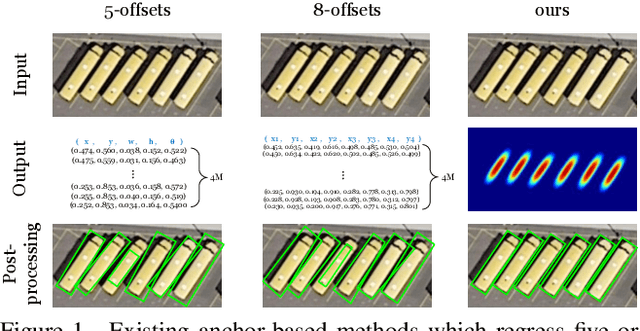
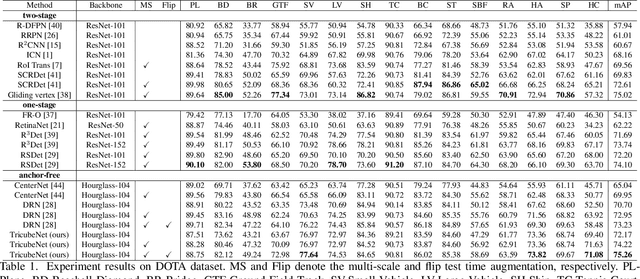
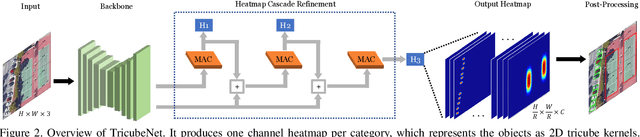
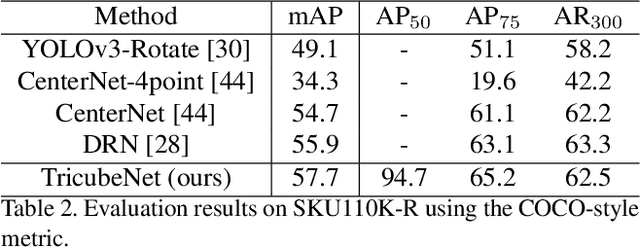
We present a new approach for oriented object detection, an anchor-free one-stage detector. This approach, named TricubeNet, represents each object as a 2D Tricube kernel and extracts bounding boxes using appearance-based post-processing. Unlike existing anchor-based oriented object detectors, we can save the computational complexity and the number of hyperparameters by eliminating the anchor box in the network design. In addition, by adopting a heatmap-based detection process instead of the box offset regression, we simply and effectively solve the angle discontinuity problem, which is one of the important problems for oriented object detection. To further boost the performance, we propose some effective techniques for the loss balancing, extracting the rotation-invariant feature, and heatmap refinement. To demonstrate the effectiveness of our TricueNet, we experiment on various tasks for the weakly-occluded oriented object detection. The extensive experimental results show that our TricueNet is highly effective and competitive for oriented object detection. The code is available at https://github.com/qjadud1994/TricubeNet.
FCOSR: A Simple Anchor-free Rotated Detector for Aerial Object Detection
Dec 01, 2021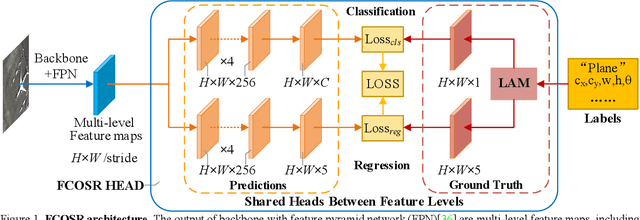

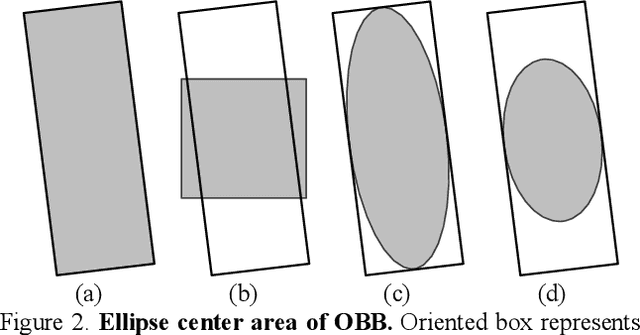

Existing anchor-base oriented object detection methods have achieved amazing results, but these methods require some manual preset boxes, which introduces additional hyperparameters and calculations. The existing anchor-free methods usually have complex architectures and are not easy to deploy. Our goal is to propose an algorithm which is simple and easy-to-deploy for aerial image detection. In this paper, we present a one-stage anchor-free rotated object detector (FCOSR) based on FCOS, which can be deployed on most platforms. The FCOSR has a simple architecture consisting of only convolution layers. Our work focuses on the label assignment strategy for the training phase. We use ellipse center sampling method to define a suitable sampling region for oriented bounding box (OBB). The fuzzy sample assignment strategy provides reasonable labels for overlapping objects. To solve the insufficient sampling problem, a multi-level sampling module is designed. These strategies allocate more appropriate labels to training samples. Our algorithm achieves 79.25, 75.41, and 90.15 mAP on DOTA1.0, DOTA1.5, and HRSC2016 datasets, respectively. FCOSR demonstrates superior performance to other methods in single-scale evaluation. We convert a lightweight FCOSR model to TensorRT format, which achieves 73.93 mAP on DOTA1.0 at a speed of 10.68 FPS on Jetson Xavier NX with single scale. The code is available at: https://github.com/lzh420202/FCOSR
IENet: Interacting Embranchment One Stage Anchor Free Detector for Orientation Aerial Object Detection
Dec 02, 2019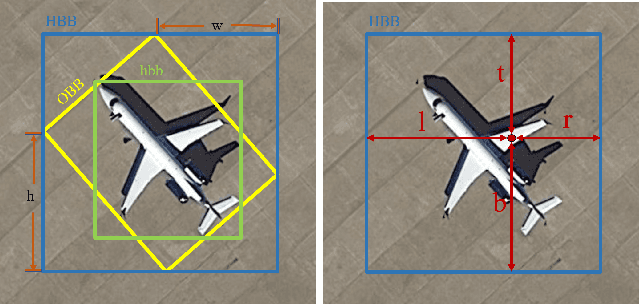
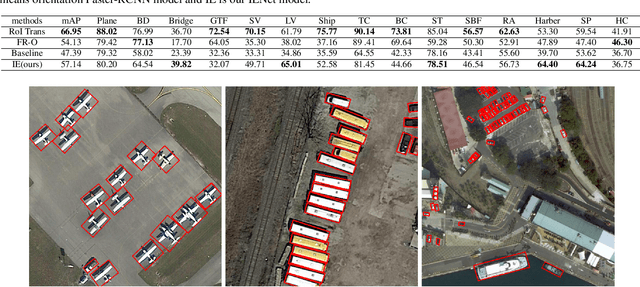
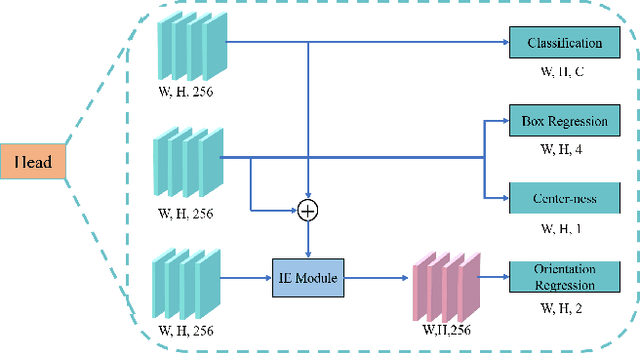
Object detection in aerial images is a challenging task due to its lack of visiable features and variant orientation of objects. Currently, amount of R-CNN framework based detectors have made significant progress in predicting targets by horizontal bounding boxes (HBB) and oriented bounding boxes (OBB). However, there is still open space for one-stage anchor free solutions. This paper proposes a one-stage anchor free detector for orientional object in aerial images, which is built upon a per-pixel prediction fashion detector. We make it possible by developing a branch interacting module with a self-attention mechanism to fuse features from classification and box regression branchs. Moreover a geometric transformation is employed in angle prediction to make it more manageable for the prediction network. We also introduce an IOU loss for OBB detection, which is more efficient than regular polygon IOU. The propsed method is evaluated on DOTA and HRSC2016 datasets, and the outcomes show the higher OBB detection performance from our propsed IENet when compared with the state-of-the-art detectors.
Oriented Objects as pairs of Middle Lines
Dec 24, 2019
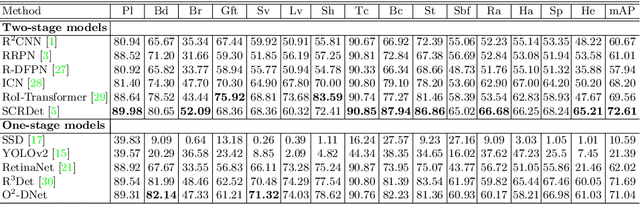
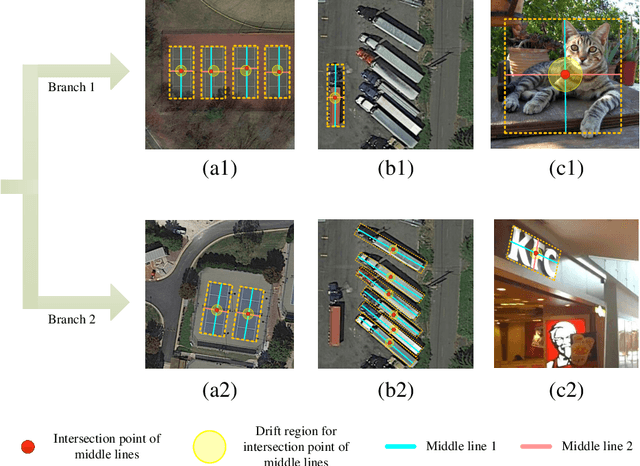
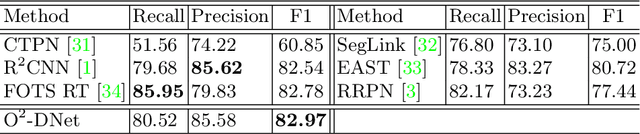
The detection of oriented objects is frequently appeared in the field of natural scene text detection as well as object detection in aerial images. Traditional detectors for oriented objects are common to rotate anchors on the basis of the RCNN frameworks, which will multiple the number of anchors with a variety of angles, coupled with rotating NMS algorithm, the computational complexities of these models are greatly increased. In this paper, we propose a novel model named Oriented Objects Detection Network O^2-DNet to detect oriented objects by predicting a pair of middle lines inside each target. O^2-DNet is an one-stage, anchor-free and NMS-free model. The target line segments of our model are defined as two corresponding middle lines of original rotating bounding box annotations which can be transformed directly instead of additional manual tagging. Experiments show that our O^2-DNet achieves excellent performance on ICDAR 2015 and DOTA datasets. It is noteworthy that the objects in COCO can be regard as a special form of oriented objects with an angle of 90 degrees. O^2-DNet can still achieve competitive results in these general natural object detection datasets.
Object as Hotspots: An Anchor-Free 3D Object Detection Approach via Firing of Hotspots
Dec 30, 2019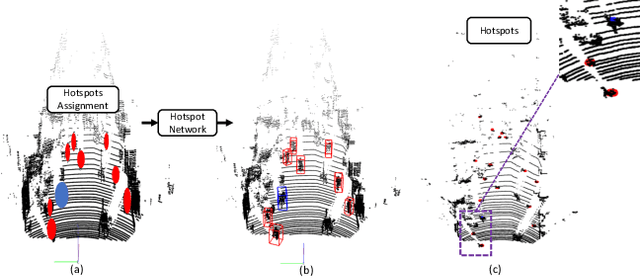
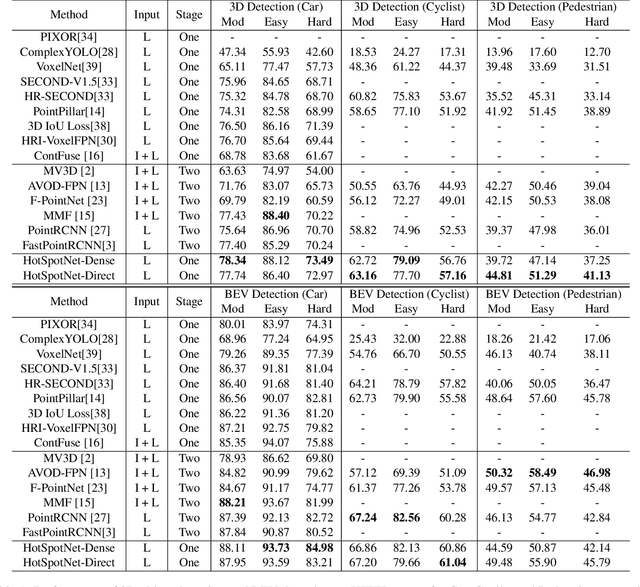
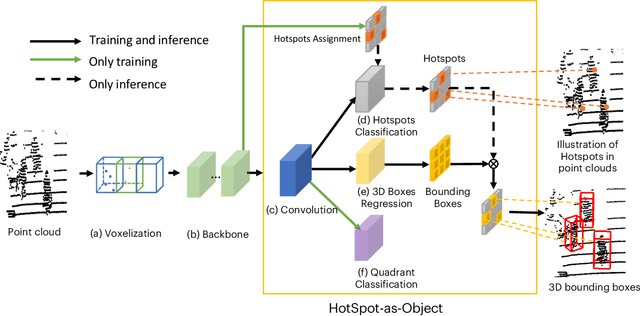
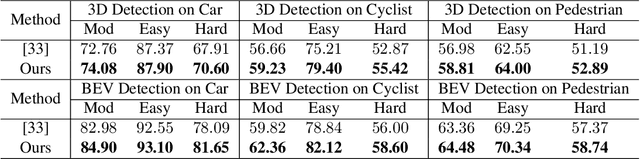
Accurate 3D object detection in LiDAR based point clouds suffers from the challenges of data sparsity and irregularities. Existing methods strive to organize the points regularly, e.g. voxelize, pass them through a designed 2D/3D neural network, and then define object-level anchors that predict offsets of 3D bounding boxes using collective evidence from all the points on the objects of interest. Converse to the state-of-the-art anchor-based methods, based on the very same nature of data sparsity and irregularities, we observe that even points on an isolated object part are informative about position and orientation of the object. We thus argue in this paper for an approach opposite to existing methods using object-level anchors. Technically, we propose to represent an object as a collection of point cliques; one can intuitively think of these point cliques as hotspots, giving rise to the representation of Object as Hotspots (OHS). Based on OHS, we propose a Hotspot Network (HotSpotNet) that performs 3D object detection via firing of hotspots without setting the predefined bounding boxes. A distinctive feature of HotSpotNet is that it makes predictions directly from individual hotspots, and final results are obtained by aggregating these hotspot predictions. Experiments on the KITTI benchmark show the efficacy of our proposed OHS representation. Our one-stage, anchor-free HotSpotNet beats all other one-stage detectors by at least 2% on cars , cyclists and pedestrian for all difficulty levels. Notably, our proposed method performs better on small and difficult objects and we rank the first among all the submitted methods on pedestrian of KITTI test set.