 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage-Grounded Multi-Domain Image Translation via Semantic Difference Guidance
Jan 12, 2026Multi-domain image-to-image translation re quires grounding semantic differences ex pressed in natural language prompts into corresponding visual transformations, while preserving unrelated structural and seman tic content. Existing methods struggle to maintain structural integrity and provide fine grained, attribute-specific control, especially when multiple domains are involved. We propose LACE (Language-grounded Attribute Controllable Translation), built on two compo nents: (1) a GLIP-Adapter that fuses global semantics with local structural features to pre serve consistency, and (2) a Multi-Domain Control Guidance mechanism that explicitly grounds the semantic delta between source and target prompts into per-attribute translation vec tors, aligning linguistic semantics with domain level visual changes. Together, these modules enable compositional multi-domain control with independent strength modulation for each attribute. Experiments on CelebA(Dialog) and BDD100K demonstrate that LACE achieves high visual fidelity, structural preservation, and interpretable domain-specific control, surpass ing prior baselines. This positions LACE as a cross-modal content generation framework bridging language semantics and controllable visual translation.
EMR-AGENT: Automating Cohort and Feature Extraction from EMR Databases
Oct 02, 2025Machine learning models for clinical prediction rely on structured data extracted from Electronic Medical Records (EMRs), yet this process remains dominated by hardcoded, database-specific pipelines for cohort definition, feature selection, and code mapping. These manual efforts limit scalability, reproducibility, and cross-institutional generalization. To address this, we introduce EMR-AGENT (Automated Generalized Extraction and Navigation Tool), an agent-based framework that replaces manual rule writing with dynamic, language model-driven interaction to extract and standardize structured clinical data. Our framework automates cohort selection, feature extraction, and code mapping through interactive querying of databases. Our modular agents iteratively observe query results and reason over schema and documentation, using SQL not just for data retrieval but also as a tool for database observation and decision making. This eliminates the need for hand-crafted, schema-specific logic. To enable rigorous evaluation, we develop a benchmarking codebase for three EMR databases (MIMIC-III, eICU, SICdb), including both seen and unseen schema settings. Our results demonstrate strong performance and generalization across these databases, highlighting the feasibility of automating a process previously thought to require expert-driven design. The code will be released publicly at https://github.com/AITRICS/EMR-AGENT/tree/main. For a demonstration, please visit our anonymous demo page: https://anonymoususer-max600.github.io/EMR_AGENT/
Towards Precise Prediction Uncertainty in GNNs: Refining GNNs with Topology-grouping Strategy
Dec 18, 2024



Recent advancements in graph neural networks (GNNs) have highlighted the critical need of calibrating model predictions, with neighborhood prediction similarity recognized as a pivotal component. Existing studies suggest that nodes with analogous neighborhood prediction similarity often exhibit similar calibration characteristics. Building on this insight, recent approaches incorporate neighborhood similarity into node-wise temperature scaling techniques. However, our analysis reveals that this assumption does not hold universally. Calibration errors can differ significantly even among nodes with comparable neighborhood similarity, depending on their confidence levels. This necessitates a re-evaluation of existing GNN calibration methods, as a single, unified approach may lead to sub-optimal calibration. In response, we introduce **Simi-Mailbox**, a novel approach that categorizes nodes by both neighborhood similarity and their own confidence, irrespective of proximity or connectivity. Our method allows fine-grained calibration by employing *group-specific* temperature scaling, with each temperature tailored to address the specific miscalibration level of affiliated nodes, rather than adhering to a uniform trend based on neighborhood similarity. Extensive experiments demonstrate the effectiveness of our **Simi-Mailbox** across diverse datasets on different GNN architectures, achieving up to 13.79\% error reduction compared to uncalibrated GNN predictions.
Appearance Matching Adapter for Exemplar-based Semantic Image Synthesis
Dec 04, 2024



Exemplar-based semantic image synthesis aims to generate images aligned with given semantic content while preserving the appearance of an exemplar image. Conventional structure-guidance models, such as ControlNet, are limited in that they cannot directly utilize exemplar images as input, relying instead solely on text prompts to control appearance. Recent tuning-free approaches address this limitation by transferring local appearance from the exemplar image to the synthesized image through implicit cross-image matching in the augmented self-attention mechanism of pre-trained diffusion models. However, these methods face challenges when applied to content-rich scenes with significant geometric deformations, such as driving scenes. In this paper, we propose the Appearance Matching Adapter (AM-Adapter), a learnable framework that enhances cross-image matching within augmented self-attention by incorporating semantic information from segmentation maps. To effectively disentangle generation and matching processes, we adopt a stage-wise training approach. Initially, we train the structure-guidance and generation networks, followed by training the AM-Adapter while keeping the other networks frozen. During inference, we introduce an automated exemplar retrieval method to efficiently select exemplar image-segmentation pairs. Despite utilizing a limited number of learnable parameters, our method achieves state-of-the-art performance, excelling in both semantic alignment preservation and local appearance fidelity. Extensive ablation studies further validate our design choices. Code and pre-trained weights will be publicly available.: https://cvlab-kaist.github.io/AM-Adapter/
PruNeRF: Segment-Centric Dataset Pruning via 3D Spatial Consistency
Jun 02, 2024



Neural Radiance Fields (NeRF) have shown remarkable performance in learning 3D scenes. However, NeRF exhibits vulnerability when confronted with distractors in the training images -- unexpected objects are present only within specific views, such as moving entities like pedestrians or birds. Excluding distractors during dataset construction is a straightforward solution, but without prior knowledge of their types and quantities, it becomes prohibitively expensive. In this paper, we propose PruNeRF, a segment-centric dataset pruning framework via 3D spatial consistency, that effectively identifies and prunes the distractors. We first examine existing metrics for measuring pixel-wise distraction and introduce Influence Functions for more accurate measurements. Then, we assess 3D spatial consistency using a depth-based reprojection technique to obtain 3D-aware distraction. Furthermore, we incorporate segmentation for pixel-to-segment refinement, enabling more precise identification. Our experiments on benchmark datasets demonstrate that PruNeRF consistently outperforms state-of-the-art methods in robustness against distractors.
PC-Adapter: Topology-Aware Adapter for Efficient Domain Adaption on Point Clouds with Rectified Pseudo-label
Sep 29, 2023



Understanding point clouds captured from the real-world is challenging due to shifts in data distribution caused by varying object scales, sensor angles, and self-occlusion. Prior works have addressed this issue by combining recent learning principles such as self-supervised learning, self-training, and adversarial training, which leads to significant computational overhead.Toward succinct yet powerful domain adaptation for point clouds, we revisit the unique challenges of point cloud data under domain shift scenarios and discover the importance of the global geometry of source data and trends of target pseudo-labels biased to the source label distribution. Motivated by our observations, we propose an adapter-guided domain adaptation method, PC-Adapter, that preserves the global shape information of the source domain using an attention-based adapter, while learning the local characteristics of the target domain via another adapter equipped with graph convolution. Additionally, we propose a novel pseudo-labeling strategy resilient to the classifier bias by adjusting confidence scores using their class-wise confidence distributions to consider relative confidences. Our method demonstrates superiority over baselines on various domain shift settings in benchmark datasets - PointDA, GraspNetPC, and PointSegDA.
SGEM: Test-Time Adaptation for Automatic Speech Recognition via Sequential-Level Generalized Entropy Minimization
Jun 21, 2023Automatic speech recognition (ASR) models are frequently exposed to data distribution shifts in many real-world scenarios, leading to erroneous predictions. To tackle this issue, an existing test-time adaptation (TTA) method has recently been proposed to adapt the pre-trained ASR model on unlabeled test instances without source data. Despite decent performance gain, this work relies solely on naive greedy decoding and performs adaptation across timesteps at a frame level, which may not be optimal given the sequential nature of the model output. Motivated by this, we propose a novel TTA framework, dubbed SGEM, for general ASR models. To treat the sequential output, SGEM first exploits beam search to explore candidate output logits and selects the most plausible one. Then, it utilizes generalized entropy minimization and negative sampling as unsupervised objectives to adapt the model. SGEM achieves state-of-the-art performance for three mainstream ASR models under various domain shifts.
TAM: Topology-Aware Margin Loss for Class-Imbalanced Node Classification
Jun 26, 2022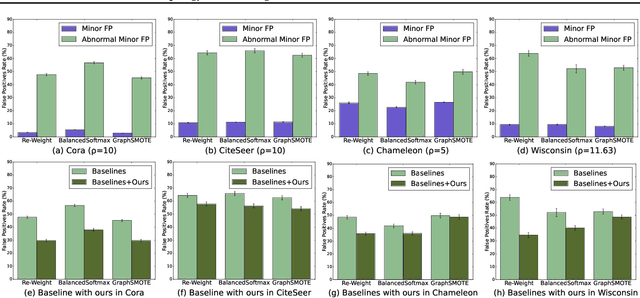
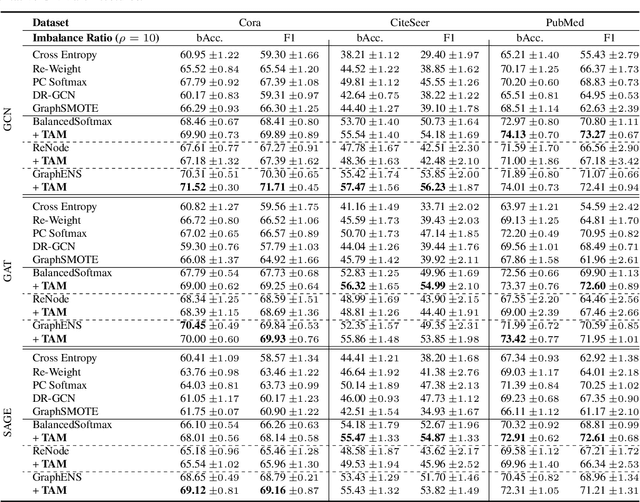
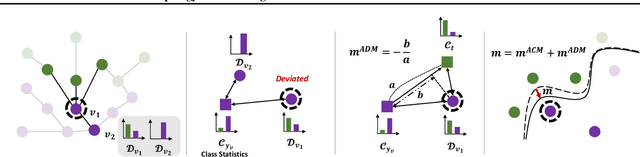
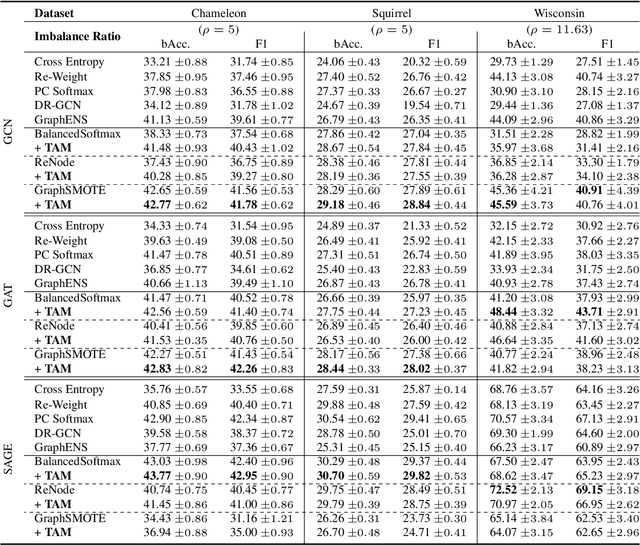
Learning unbiased node representations under class-imbalanced graph data is challenging due to interactions between adjacent nodes. Existing studies have in common that they compensate the minor class nodes `as a group' according to their overall quantity (ignoring node connections in graph), which inevitably increase the false positive cases for major nodes. We hypothesize that the increase in these false positive cases is highly affected by the label distribution around each node and confirm it experimentally. In addition, in order to handle this issue, we propose Topology-Aware Margin (TAM) to reflect local topology on the learning objective. Our method compares the connectivity pattern of each node with the class-averaged counter-part and adaptively adjusts the margin accordingly based on that. Our method consistently exhibits superiority over the baselines on various node classification benchmark datasets with representative GNN architectures.
Saliency Grafting: Innocuous Attribution-Guided Mixup with Calibrated Label Mixing
Dec 16, 2021
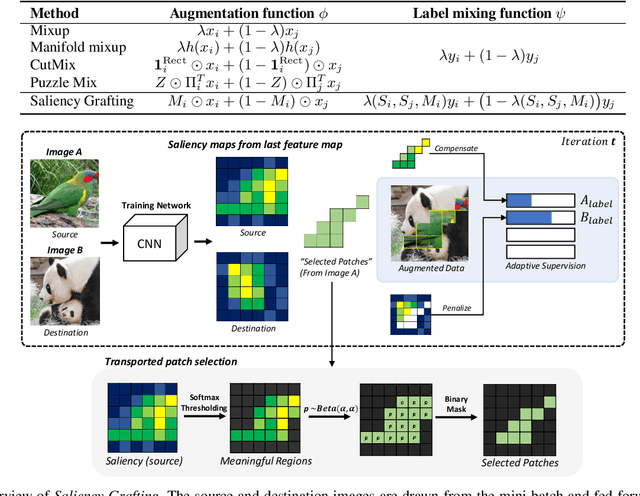
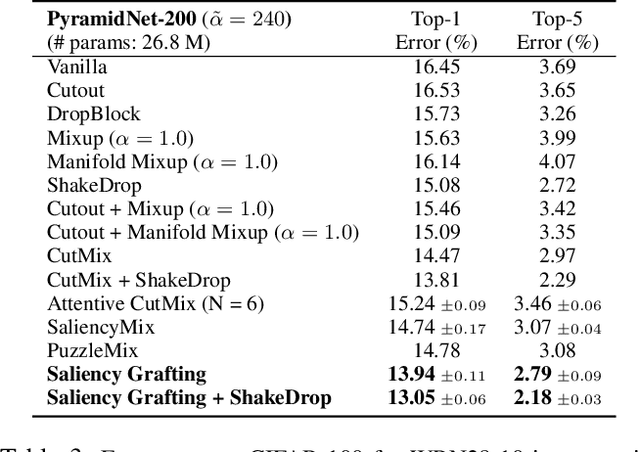

The Mixup scheme suggests mixing a pair of samples to create an augmented training sample and has gained considerable attention recently for improving the generalizability of neural networks. A straightforward and widely used extension of Mixup is to combine with regional dropout-like methods: removing random patches from a sample and replacing it with the features from another sample. Albeit their simplicity and effectiveness, these methods are prone to create harmful samples due to their randomness. To address this issue, 'maximum saliency' strategies were recently proposed: they select only the most informative features to prevent such a phenomenon. However, they now suffer from lack of sample diversification as they always deterministically select regions with maximum saliency, injecting bias into the augmented data. In this paper, we present, a novel, yet simple Mixup-variant that captures the best of both worlds. Our idea is two-fold. By stochastically sampling the features and 'grafting' them onto another sample, our method effectively generates diverse yet meaningful samples. Its second ingredient is to produce the label of the grafted sample by mixing the labels in a saliency-calibrated fashion, which rectifies supervision misguidance introduced by the random sampling procedure. Our experiments under CIFAR, Tiny-ImageNet, and ImageNet datasets show that our scheme outperforms the current state-of-the-art augmentation strategies not only in terms of classification accuracy, but is also superior in coping under stress conditions such as data corruption and object occlusion.
Graph Transplant: Node Saliency-Guided Graph Mixup with Local Structure Preservation
Nov 10, 2021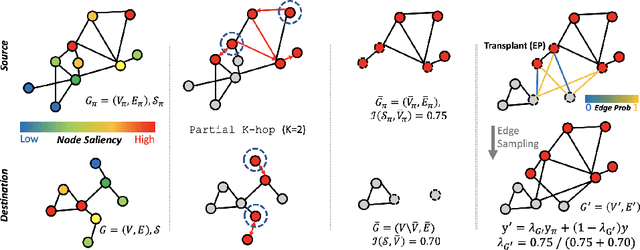
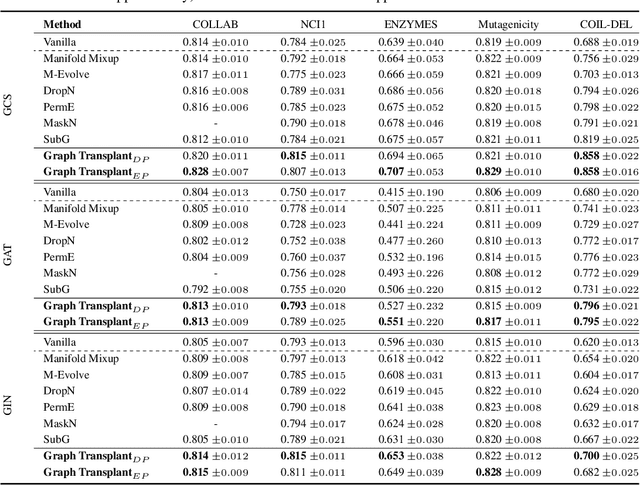
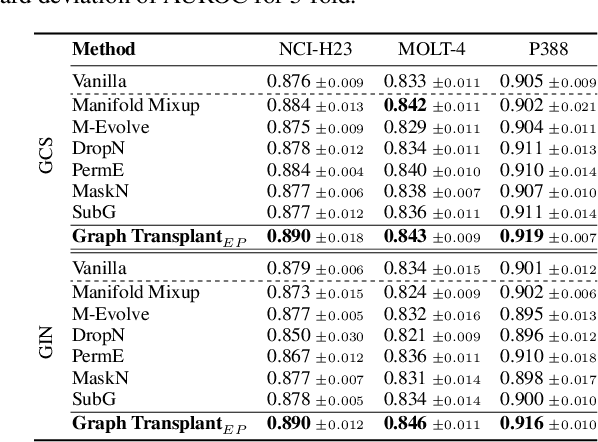
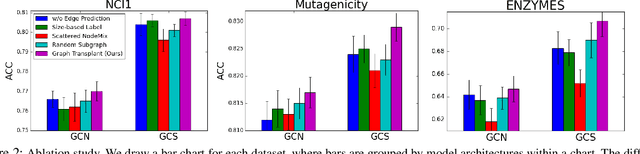
Graph-structured datasets usually have irregular graph sizes and connectivities, rendering the use of recent data augmentation techniques, such as Mixup, difficult. To tackle this challenge, we present the first Mixup-like graph augmentation method at the graph-level called Graph Transplant, which mixes irregular graphs in data space. To be well defined on various scales of the graph, our method identifies the sub-structure as a mix unit that can preserve the local information. Since the mixup-based methods without special consideration of the context are prone to generate noisy samples, our method explicitly employs the node saliency information to select meaningful subgraphs and adaptively determine the labels. We extensively validate our method with diverse GNN architectures on multiple graph classification benchmark datasets from a wide range of graph domains of different sizes. Experimental results show the consistent superiority of our method over other basic data augmentation baselines. We also demonstrate that Graph Transplant enhances the performance in terms of robustness and model calibration.