 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNvbench
Papers and Code
Aligning Text, Code, and Vision: A Multi-Objective Reinforcement Learning Framework for Text-to-Visualization
Jan 08, 2026Text-to-Visualization (Text2Vis) systems translate natural language queries over tabular data into concise answers and executable visualizations. While closed-source LLMs generate functional code, the resulting charts often lack semantic alignment and clarity, qualities that can only be assessed post-execution. Open-source models struggle even more, frequently producing non-executable or visually poor outputs. Although supervised fine-tuning can improve code executability, it fails to enhance overall visualization quality, as traditional SFT loss cannot capture post-execution feedback. To address this gap, we propose RL-Text2Vis, the first reinforcement learning framework for Text2Vis generation. Built on Group Relative Policy Optimization (GRPO), our method uses a novel multi-objective reward that jointly optimizes textual accuracy, code validity, and visualization quality using post-execution feedback. By training Qwen2.5 models (7B and 14B), RL-Text2Vis achieves a 22% relative improvement in chart quality over GPT-4o on the Text2Vis benchmark and boosts code execution success from 78% to 97% relative to its zero-shot baseline. Our models significantly outperform strong zero-shot and supervised baselines and also demonstrate robust generalization to out-of-domain datasets like VIS-Eval and NVBench. These results establish GRPO as an effective strategy for structured, multimodal reasoning in visualization generation. We release our code at https://github.com/vis-nlp/RL-Text2Vis.
nvBench 2.0: A Benchmark for Natural Language to Visualization under Ambiguity
Mar 17, 2025Natural Language to Visualization (NL2VIS) enables users to create visualizations from natural language queries, making data insights more accessible. However, NL2VIS faces challenges in interpreting ambiguous queries, as users often express their visualization needs in imprecise language. To address this challenge, we introduce nvBench 2.0, a new benchmark designed to evaluate NL2VIS systems in scenarios involving ambiguous queries. nvBench 2.0 includes 7,878 natural language queries and 24,076 corresponding visualizations, derived from 780 tables across 153 domains. It is built using a controlled ambiguity-injection pipeline that generates ambiguous queries through a reverse-generation workflow. By starting with unambiguous seed visualizations and selectively injecting ambiguities, the pipeline yields multiple valid interpretations for each query, with each ambiguous query traceable to its corresponding visualization through step-wise reasoning paths. We evaluate various Large Language Models (LLMs) on their ability to perform ambiguous NL2VIS tasks using nvBench 2.0. We also propose Step-NL2VIS, an LLM-based model trained on nvBench 2.0, which enhances performance in ambiguous scenarios through step-wise preference optimization. Our results show that Step-NL2VIS outperforms all baselines, setting a new state-of-the-art for ambiguous NL2VIS tasks.
Automated Data Visualization from Natural Language via Large Language Models: An Exploratory Study
Apr 26, 2024The Natural Language to Visualization (NL2Vis) task aims to transform natural-language descriptions into visual representations for a grounded table, enabling users to gain insights from vast amounts of data. Recently, many deep learning-based approaches have been developed for NL2Vis. Despite the considerable efforts made by these approaches, challenges persist in visualizing data sourced from unseen databases or spanning multiple tables. Taking inspiration from the remarkable generation capabilities of Large Language Models (LLMs), this paper conducts an empirical study to evaluate their potential in generating visualizations, and explore the effectiveness of in-context learning prompts for enhancing this task. In particular, we first explore the ways of transforming structured tabular data into sequential text prompts, as to feed them into LLMs and analyze which table content contributes most to the NL2Vis. Our findings suggest that transforming structured tabular data into programs is effective, and it is essential to consider the table schema when formulating prompts. Furthermore, we evaluate two types of LLMs: finetuned models (e.g., T5-Small) and inference-only models (e.g., GPT-3.5), against state-of-the-art methods, using the NL2Vis benchmarks (i.e., nvBench). The experimental results reveal that LLMs outperform baselines, with inference-only models consistently exhibiting performance improvements, at times even surpassing fine-tuned models when provided with certain few-shot demonstrations through in-context learning. Finally, we analyze when the LLMs fail in NL2Vis, and propose to iteratively update the results using strategies such as chain-of-thought, role-playing, and code-interpreter. The experimental results confirm the efficacy of iterative updates and hold great potential for future study.
Towards Robustness of Text-to-Visualization Translation against Lexical and Phrasal Variability
Apr 11, 2024



Text-to-Vis is an emerging task in the natural language processing (NLP) area that aims to automatically generate data visualizations from natural language questions (NLQs). Despite their progress, existing text-to-vis models often heavily rely on lexical matching between words in the questions and tokens in data schemas. This overreliance on lexical matching may lead to a diminished level of model robustness against input variations. In this study, we thoroughly examine the robustness of current text-to-vis models, an area that has not previously been explored. In particular, we construct the first robustness dataset nvBench-Rob, which contains diverse lexical and phrasal variations based on the original text-to-vis benchmark nvBench. Then, we found that the performance of existing text-to-vis models on this new dataset dramatically drops, implying that these methods exhibit inadequate robustness overall. Finally, we propose a novel framework based on Retrieval-Augmented Generation (RAG) technique, named GRED, specifically designed to address input perturbations in these two variants. The framework consists of three parts: NLQ-Retrieval Generator, Visualization Query-Retrieval Retuner and Annotation-based Debugger, which are used to tackle the challenges posed by natural language variants, programming style differences and data schema variants, respectively. Extensive experimental evaluations show that, compared to the state-of-the-art model RGVisNet in the Text-to-Vis field, GRED performs better in terms of model robustness, with a 32% increase in accuracy on the proposed nvBench-Rob dataset.
Natural Language Models for Data Visualization Utilizing nvBench Dataset
Oct 02, 2023Translation of natural language into syntactically correct commands for data visualization is an important application of natural language models and could be leveraged to many different tasks. A closely related effort is the task of translating natural languages into SQL queries, which in turn could be translated into visualization with additional information from the natural language query supplied\cite{Zhong:2017qr}. Contributing to the progress in this area of research, we built natural language translation models to construct simplified versions of data and visualization queries in a language called Vega Zero. In this paper, we explore the design and performance of these sequence to sequence transformer based machine learning model architectures using large language models such as BERT as encoders to predict visualization commands from natural language queries, as well as apply available T5 sequence to sequence models to the problem for comparison.
Marrying Dialogue Systems with Data Visualization: Interactive Data Visualization Generation from Natural Language Conversations
Jul 29, 2023



Data visualization (DV) has become the prevailing tool in the market due to its effectiveness into illustrating insights in vast amounts of data. To lower the barrier of using DVs, automatic DV tasks, such as natural language question (NLQ) to visualization translation (formally called text-to-vis), have been investigated in the research community. However, text-to-vis assumes the NLQ to be well-organized and expressed in a single sentence. However, in real-world settings, complex DV is needed through consecutive exchanges between the DV system and the users. In this paper, we propose a new task named CoVis, short for Conversational text-to-Visualization, aiming at constructing DVs through a series of interactions between users and the system. Since it is the task which has not been studied in the literature, we first build a benchmark dataset named Dial-NVBench, including dialogue sessions with a sequence of queries from a user and responses from the system. Then, we propose a multi-modal neural network named MMCoVisNet to answer these DV-related queries. In particular, MMCoVisNet first fully understands the dialogue context and determines the corresponding responses. Then, it uses adaptive decoders to provide the appropriate replies: (i) a straightforward text decoder is used to produce general responses, (ii) an SQL-form decoder is applied to synthesize data querying responses, and (iii) a DV-form decoder tries to construct the appropriate DVs. We comparatively evaluate MMCoVisNet with other baselines over our proposed benchmark dataset. Experimental results validate that MMCoVisNet performs better than existing baselines and achieves a state-of-the-art performance.
nvBench: A Large-Scale Synthesized Dataset for Cross-Domain Natural Language to Visualization Task
Dec 24, 2021
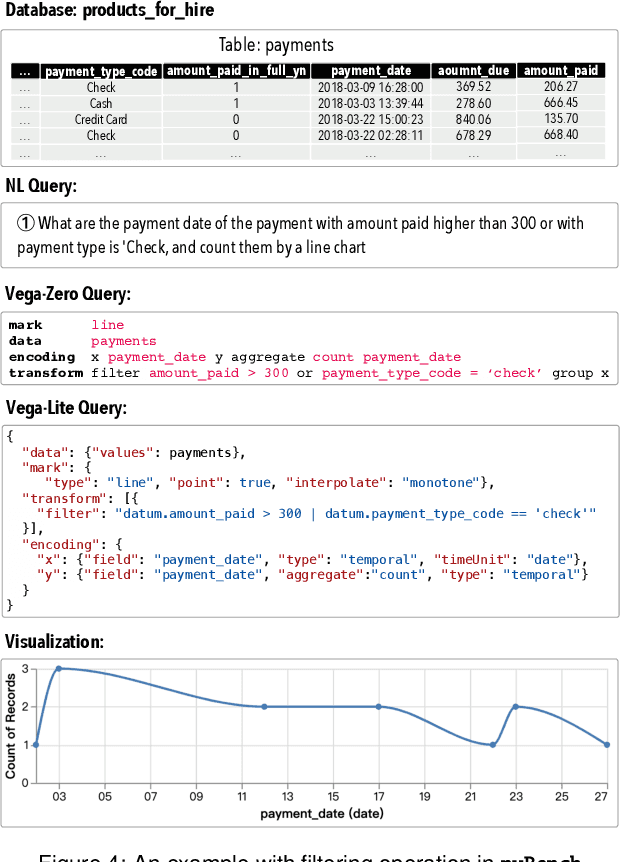

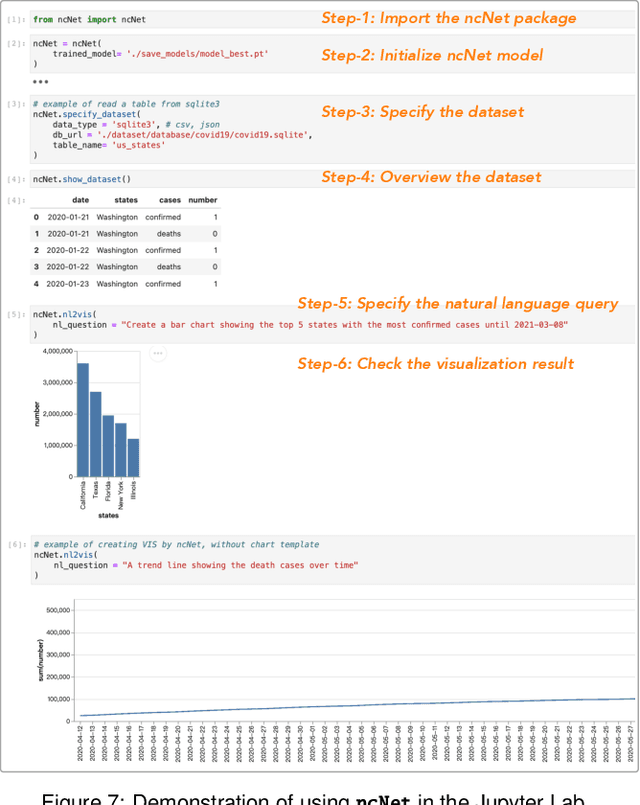
NL2VIS - which translates natural language (NL) queries to corresponding visualizations (VIS) - has attracted more and more attention both in commercial visualization vendors and academic researchers. In the last few years, the advanced deep learning-based models have achieved human-like abilities in many natural language processing (NLP) tasks, which clearly tells us that the deep learning-based technique is a good choice to push the field of NL2VIS. However, a big balk is the lack of benchmarks with lots of (NL, VIS) pairs. We present nvBench, the first large-scale NL2VIS benchmark, containing 25,750 (NL, VIS) pairs from 750 tables over 105 domains, synthesized from (NL, SQL) benchmarks to support cross-domain NL2VIS task. The quality of nvBench has been extensively validated by 23 experts and 300+ crowd workers. Deep learning-based models training using nvBench demonstrate that nvBench can push the field of NL2VIS.