 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGlips
Papers and Code
LAB-Det: Language as a Domain-Invariant Bridge for Training-Free One-Shot Domain Generalization in Object Detection
Feb 06, 2026Foundation object detectors such as GLIP and Grounding DINO excel on general-domain data but often degrade in specialized and data-scarce settings like underwater imagery or industrial defects. Typical cross-domain few-shot approaches rely on fine-tuning scarce target data, incurring cost and overfitting risks. We instead ask: Can a frozen detector adapt with only one exemplar per class without training? To answer this, we introduce training-free one-shot domain generalization for object detection, where detectors must adapt to specialized domains with only one annotated exemplar per class and no weight updates. To tackle this task, we propose LAB-Det, which exploits Language As a domain-invariant Bridge. Instead of adapting visual features, we project each exemplar into a descriptive text that conditions and guides a frozen detector. This linguistic conditioning replaces gradient-based adaptation, enabling robust generalization in data-scarce domains. We evaluate on UODD (underwater) and NEU-DET (industrial defects), two widely adopted benchmarks for data-scarce detection, where object boundaries are often ambiguous, and LAB-Det achieves up to 5.4 mAP improvement over state-of-the-art fine-tuned baselines without updating a single parameter. These results establish linguistic adaptation as an efficient and interpretable alternative to fine-tuning in specialized detection settings.
Exact Graph Learning via Integer Programming
Jan 28, 2026Learning the dependence structure among variables in complex systems is a central problem across medical, natural, and social sciences. These structures can be naturally represented by graphs, and the task of inferring such graphs from data is known as graph learning or as causal discovery if the graphs are given a causal interpretation. Existing approaches typically rely on restrictive assumptions about the data-generating process, employ greedy oracle algorithms, or solve approximate formulations of the graph learning problem. As a result, they are either sensitive to violations of central assumptions or fail to guarantee globally optimal solutions. We address these limitations by introducing a nonparametric graph learning framework based on nonparametric conditional independence testing and integer programming. We reformulate the graph learning problem as an integer-programming problem and prove that solving the integer-programming problem provides a globally optimal solution to the original graph learning problem. Our method leverages efficient encodings of graphical separation criteria, enabling the exact recovery of larger graphs than was previously feasible. We provide an implementation in the openly available R package 'glip' which supports learning (acyclic) directed (mixed) graphs and chain graphs. From the resulting output one can compute representations of the corresponding Markov equivalence classes or weak equivalence classes. Empirically, we demonstrate that our approach is faster than other existing exact graph learning procedures for a large fraction of instances and graphs of various sizes. GLIP also achieves state-of-the-art performance on simulated data and benchmark datasets across all aforementioned classes of graphs.
Language-Grounded Multi-Domain Image Translation via Semantic Difference Guidance
Jan 12, 2026Multi-domain image-to-image translation re quires grounding semantic differences ex pressed in natural language prompts into corresponding visual transformations, while preserving unrelated structural and seman tic content. Existing methods struggle to maintain structural integrity and provide fine grained, attribute-specific control, especially when multiple domains are involved. We propose LACE (Language-grounded Attribute Controllable Translation), built on two compo nents: (1) a GLIP-Adapter that fuses global semantics with local structural features to pre serve consistency, and (2) a Multi-Domain Control Guidance mechanism that explicitly grounds the semantic delta between source and target prompts into per-attribute translation vec tors, aligning linguistic semantics with domain level visual changes. Together, these modules enable compositional multi-domain control with independent strength modulation for each attribute. Experiments on CelebA(Dialog) and BDD100K demonstrate that LACE achieves high visual fidelity, structural preservation, and interpretable domain-specific control, surpass ing prior baselines. This positions LACE as a cross-modal content generation framework bridging language semantics and controllable visual translation.
Semantic-Guided Natural Language and Visual Fusion for Cross-Modal Interaction Based on Tiny Object Detection
Nov 07, 2025This paper introduces a cutting-edge approach to cross-modal interaction for tiny object detection by combining semantic-guided natural language processing with advanced visual recognition backbones. The proposed method integrates the BERT language model with the CNN-based Parallel Residual Bi-Fusion Feature Pyramid Network (PRB-FPN-Net), incorporating innovative backbone architectures such as ELAN, MSP, and CSP to optimize feature extraction and fusion. By employing lemmatization and fine-tuning techniques, the system aligns semantic cues from textual inputs with visual features, enhancing detection precision for small and complex objects. Experimental validation using the COCO and Objects365 datasets demonstrates that the model achieves superior performance. On the COCO2017 validation set, it attains a 52.6% average precision (AP), outperforming YOLO-World significantly while maintaining half the parameter consumption of Transformer-based models like GLIP. Several test on different of backbones such ELAN, MSP, and CSP further enable efficient handling of multi-scale objects, ensuring scalability and robustness in resource-constrained environments. This study underscores the potential of integrating natural language understanding with advanced backbone architectures, setting new benchmarks in object detection accuracy, efficiency, and adaptability to real-world challenges.
GLip: A Global-Local Integrated Progressive Framework for Robust Visual Speech Recognition
Sep 19, 2025Visual speech recognition (VSR), also known as lip reading, is the task of recognizing speech from silent video. Despite significant advancements in VSR over recent decades, most existing methods pay limited attention to real-world visual challenges such as illumination variations, occlusions, blurring, and pose changes. To address these challenges, we propose GLip, a Global-Local Integrated Progressive framework designed for robust VSR. GLip is built upon two key insights: (i) learning an initial \textit{coarse} alignment between visual features across varying conditions and corresponding speech content facilitates the subsequent learning of \textit{precise} visual-to-speech mappings in challenging environments; (ii) under adverse conditions, certain local regions (e.g., non-occluded areas) often exhibit more discriminative cues for lip reading than global features. To this end, GLip introduces a dual-path feature extraction architecture that integrates both global and local features within a two-stage progressive learning framework. In the first stage, the model learns to align both global and local visual features with corresponding acoustic speech units using easily accessible audio-visual data, establishing a coarse yet semantically robust foundation. In the second stage, we introduce a Contextual Enhancement Module (CEM) to dynamically integrate local features with relevant global context across both spatial and temporal dimensions, refining the coarse representations into precise visual-speech mappings. Our framework uniquely exploits discriminative local regions through a progressive learning strategy, demonstrating enhanced robustness against various visual challenges and consistently outperforming existing methods on the LRS2 and LRS3 benchmarks. We further validate its effectiveness on a newly introduced challenging Mandarin dataset.
Generating Vision-Language Navigation Instructions Incorporated Fine-Grained Alignment Annotations
Jun 10, 2025Vision-Language Navigation (VLN) enables intelligent agents to navigate environments by integrating visual perception and natural language instructions, yet faces significant challenges due to the scarcity of fine-grained cross-modal alignment annotations. Existing datasets primarily focus on global instruction-trajectory matching, neglecting sub-instruction-level and entity-level alignments critical for accurate navigation action decision-making. To address this limitation, we propose FCA-NIG, a generative framework that automatically constructs navigation instructions with dual-level fine-grained cross-modal annotations. In this framework, an augmented trajectory is first divided into sub-trajectories, which are then processed through GLIP-based landmark detection, crafted instruction construction, OFA-Speaker based R2R-like instruction generation, and CLIP-powered entity selection, generating sub-instruction-trajectory pairs with entity-landmark annotations. Finally, these sub-pairs are aggregated to form a complete instruction-trajectory pair. The framework generates the FCA-R2R dataset, the first large-scale augmentation dataset featuring precise sub-instruction-sub-trajectory and entity-landmark alignments. Extensive experiments demonstrate that training with FCA-R2R significantly improves the performance of multiple state-of-the-art VLN agents, including SF, EnvDrop, RecBERT, and HAMT. Incorporating sub-instruction-trajectory alignment enhances agents' state awareness and decision accuracy, while entity-landmark alignment further boosts navigation performance and generalization. These results highlight the effectiveness of FCA-NIG in generating high-quality, scalable training data without manual annotation, advancing fine-grained cross-modal learning in complex navigation tasks.
Disambiguating Reference in Visually Grounded Dialogues through Joint Modeling of Textual and Multimodal Semantic Structures
May 16, 2025



Multimodal reference resolution, including phrase grounding, aims to understand the semantic relations between mentions and real-world objects. Phrase grounding between images and their captions is a well-established task. In contrast, for real-world applications, it is essential to integrate textual and multimodal reference resolution to unravel the reference relations within dialogue, especially in handling ambiguities caused by pronouns and ellipses. This paper presents a framework that unifies textual and multimodal reference resolution by mapping mention embeddings to object embeddings and selecting mentions or objects based on their similarity. Our experiments show that learning textual reference resolution, such as coreference resolution and predicate-argument structure analysis, positively affects performance in multimodal reference resolution. In particular, our model with coreference resolution performs better in pronoun phrase grounding than representative models for this task, MDETR and GLIP. Our qualitative analysis demonstrates that incorporating textual reference relations strengthens the confidence scores between mentions, including pronouns and predicates, and objects, which can reduce the ambiguities that arise in visually grounded dialogues.
GLIP-OOD: Zero-Shot Graph OOD Detection with Foundation Model
Apr 29, 2025



Out-of-distribution (OOD) detection is critical for ensuring the safety and reliability of machine learning systems, particularly in dynamic and open-world environments. In the vision and text domains, zero-shot OOD detection - which requires no training on in-distribution (ID) data - has made significant progress through the use of large-scale pretrained models such as vision-language models (VLMs) and large language models (LLMs). However, zero-shot OOD detection in graph-structured data remains largely unexplored, primarily due to the challenges posed by complex relational structures and the absence of powerful, large-scale pretrained models for graphs. In this work, we take the first step toward enabling zero-shot graph OOD detection by leveraging a graph foundation model (GFM). We show that, when provided only with class label names, the GFM can perform OOD detection without any node-level supervision - outperforming existing supervised methods across multiple datasets. To address the more practical setting where OOD label names are unavailable, we introduce GLIP-OOD, a novel framework that employs LLMs to generate semantically informative pseudo-OOD labels from unlabeled data. These labels enable the GFM to capture nuanced semantic boundaries between ID and OOD classes and perform fine-grained OOD detection - without requiring any labeled nodes. Our approach is the first to enable node-level graph OOD detection in a fully zero-shot setting, and achieves state-of-the-art performance on four benchmark text-attributed graph datasets.
Prompt as Knowledge Bank: Boost Vision-language model via Structural Representation for zero-shot medical detection
Feb 22, 2025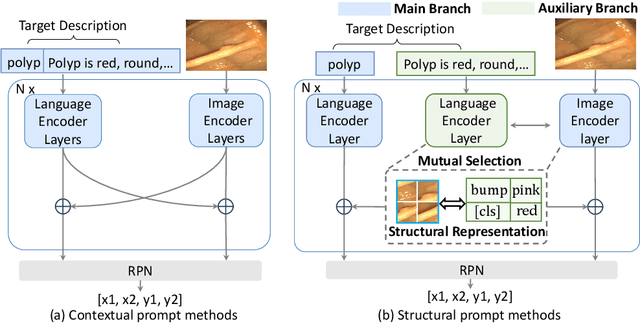
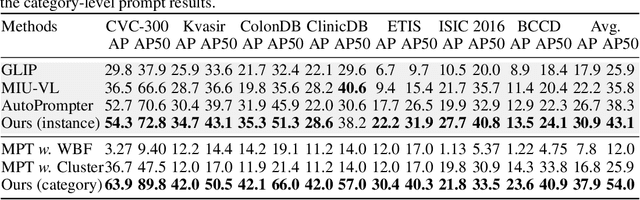
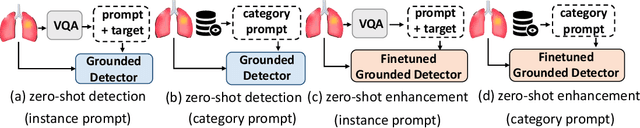
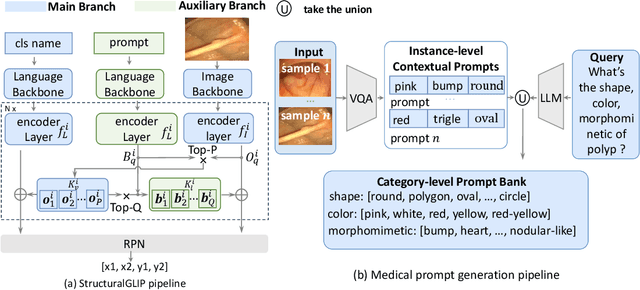
Zero-shot medical detection can further improve detection performance without relying on annotated medical images even upon the fine-tuned model, showing great clinical value. Recent studies leverage grounded vision-language models (GLIP) to achieve this by using detailed disease descriptions as prompts for the target disease name during the inference phase. However, these methods typically treat prompts as equivalent context to the target name, making it difficult to assign specific disease knowledge based on visual information, leading to a coarse alignment between images and target descriptions. In this paper, we propose StructuralGLIP, which introduces an auxiliary branch to encode prompts into a latent knowledge bank layer-by-layer, enabling more context-aware and fine-grained alignment. Specifically, in each layer, we select highly similar features from both the image representation and the knowledge bank, forming structural representations that capture nuanced relationships between image patches and target descriptions. These features are then fused across modalities to further enhance detection performance. Extensive experiments demonstrate that StructuralGLIP achieves a +4.1\% AP improvement over prior state-of-the-art methods across seven zero-shot medical detection benchmarks, and consistently improves fine-tuned models by +3.2\% AP on endoscopy image datasets.
NavAgent: Multi-scale Urban Street View Fusion For UAV Embodied Vision-and-Language Navigation
Nov 13, 2024Vision-and-Language Navigation (VLN), as a widely discussed research direction in embodied intelligence, aims to enable embodied agents to navigate in complicated visual environments through natural language commands. Most existing VLN methods focus on indoor ground robot scenarios. However, when applied to UAV VLN in outdoor urban scenes, it faces two significant challenges. First, urban scenes contain numerous objects, which makes it challenging to match fine-grained landmarks in images with complex textual descriptions of these landmarks. Second, overall environmental information encompasses multiple modal dimensions, and the diversity of representations significantly increases the complexity of the encoding process. To address these challenges, we propose NavAgent, the first urban UAV embodied navigation model driven by a large Vision-Language Model. NavAgent undertakes navigation tasks by synthesizing multi-scale environmental information, including topological maps (global), panoramas (medium), and fine-grained landmarks (local). Specifically, we utilize GLIP to build a visual recognizer for landmark capable of identifying and linguisticizing fine-grained landmarks. Subsequently, we develop dynamically growing scene topology map that integrate environmental information and employ Graph Convolutional Networks to encode global environmental data. In addition, to train the visual recognizer for landmark, we develop NavAgent-Landmark2K, the first fine-grained landmark dataset for real urban street scenes. In experiments conducted on the Touchdown and Map2seq datasets, NavAgent outperforms strong baseline models. The code and dataset will be released to the community to facilitate the exploration and development of outdoor VLN.