 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNegative Flip Rate
Papers and Code
Rate or Fate? RLV$^\varepsilon$R: Reinforcement Learning with Verifiable Noisy Rewards
Jan 07, 2026Reinforcement learning with verifiable rewards (RLVR) is a simple but powerful paradigm for training LLMs: sample a completion, verify it, and update. In practice, however, the verifier is almost never clean--unit tests probe only limited corner cases; human and synthetic labels are imperfect; and LLM judges (e.g., RLAIF) are noisy and can be exploited--and this problem worsens on harder domains (especially coding) where tests are sparse and increasingly model-generated. We ask a pragmatic question: does the verification noise merely slow down the learning (rate), or can it flip the outcome (fate)? To address this, we develop an analytically tractable multi-armed bandit view of RLVR dynamics, instantiated with GRPO and validated in controlled experiments. Modeling false positives and false negatives and grouping completions into recurring reasoning modes yields a replicator-style (natural-selection) flow on the probability simplex. The dynamics decouples into within-correct-mode competition and a one-dimensional evolution for the mass on incorrect modes, whose drift is determined solely by Youden's index J=TPR-FPR. This yields a sharp phase transition: when J>0, the incorrect mass is driven toward extinction (learning); when J=0, the process is neutral; and when J<0, incorrect modes amplify until they dominate (anti-learning and collapse). In the learning regime J>0, noise primarily rescales convergence time ("rate, not fate"). Experiments on verifiable programming tasks under synthetic noise reproduce the predicted J=0 boundary. Beyond noise, the framework offers a general lens for analyzing RLVR stability, convergence, and algorithmic interventions.
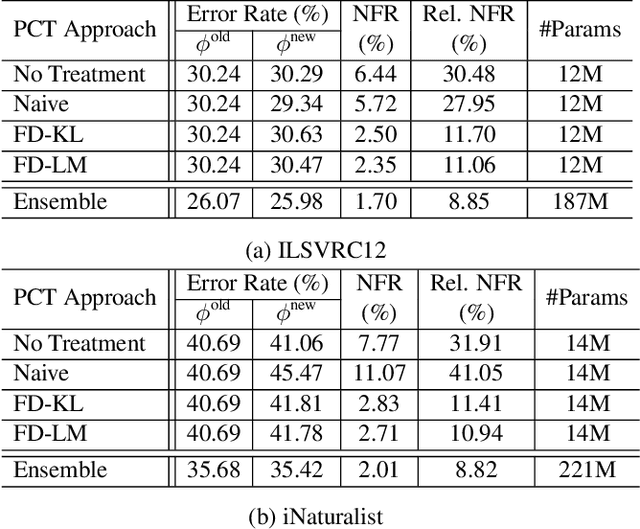
Mitigating Negative Flips via Margin Preserving Training
Nov 15, 2025Minimizing inconsistencies across successive versions of an AI system is as crucial as reducing the overall error. In image classification, such inconsistencies manifest as negative flips, where an updated model misclassifies test samples that were previously classified correctly. This issue becomes increasingly pronounced as the number of training classes grows over time, since adding new categories reduces the margin of each class and may introduce conflicting patterns that undermine their learning process, thereby degrading performance on the original subset. To mitigate negative flips, we propose a novel approach that preserves the margins of the original model while learning an improved one. Our method encourages a larger relative margin between the previously learned and newly introduced classes by introducing an explicit margin-calibration term on the logits. However, overly constraining the logit margin for the new classes can significantly degrade their accuracy compared to a new independently trained model. To address this, we integrate a double-source focal distillation loss with the previous model and a new independently trained model, learning an appropriate decision margin from both old and new data, even under a logit margin calibration. Extensive experiments on image classification benchmarks demonstrate that our approach consistently reduces the negative flip rate with high overall accuracy.
Targeting Negative Flips in Active Learning using Validation Sets
Nov 16, 2024The performance of active learning algorithms can be improved in two ways. The often used and intuitive way is by reducing the overall error rate within the test set. The second way is to ensure that correct predictions are not forgotten when the training set is increased in between rounds. The former is measured by the accuracy of the model and the latter is captured in negative flips between rounds. Negative flips are samples that are correctly predicted when trained with the previous/smaller dataset and incorrectly predicted after additional samples are labeled. In this paper, we discuss improving the performance of active learning algorithms both in terms of prediction accuracy and negative flips. The first observation we make in this paper is that negative flips and overall error rates are decoupled and reducing one does not necessarily imply that the other is reduced. Our observation is important as current active learning algorithms do not consider negative flips directly and implicitly assume the opposite. The second observation is that performing targeted active learning on subsets of the unlabeled pool has a significant impact on the behavior of the active learning algorithm and influences both negative flips and prediction accuracy. We then develop ROSE - a plug-in algorithm that utilizes a small labeled validation set to restrict arbitrary active learning acquisition functions to negative flips within the unlabeled pool. We show that integrating a validation set results in a significant performance boost in terms of accuracy, negative flip rate reduction, or both.
ELODI: Ensemble Logit Difference Inhibition for Positive-Congruent Training
May 13, 2022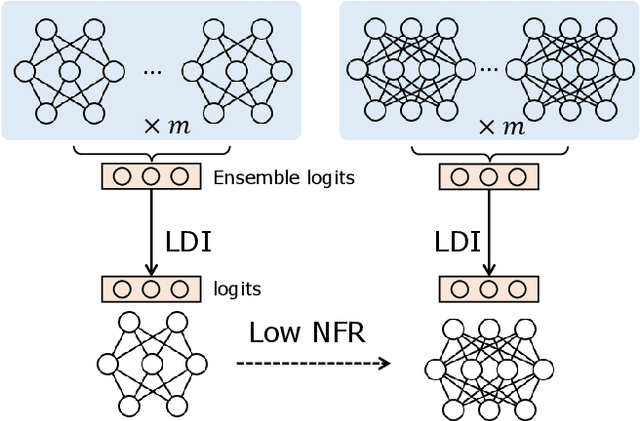
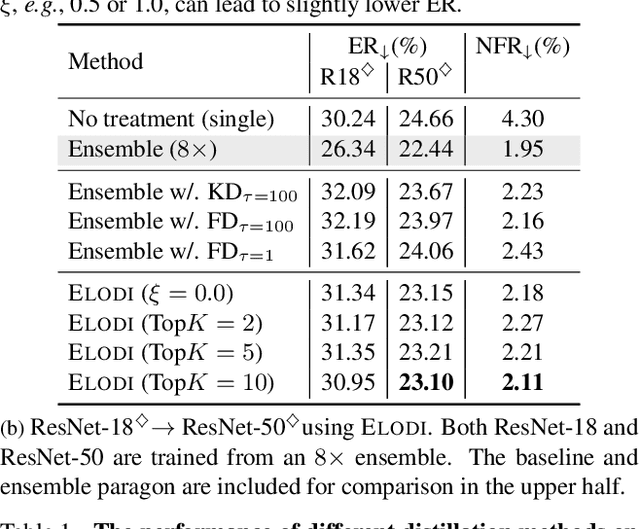
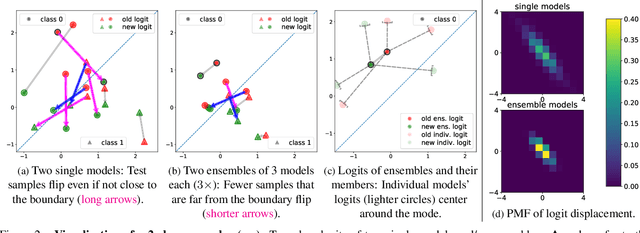
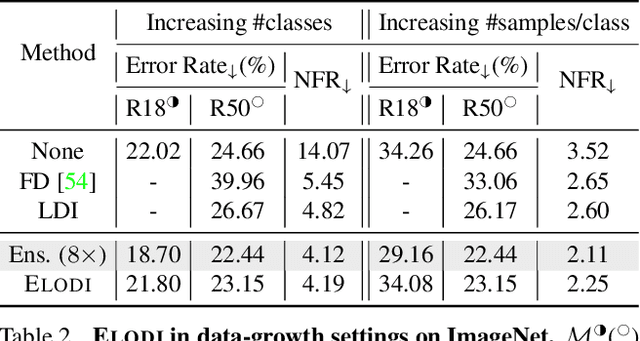
Negative flips are errors introduced in a classification system when a legacy model is replaced with a new one. Existing methods to reduce the negative flip rate (NFR) either do so at the expense of overall accuracy using model distillation, or use ensembles, which multiply inference cost prohibitively. We present a method to train a classification system that achieves paragon performance in both error rate and NFR, at the inference cost of a single model. Our method introduces a generalized distillation objective, Logit Difference Inhibition (LDI), that penalizes changes in the logits between the new and old model, without forcing them to coincide as in ordinary distillation. LDI affords the model flexibility to reduce error rate along with NFR. The method uses a homogeneous ensemble as the reference model for LDI, hence the name Ensemble LDI, or ELODI. The reference model can then be substituted with a single model at inference time. The method leverages the observation that negative flips are typically not close to the decision boundary, but often exhibit large deviations in the distance among their logits, which are reduced by ELODI.
Regression Bugs Are In Your Model! Measuring, Reducing and Analyzing Regressions In NLP Model Updates
May 07, 2021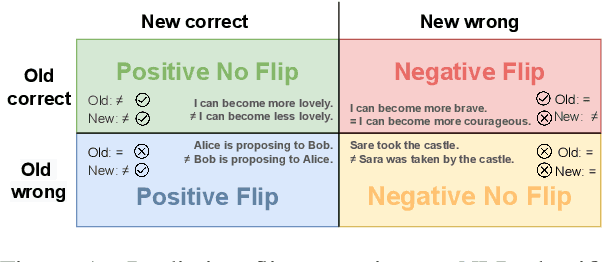
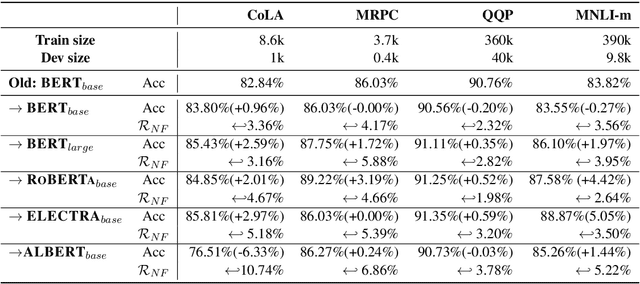
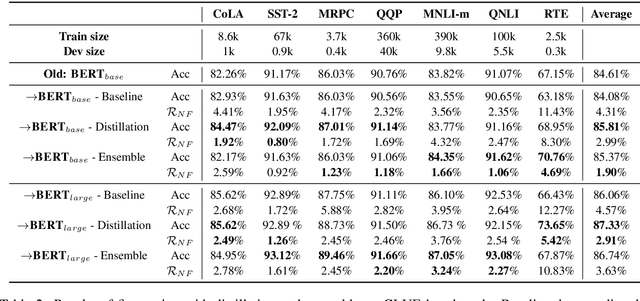
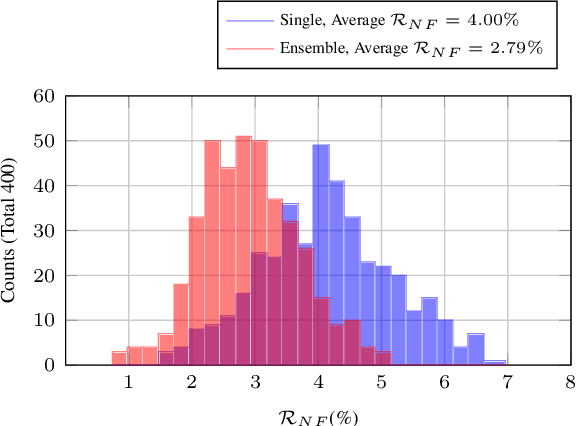
Behavior of deep neural networks can be inconsistent between different versions. Regressions during model update are a common cause of concern that often over-weigh the benefits in accuracy or efficiency gain. This work focuses on quantifying, reducing and analyzing regression errors in the NLP model updates. Using negative flip rate as regression measure, we show that regression has a prevalent presence across tasks in the GLUE benchmark. We formulate the regression-free model updates into a constrained optimization problem, and further reduce it into a relaxed form which can be approximately optimized through knowledge distillation training method. We empirically analyze how model ensemble reduces regression. Finally, we conduct CheckList behavioral testing to understand the distribution of regressions across linguistic phenomena, and the efficacy of ensemble and distillation methods.
Defending against the Label-flipping Attack in Federated Learning
Jul 05, 2022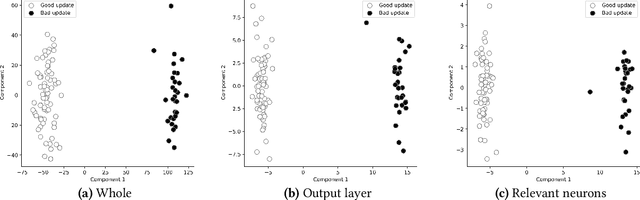


Federated learning (FL) provides autonomy and privacy by design to participating peers, who cooperatively build a machine learning (ML) model while keeping their private data in their devices. However, that same autonomy opens the door for malicious peers to poison the model by conducting either untargeted or targeted poisoning attacks. The label-flipping (LF) attack is a targeted poisoning attack where the attackers poison their training data by flipping the labels of some examples from one class (i.e., the source class) to another (i.e., the target class). Unfortunately, this attack is easy to perform and hard to detect and it negatively impacts on the performance of the global model. Existing defenses against LF are limited by assumptions on the distribution of the peers' data and/or do not perform well with high-dimensional models. In this paper, we deeply investigate the LF attack behavior and find that the contradicting objectives of attackers and honest peers on the source class examples are reflected in the parameter gradients corresponding to the neurons of the source and target classes in the output layer, making those gradients good discriminative features for the attack detection. Accordingly, we propose a novel defense that first dynamically extracts those gradients from the peers' local updates, and then clusters the extracted gradients, analyzes the resulting clusters and filters out potential bad updates before model aggregation. Extensive empirical analysis on three data sets shows the proposed defense's effectiveness against the LF attack regardless of the data distribution or model dimensionality. Also, the proposed defense outperforms several state-of-the-art defenses by offering lower test error, higher overall accuracy, higher source class accuracy, lower attack success rate, and higher stability of the source class accuracy.
FL-Defender: Combating Targeted Attacks in Federated Learning
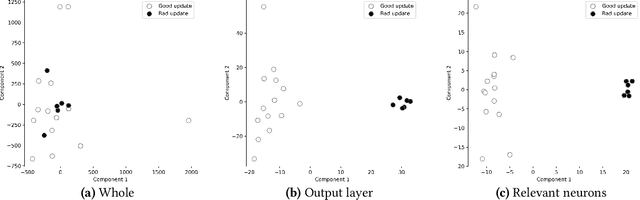
Jul 02, 2022
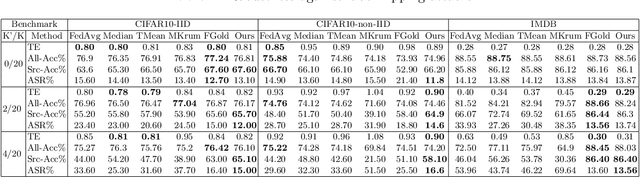
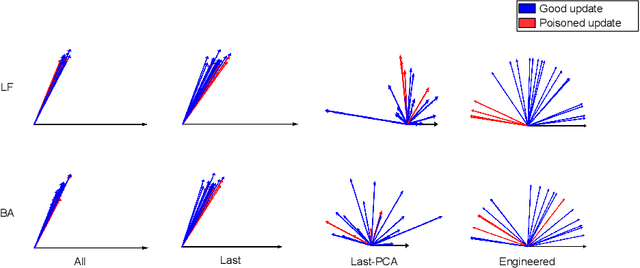
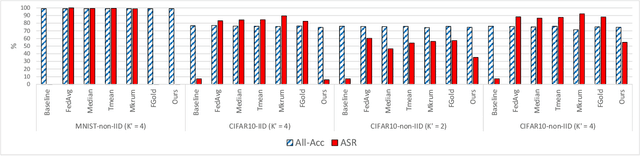
Federated learning (FL) enables learning a global machine learning model from local data distributed among a set of participating workers. This makes it possible i) to train more accurate models due to learning from rich joint training data, and ii) to improve privacy by not sharing the workers' local private data with others. However, the distributed nature of FL makes it vulnerable to targeted poisoning attacks that negatively impact the integrity of the learned model while, unfortunately, being difficult to detect. Existing defenses against those attacks are limited by assumptions on the workers' data distribution, may degrade the global model performance on the main task and/or are ill-suited to high-dimensional models. In this paper, we analyze targeted attacks against FL and find that the neurons in the last layer of a deep learning (DL) model that are related to the attacks exhibit a different behavior from the unrelated neurons, making the last-layer gradients valuable features for attack detection. Accordingly, we propose \textit{FL-Defender} as a method to combat FL targeted attacks. It consists of i) engineering more robust discriminative features by calculating the worker-wise angle similarity for the workers' last-layer gradients, ii) compressing the resulting similarity vectors using PCA to reduce redundant information, and iii) re-weighting the workers' updates based on their deviation from the centroid of the compressed similarity vectors. Experiments on three data sets with different DL model sizes and data distributions show the effectiveness of our method at defending against label-flipping and backdoor attacks. Compared to several state-of-the-art defenses, FL-Defender achieves the lowest attack success rates, maintains the performance of the global model on the main task and causes minimal computational overhead on the server.
Noisy Group Testing with Side Information
Feb 24, 2022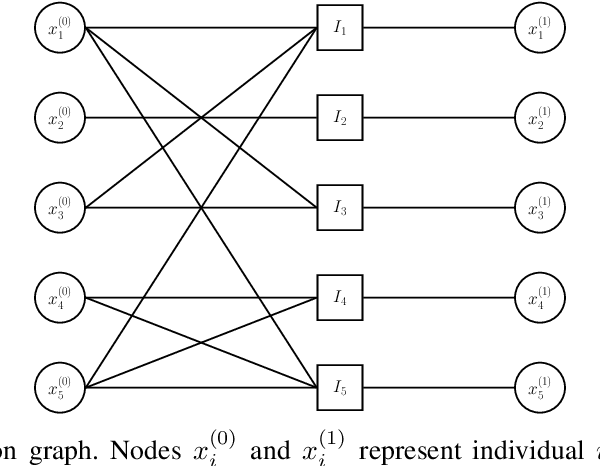
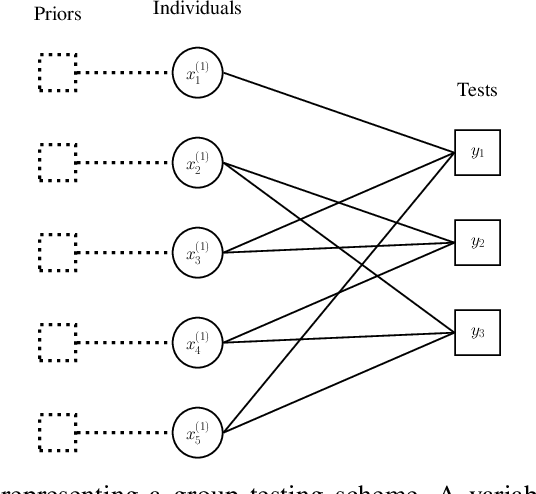
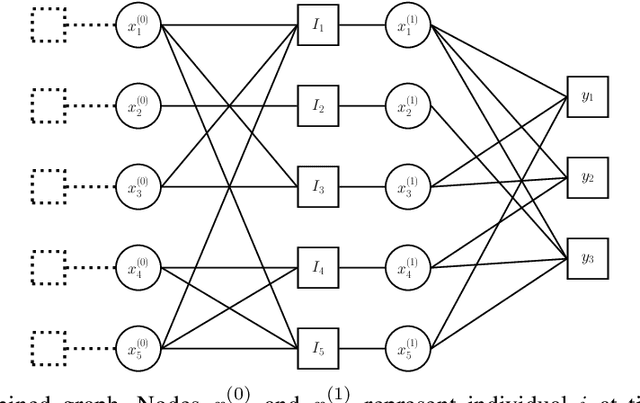
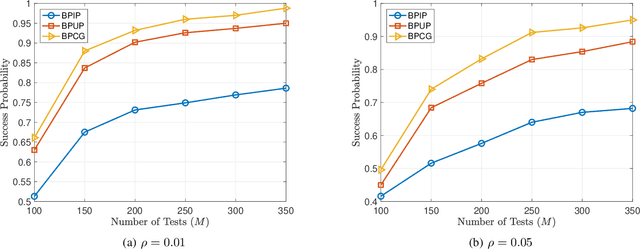
Group testing has recently attracted significant attention from the research community due to its applications in diagnostic virology. An instance of the group testing problem includes a ground set of individuals which includes a small subset of infected individuals. The group testing procedure consists of a number of tests, such that each test indicates whether or not a given subset of individuals includes one or more infected individuals. The goal of the group testing procedure is to identify the subset of infected individuals with the minimum number of tests. Motivated by practical scenarios, such as testing for viral diseases, this paper focuses on the following group testing settings: (i) the group testing procedure is noisy, i.e., the outcome of the group testing procedure can be flipped with a certain probability; (ii) there is a certain amount of side information on the distribution of the infected individuals available to the group testing algorithm. The paper makes the following contributions. First, we propose a probabilistic model, referred to as an interaction model, that captures the side information about the probability distribution of the infected individuals. Next, we present a decoding scheme, based on the belief propagation, that leverages the interaction model to improve the decoding accuracy. Our results indicate that the proposed algorithm achieves higher success probability and lower false-negative and false-positive rates when compared to the traditional belief propagation especially in the high noise regime.
Positive-Congruent Training: Towards Regression-Free Model Updates
Nov 20, 2020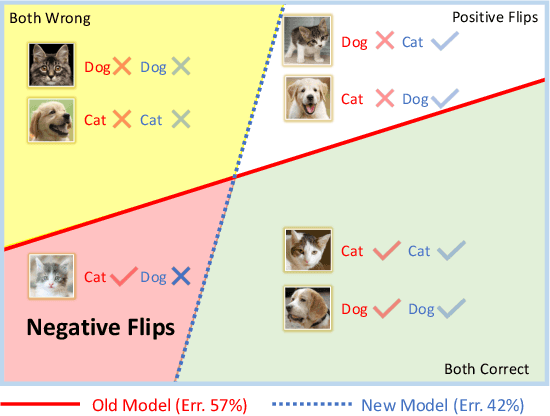
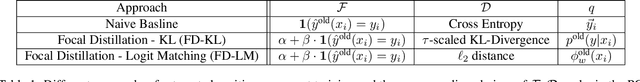
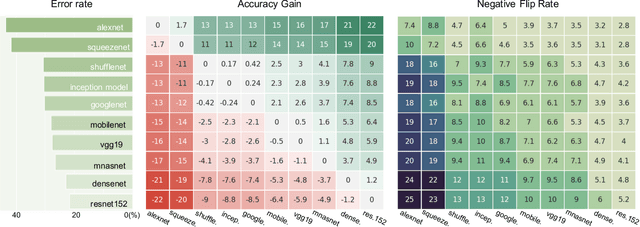
Reducing inconsistencies in the behavior of different versions of an AI system can be as important in practice as reducing its overall error. In image classification, sample-wise inconsistencies appear as "negative flips:" A new model incorrectly predicts the output for a test sample that was correctly classified by the old (reference) model. Positive-congruent (PC) training aims at reducing error rate while at the same time reducing negative flips, thus maximizing congruency with the reference model only on positive predictions, unlike model distillation. We propose a simple approach for PC training, Focal Distillation, which enforces congruence with the reference model by giving more weights to samples that were correctly classified. We also found that, if the reference model itself can be chosen as an ensemble of multiple deep neural networks, negative flips can be further reduced without affecting the new model's accuracy.
Learning with Confident Examples: Rank Pruning for Robust Classification with Noisy Labels
Aug 09, 2017


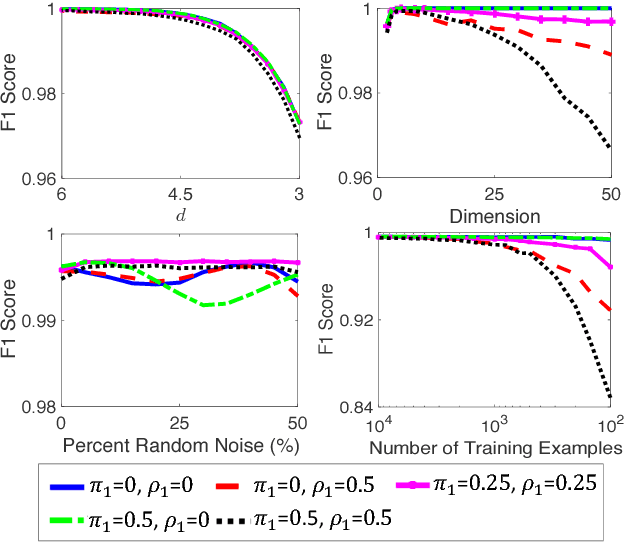
Noisy PN learning is the problem of binary classification when training examples may be mislabeled (flipped) uniformly with noise rate rho1 for positive examples and rho0 for negative examples. We propose Rank Pruning (RP) to solve noisy PN learning and the open problem of estimating the noise rates, i.e. the fraction of wrong positive and negative labels. Unlike prior solutions, RP is time-efficient and general, requiring O(T) for any unrestricted choice of probabilistic classifier with T fitting time. We prove RP has consistent noise estimation and equivalent expected risk as learning with uncorrupted labels in ideal conditions, and derive closed-form solutions when conditions are non-ideal. RP achieves state-of-the-art noise estimation and F1, error, and AUC-PR for both MNIST and CIFAR datasets, regardless of the amount of noise and performs similarly impressively when a large portion of training examples are noise drawn from a third distribution. To highlight, RP with a CNN classifier can predict if an MNIST digit is a "one"or "not" with only 0.25% error, and 0.46 error across all digits, even when 50% of positive examples are mislabeled and 50% of observed positive labels are mislabeled negative examples.