 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAligning Constraint Generation with Design Intent in Parametric CAD
Apr 17, 2025



We adapt alignment techniques from reasoning LLMs to the task of generating engineering sketch constraints found in computer-aided design (CAD) models. Engineering sketches consist of geometric primitives (e.g. points, lines) connected by constraints (e.g. perpendicular, tangent) that define the relationships between them. For a design to be easily editable, the constraints must effectively capture design intent, ensuring the geometry updates predictably when parameters change. Although current approaches can generate CAD designs, an open challenge remains to align model outputs with design intent, we label this problem `design alignment'. A critical first step towards aligning generative CAD models is to generate constraints which fully-constrain all geometric primitives, without over-constraining or distorting sketch geometry. Using alignment techniques to train an existing constraint generation model with feedback from a constraint solver, we are able to fully-constrain 93% of sketches compared to 34% when using a na\"ive supervised fine-tuning (SFT) baseline and only 8.9% without alignment. Our approach can be applied to any existing constraint generation model and sets the stage for further research bridging alignment strategies between the language and design domains.
Adapting a World Model for Trajectory Following in a 3D Game
Apr 16, 2025



Imitation learning is a powerful tool for training agents by leveraging expert knowledge, and being able to replicate a given trajectory is an integral part of it. In complex environments, like modern 3D video games, distribution shift and stochasticity necessitate robust approaches beyond simple action replay. In this study, we apply Inverse Dynamics Models (IDM) with different encoders and policy heads to trajectory following in a modern 3D video game -- Bleeding Edge. Additionally, we investigate several future alignment strategies that address the distribution shift caused by the aleatoric uncertainty and imperfections of the agent. We measure both the trajectory deviation distance and the first significant deviation point between the reference and the agent's trajectory and show that the optimal configuration depends on the chosen setting. Our results show that in a diverse data setting, a GPT-style policy head with an encoder trained from scratch performs the best, DINOv2 encoder with the GPT-style policy head gives the best results in the low data regime, and both GPT-style and MLP-style policy heads had comparable results when pre-trained on a diverse setting and fine-tuned for a specific behaviour setting.
Spatial Reasoning and Planning for Deep Embodied Agents
Sep 28, 2024



Humans can perform complex tasks with long-term objectives by planning, reasoning, and forecasting outcomes of actions. For embodied agents to achieve similar capabilities, they must gain knowledge of the environment transferable to novel scenarios with a limited budget of additional trial and error. Learning-based approaches, such as deep RL, can discover and take advantage of inherent regularities and characteristics of the application domain from data, and continuously improve their performances, however at a cost of large amounts of training data. This thesis explores the development of data-driven techniques for spatial reasoning and planning tasks, focusing on enhancing learning efficiency, interpretability, and transferability across novel scenarios. Four key contributions are made. 1) CALVIN, a differential planner that learns interpretable models of the world for long-term planning. It successfully navigated partially observable 3D environments, such as mazes and indoor rooms, by learning the rewards and state transitions from expert demonstrations. 2) SOAP, an RL algorithm that discovers options unsupervised for long-horizon tasks. Options segment a task into subtasks and enable consistent execution of the subtask. SOAP showed robust performances on history-conditional corridor tasks as well as classical benchmarks such as Atari. 3) LangProp, a code optimisation framework using LLMs to solve embodied agent problems that require reasoning by treating code as learnable policies. The framework successfully generated interpretable code with comparable or superior performance to human-written experts in the CARLA autonomous driving benchmark. 4) Voggite, an embodied agent with a vision-to-action transformer backend that solves complex tasks in Minecraft. It achieved third place in the MineRL BASALT Competition by identifying action triggers to segment tasks into multiple stages.
SOAP-RL: Sequential Option Advantage Propagation for Reinforcement Learning in POMDP Environments
Jul 26, 2024



This work compares ways of extending Reinforcement Learning algorithms to Partially Observed Markov Decision Processes (POMDPs) with options. One view of options is as temporally extended action, which can be realized as a memory that allows the agent to retain historical information beyond the policy's context window. While option assignment could be handled using heuristics and hand-crafted objectives, learning temporally consistent options and associated sub-policies without explicit supervision is a challenge. Two algorithms, PPOEM and SOAP, are proposed and studied in depth to address this problem. PPOEM applies the forward-backward algorithm (for Hidden Markov Models) to optimize the expected returns for an option-augmented policy. However, this learning approach is unstable during on-policy rollouts. It is also unsuited for learning causal policies without the knowledge of future trajectories, since option assignments are optimized for offline sequences where the entire episode is available. As an alternative approach, SOAP evaluates the policy gradient for an optimal option assignment. It extends the concept of the generalized advantage estimation (GAE) to propagate option advantages through time, which is an analytical equivalent to performing temporal back-propagation of option policy gradients. This option policy is only conditional on the history of the agent, not future actions. Evaluated against competing baselines, SOAP exhibited the most robust performance, correctly discovering options for POMDP corridor environments, as well as on standard benchmarks including Atari and MuJoCo, outperforming PPOEM, as well as LSTM and Option-Critic baselines. The open-sourced code is available at https://github.com/shuishida/SoapRL.
You are what you eat? Feeding foundation models a regionally diverse food dataset of World Wide Dishes
Jun 13, 2024Foundation models are increasingly ubiquitous in our daily lives, used in everyday tasks such as text-image searches, interactions with chatbots, and content generation. As use increases, so does concern over the disparities in performance and fairness of these models for different people in different parts of the world. To assess these growing regional disparities, we present World Wide Dishes, a mixed text and image dataset consisting of 765 dishes, with dish names collected in 131 local languages. World Wide Dishes has been collected purely through human contribution and decentralised means, by creating a website widely distributed through social networks. Using the dataset, we demonstrate a novel means of operationalising capability and representational biases in foundation models such as language models and text-to-image generative models. We enrich these studies with a pilot community review to understand, from a first-person perspective, how these models generate images for people in five African countries and the United States. We find that these models generally do not produce quality text and image outputs of dishes specific to different regions. This is true even for the US, which is typically considered to be more well-resourced in training data - though the generation of US dishes does outperform that of the investigated African countries. The models demonstrate a propensity to produce outputs that are inaccurate as well as culturally misrepresentative, flattening, and insensitive. These failures in capability and representational bias have the potential to further reinforce stereotypes and disproportionately contribute to erasure based on region. The dataset and code are available at https://github.com/oxai/world-wide-dishes/.
LangProp: A code optimization framework using Language Models applied to driving
Jan 18, 2024



LangProp is a framework for iteratively optimizing code generated by large language models (LLMs) in a supervised/reinforcement learning setting. While LLMs can generate sensible solutions zero-shot, the solutions are often sub-optimal. Especially for code generation tasks, it is likely that the initial code will fail on certain edge cases. LangProp automatically evaluates the code performance on a dataset of input-output pairs, as well as catches any exceptions, and feeds the results back to the LLM in the training loop, so that the LLM can iteratively improve the code it generates. By adopting a metric- and data-driven training paradigm for this code optimization procedure, one could easily adapt findings from traditional machine learning techniques such as imitation learning, DAgger, and reinforcement learning. We demonstrate the first proof of concept of automated code optimization for autonomous driving in CARLA, showing that LangProp can generate interpretable and transparent driving policies that can be verified and improved in a metric- and data-driven way. Our code will be open-sourced and is available at https://github.com/shuishida/LangProp.
Towards Solving Fuzzy Tasks with Human Feedback: A Retrospective of the MineRL BASALT 2022 Competition
Mar 23, 2023



To facilitate research in the direction of fine-tuning foundation models from human feedback, we held the MineRL BASALT Competition on Fine-Tuning from Human Feedback at NeurIPS 2022. The BASALT challenge asks teams to compete to develop algorithms to solve tasks with hard-to-specify reward functions in Minecraft. Through this competition, we aimed to promote the development of algorithms that use human feedback as channels to learn the desired behavior. We describe the competition and provide an overview of the top solutions. We conclude by discussing the impact of the competition and future directions for improvement.
Towards real-world navigation with deep differentiable planners
Aug 08, 2021
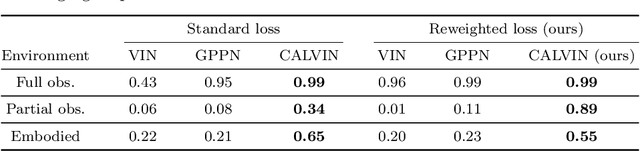
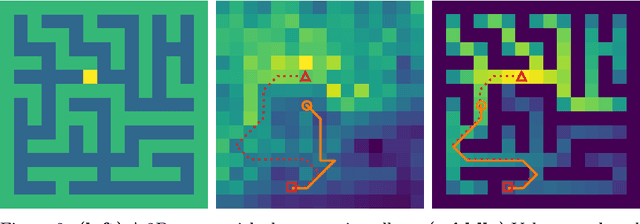

We train embodied neural networks to plan and navigate unseen complex 3D environments, emphasising real-world deployment. Rather than requiring prior knowledge of the agent or environment, the planner learns to model the state transitions and rewards. To avoid the potentially hazardous trial-and-error of reinforcement learning, we focus on differentiable planners such as Value Iteration Networks (VIN), which are trained offline from safe expert demonstrations. Although they work well in small simulations, we address two major limitations that hinder their deployment. First, we observed that current differentiable planners struggle to plan long-term in environments with a high branching complexity. While they should ideally learn to assign low rewards to obstacles to avoid collisions, we posit that the constraints imposed on the network are not strong enough to guarantee the network to learn sufficiently large penalties for every possible collision. We thus impose a structural constraint on the value iteration, which explicitly learns to model any impossible actions. Secondly, we extend the model to work with a limited perspective camera under translation and rotation, which is crucial for real robot deployment. Many VIN-like planners assume a 360 degrees or overhead view without rotation. In contrast, our method uses a memory-efficient lattice map to aggregate CNN embeddings of partial observations, and models the rotational dynamics explicitly using a 3D state-space grid (translation and rotation). Our proposals significantly improve semantic navigation and exploration on several 2D and 3D environments, succeeding in settings that are otherwise challenging for this class of methods. As far as we know, we are the first to successfully perform differentiable planning on the difficult Active Vision Dataset, consisting of real images captured from a robot.