 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClaimDiff-RL: Fine-Grained Caption Reinforcement Learning through Visual Claim Comparison
May 19, 2026Long-form image captioning exposes a reward granularity problem in RL: captions are judged as whole sequences, while the important errors occur at the level of individual visual claims. A good dense caption should be both faithful and informative, avoiding hallucination without omitting salient details. Yet pairwise preferences, reference-based metrics, and holistic scalar rewards compress these local errors into a single sequence-level signal, obscuring the tradeoff between factuality and coverage. We introduce ClaimDiff-RL, a framework that uses reference-conditioned atomic claim differences as the reward unit for caption RL. Given an image, an actor caption, and a reference caption, a multimodal judge enumerates visually grounded differences, verifies each difference against the image, assigns open-vocabulary error types and severity levels, and produces per-difference statistics for reward composition. This makes hallucinated claims and omitted salient facts separately measurable and tunable. Experiments show that holistic scalar rewards can reduce hallucination by increasing missing facts, while ClaimDiff-RL exposes this faithfulness and coverage tradeoff and enables more balanced operating points. On a 160-image human-labeled diagnostic benchmark, public captioning benchmarks, and VQA benchmarks, ClaimDiff-RL improves the hallucination--missing-fact balance, preserves general capability, and even surpasses Gemini-3-Pro-Preview on several fine-grained Capability dimensions such as object counting, spatial relations, and scene recognition. These results suggest that typed, verifiable claim differences are an effective reward unit for fine-grained and diagnosable caption RL.
Oriented Objects as pairs of Middle Lines
Dec 24, 2019
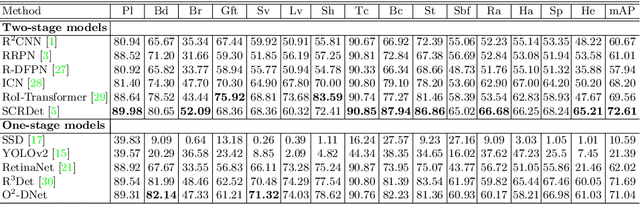
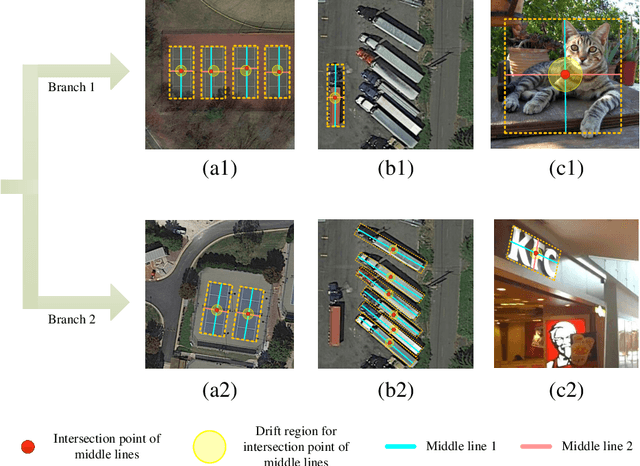
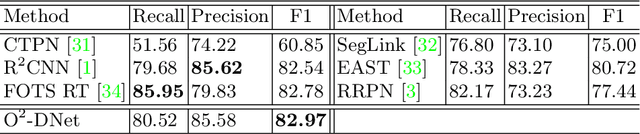
The detection of oriented objects is frequently appeared in the field of natural scene text detection as well as object detection in aerial images. Traditional detectors for oriented objects are common to rotate anchors on the basis of the RCNN frameworks, which will multiple the number of anchors with a variety of angles, coupled with rotating NMS algorithm, the computational complexities of these models are greatly increased. In this paper, we propose a novel model named Oriented Objects Detection Network O^2-DNet to detect oriented objects by predicting a pair of middle lines inside each target. O^2-DNet is an one-stage, anchor-free and NMS-free model. The target line segments of our model are defined as two corresponding middle lines of original rotating bounding box annotations which can be transformed directly instead of additional manual tagging. Experiments show that our O^2-DNet achieves excellent performance on ICDAR 2015 and DOTA datasets. It is noteworthy that the objects in COCO can be regard as a special form of oriented objects with an angle of 90 degrees. O^2-DNet can still achieve competitive results in these general natural object detection datasets.