 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMinerl
Papers and Code
Spatial Reasoning and Planning for Deep Embodied Agents
Sep 28, 2024



Humans can perform complex tasks with long-term objectives by planning, reasoning, and forecasting outcomes of actions. For embodied agents to achieve similar capabilities, they must gain knowledge of the environment transferable to novel scenarios with a limited budget of additional trial and error. Learning-based approaches, such as deep RL, can discover and take advantage of inherent regularities and characteristics of the application domain from data, and continuously improve their performances, however at a cost of large amounts of training data. This thesis explores the development of data-driven techniques for spatial reasoning and planning tasks, focusing on enhancing learning efficiency, interpretability, and transferability across novel scenarios. Four key contributions are made. 1) CALVIN, a differential planner that learns interpretable models of the world for long-term planning. It successfully navigated partially observable 3D environments, such as mazes and indoor rooms, by learning the rewards and state transitions from expert demonstrations. 2) SOAP, an RL algorithm that discovers options unsupervised for long-horizon tasks. Options segment a task into subtasks and enable consistent execution of the subtask. SOAP showed robust performances on history-conditional corridor tasks as well as classical benchmarks such as Atari. 3) LangProp, a code optimisation framework using LLMs to solve embodied agent problems that require reasoning by treating code as learnable policies. The framework successfully generated interpretable code with comparable or superior performance to human-written experts in the CARLA autonomous driving benchmark. 4) Voggite, an embodied agent with a vision-to-action transformer backend that solves complex tasks in Minecraft. It achieved third place in the MineRL BASALT Competition by identifying action triggers to segment tasks into multiple stages.
SSM Meets Video Diffusion Models: Efficient Video Generation with Structured State Spaces
Mar 12, 2024



Given the remarkable achievements in image generation through diffusion models, the research community has shown increasing interest in extending these models to video generation. Recent diffusion models for video generation have predominantly utilized attention layers to extract temporal features. However, attention layers are limited by their memory consumption, which increases quadratically with the length of the sequence. This limitation presents significant challenges when attempting to generate longer video sequences using diffusion models. To overcome this challenge, we propose leveraging state-space models (SSMs). SSMs have recently gained attention as viable alternatives due to their linear memory consumption relative to sequence length. In the experiments, we first evaluate our SSM-based model with UCF101, a standard benchmark of video generation. In addition, to investigate the potential of SSMs for longer video generation, we perform an experiment using the MineRL Navigate dataset, varying the number of frames to 64 and 150. In these settings, our SSM-based model can considerably save memory consumption for longer sequences, while maintaining competitive FVD scores to the attention-based models. Our codes are available at https://github.com/shim0114/SSM-Meets-Video-Diffusion-Models.
Zero-shot Imitation Policy via Search in Demonstration Dataset
Jan 29, 2024Behavioral cloning uses a dataset of demonstrations to learn a policy. To overcome computationally expensive training procedures and address the policy adaptation problem, we propose to use latent spaces of pre-trained foundation models to index a demonstration dataset, instantly access similar relevant experiences, and copy behavior from these situations. Actions from a selected similar situation can be performed by the agent until representations of the agent's current situation and the selected experience diverge in the latent space. Thus, we formulate our control problem as a dynamic search problem over a dataset of experts' demonstrations. We test our approach on BASALT MineRL-dataset in the latent representation of a Video Pre-Training model. We compare our model to state-of-the-art, Imitation Learning-based Minecraft agents. Our approach can effectively recover meaningful demonstrations and show human-like behavior of an agent in the Minecraft environment in a wide variety of scenarios. Experimental results reveal that performance of our search-based approach clearly wins in terms of accuracy and perceptual evaluation over learning-based models.
BEDD: The MineRL BASALT Evaluation and Demonstrations Dataset for Training and Benchmarking Agents that Solve Fuzzy Tasks
Dec 05, 2023



The MineRL BASALT competition has served to catalyze advances in learning from human feedback through four hard-to-specify tasks in Minecraft, such as create and photograph a waterfall. Given the completion of two years of BASALT competitions, we offer to the community a formalized benchmark through the BASALT Evaluation and Demonstrations Dataset (BEDD), which serves as a resource for algorithm development and performance assessment. BEDD consists of a collection of 26 million image-action pairs from nearly 14,000 videos of human players completing the BASALT tasks in Minecraft. It also includes over 3,000 dense pairwise human evaluations of human and algorithmic agents. These comparisons serve as a fixed, preliminary leaderboard for evaluating newly-developed algorithms. To enable this comparison, we present a streamlined codebase for benchmarking new algorithms against the leaderboard. In addition to presenting these datasets, we conduct a detailed analysis of the data from both datasets to guide algorithm development and evaluation. The released code and data are available at https://github.com/minerllabs/basalt-benchmark .
DIP-RL: Demonstration-Inferred Preference Learning in Minecraft
Jul 22, 2023

In machine learning for sequential decision-making, an algorithmic agent learns to interact with an environment while receiving feedback in the form of a reward signal. However, in many unstructured real-world settings, such a reward signal is unknown and humans cannot reliably craft a reward signal that correctly captures desired behavior. To solve tasks in such unstructured and open-ended environments, we present Demonstration-Inferred Preference Reinforcement Learning (DIP-RL), an algorithm that leverages human demonstrations in three distinct ways, including training an autoencoder, seeding reinforcement learning (RL) training batches with demonstration data, and inferring preferences over behaviors to learn a reward function to guide RL. We evaluate DIP-RL in a tree-chopping task in Minecraft. Results suggest that the method can guide an RL agent to learn a reward function that reflects human preferences and that DIP-RL performs competitively relative to baselines. DIP-RL is inspired by our previous work on combining demonstrations and pairwise preferences in Minecraft, which was awarded a research prize at the 2022 NeurIPS MineRL BASALT competition, Learning from Human Feedback in Minecraft. Example trajectory rollouts of DIP-RL and baselines are located at https://sites.google.com/view/dip-rl.
Behavioral Cloning via Search in Embedded Demonstration Dataset
Jun 15, 2023Behavioural cloning uses a dataset of demonstrations to learn a behavioural policy. To overcome various learning and policy adaptation problems, we propose to use latent space to index a demonstration dataset, instantly access similar relevant experiences, and copy behavior from these situations. Actions from a selected similar situation can be performed by the agent until representations of the agent's current situation and the selected experience diverge in the latent space. Thus, we formulate our control problem as a search problem over a dataset of experts' demonstrations. We test our approach on BASALT MineRL-dataset in the latent representation of a Video PreTraining model. We compare our model to state-of-the-art Minecraft agents. Our approach can effectively recover meaningful demonstrations and show human-like behavior of an agent in the Minecraft environment in a wide variety of scenarios. Experimental results reveal that performance of our search-based approach is comparable to trained models, while allowing zero-shot task adaptation by changing the demonstration examples.
Towards Solving Fuzzy Tasks with Human Feedback: A Retrospective of the MineRL BASALT 2022 Competition
Mar 23, 2023



To facilitate research in the direction of fine-tuning foundation models from human feedback, we held the MineRL BASALT Competition on Fine-Tuning from Human Feedback at NeurIPS 2022. The BASALT challenge asks teams to compete to develop algorithms to solve tasks with hard-to-specify reward functions in Minecraft. Through this competition, we aimed to promote the development of algorithms that use human feedback as channels to learn the desired behavior. We describe the competition and provide an overview of the top solutions. We conclude by discussing the impact of the competition and future directions for improvement.
Behavioral Cloning via Search in Video PreTraining Latent Space
Dec 27, 2022Our aim is to build autonomous agents that can solve tasks in environments like Minecraft. To do so, we used an imitation learning-based approach. We formulate our control problem as a search problem over a dataset of experts' demonstrations, where the agent copies actions from a similar demonstration trajectory of image-action pairs. We perform a proximity search over the BASALT MineRL-dataset in the latent representation of a Video PreTraining model. The agent copies the actions from the expert trajectory as long as the distance between the state representations of the agent and the selected expert trajectory from the dataset do not diverge. Then the proximity search is repeated. Our approach can effectively recover meaningful demonstration trajectories and show human-like behavior of an agent in the Minecraft environment.
Retrospective on the 2021 BASALT Competition on Learning from Human Feedback
Apr 14, 2022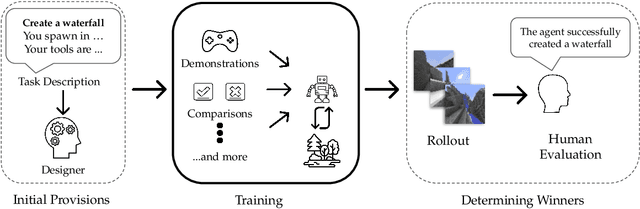
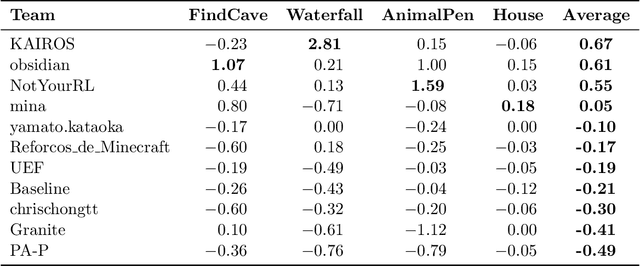
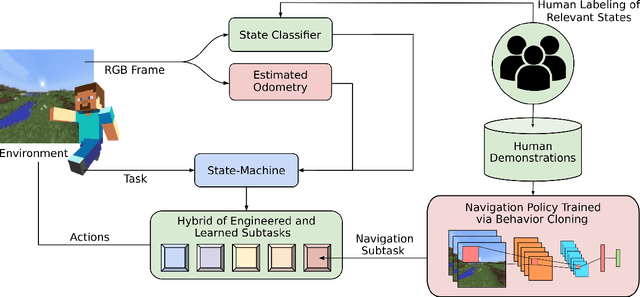
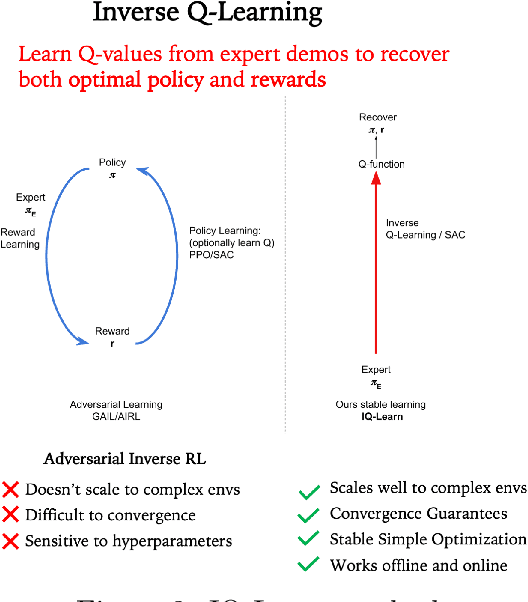
We held the first-ever MineRL Benchmark for Agents that Solve Almost-Lifelike Tasks (MineRL BASALT) Competition at the Thirty-fifth Conference on Neural Information Processing Systems (NeurIPS 2021). The goal of the competition was to promote research towards agents that use learning from human feedback (LfHF) techniques to solve open-world tasks. Rather than mandating the use of LfHF techniques, we described four tasks in natural language to be accomplished in the video game Minecraft, and allowed participants to use any approach they wanted to build agents that could accomplish the tasks. Teams developed a diverse range of LfHF algorithms across a variety of possible human feedback types. The three winning teams implemented significantly different approaches while achieving similar performance. Interestingly, their approaches performed well on different tasks, validating our choice of tasks to include in the competition. While the outcomes validated the design of our competition, we did not get as many participants and submissions as our sister competition, MineRL Diamond. We speculate about the causes of this problem and suggest improvements for future iterations of the competition.
MineRL Diamond 2021 Competition: Overview, Results, and Lessons Learned
Feb 17, 2022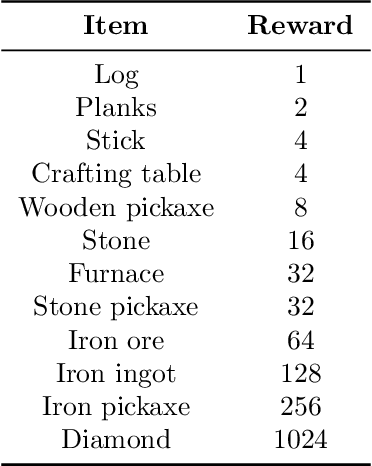
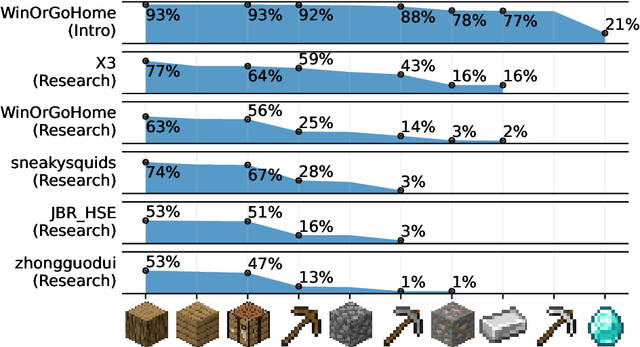
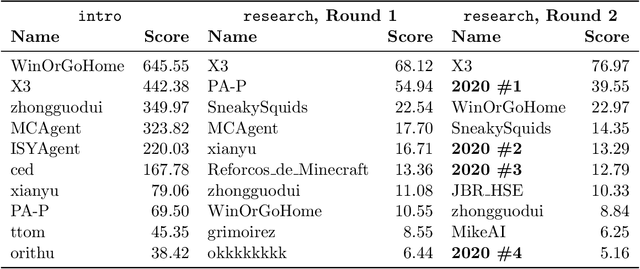
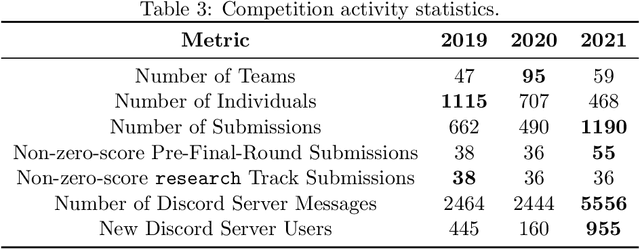
Reinforcement learning competitions advance the field by providing appropriate scope and support to develop solutions toward a specific problem. To promote the development of more broadly applicable methods, organizers need to enforce the use of general techniques, the use of sample-efficient methods, and the reproducibility of the results. While beneficial for the research community, these restrictions come at a cost -- increased difficulty. If the barrier for entry is too high, many potential participants are demoralized. With this in mind, we hosted the third edition of the MineRL ObtainDiamond competition, MineRL Diamond 2021, with a separate track in which we permitted any solution to promote the participation of newcomers. With this track and more extensive tutorials and support, we saw an increased number of submissions. The participants of this easier track were able to obtain a diamond, and the participants of the harder track progressed the generalizable solutions in the same task.