 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFairmot
Papers and Code
UniTrack: Differentiable Graph Representation Learning for Multi-Object Tracking
Feb 04, 2026We present UniTrack, a plug-and-play graph-theoretic loss function designed to significantly enhance multi-object tracking (MOT) performance by directly optimizing tracking-specific objectives through unified differentiable learning. Unlike prior graph-based MOT methods that redesign tracking architectures, UniTrack provides a universal training objective that integrates detection accuracy, identity preservation, and spatiotemporal consistency into a single end-to-end trainable loss function, enabling seamless integration with existing MOT systems without architectural modifications. Through differentiable graph representation learning, UniTrack enables networks to learn holistic representations of motion continuity and identity relationships across frames. We validate UniTrack across diverse tracking models and multiple challenging benchmarks, demonstrating consistent improvements across all tested architectures and datasets including Trackformer, MOTR, FairMOT, ByteTrack, GTR, and MOTE. Extensive evaluations show up to 53\% reduction in identity switches and 12\% IDF1 improvements across challenging benchmarks, with GTR achieving peak performance gains of 9.7\% MOTA on SportsMOT.
A Framework for Multi-View Multiple Object Tracking using Single-View Multi-Object Trackers on Fish Data
May 22, 2025Multi-object tracking (MOT) in computer vision has made significant advancements, yet tracking small fish in underwater environments presents unique challenges due to complex 3D motions and data noise. Traditional single-view MOT models often fall short in these settings. This thesis addresses these challenges by adapting state-of-the-art single-view MOT models, FairMOT and YOLOv8, for underwater fish detecting and tracking in ecological studies. The core contribution of this research is the development of a multi-view framework that utilizes stereo video inputs to enhance tracking accuracy and fish behavior pattern recognition. By integrating and evaluating these models on underwater fish video datasets, the study aims to demonstrate significant improvements in precision and reliability compared to single-view approaches. The proposed framework detects fish entities with a relative accuracy of 47% and employs stereo-matching techniques to produce a novel 3D output, providing a more comprehensive understanding of fish movements and interactions
Leveraging Foundation Models via Knowledge Distillation in Multi-Object Tracking: Distilling DINOv2 Features to FairMOT
Jul 25, 2024Multiple Object Tracking (MOT) is a computer vision task that has been employed in a variety of sectors. Some common limitations in MOT are varying object appearances, occlusions, or crowded scenes. To address these challenges, machine learning methods have been extensively deployed, leveraging large datasets, sophisticated models, and substantial computational resources. Due to practical limitations, access to the above is not always an option. However, with the recent release of foundation models by prominent AI companies, pretrained models have been trained on vast datasets and resources using state-of-the-art methods. This work tries to leverage one such foundation model, called DINOv2, through using knowledge distillation. The proposed method uses a teacher-student architecture, where DINOv2 is the teacher and the FairMOT backbone HRNetv2 W18 is the student. The results imply that although the proposed method shows improvements in certain scenarios, it does not consistently outperform the original FairMOT model. These findings highlight the potential and limitations of applying foundation models in knowledge
AttMOT: Improving Multiple-Object Tracking by Introducing Auxiliary Pedestrian Attributes
Aug 15, 2023



Multi-object tracking (MOT) is a fundamental problem in computer vision with numerous applications, such as intelligent surveillance and automated driving. Despite the significant progress made in MOT, pedestrian attributes, such as gender, hairstyle, body shape, and clothing features, which contain rich and high-level information, have been less explored. To address this gap, we propose a simple, effective, and generic method to predict pedestrian attributes to support general Re-ID embedding. We first introduce AttMOT, a large, highly enriched synthetic dataset for pedestrian tracking, containing over 80k frames and 6 million pedestrian IDs with different time, weather conditions, and scenarios. To the best of our knowledge, AttMOT is the first MOT dataset with semantic attributes. Subsequently, we explore different approaches to fuse Re-ID embedding and pedestrian attributes, including attention mechanisms, which we hope will stimulate the development of attribute-assisted MOT. The proposed method AAM demonstrates its effectiveness and generality on several representative pedestrian multi-object tracking benchmarks, including MOT17 and MOT20, through experiments on the AttMOT dataset. When applied to state-of-the-art trackers, AAM achieves consistent improvements in MOTA, HOTA, AssA, IDs, and IDF1 scores. For instance, on MOT17, the proposed method yields a +1.1 MOTA, +1.7 HOTA, and +1.8 IDF1 improvement when used with FairMOT. To encourage further research on attribute-assisted MOT, we will release the AttMOT dataset.
Improving Object Detection, Multi-object Tracking, and Re-Identification for Disaster Response Drones
Jan 05, 2022



We aim to detect and identify multiple objects using multiple cameras and computer vision for disaster response drones. The major challenges are taming detection errors, resolving ID switching and fragmentation, adapting to multi-scale features and multiple views with global camera motion. Two simple approaches are proposed to solve these issues. One is a fast multi-camera system that added a tracklet association, and the other is incorporating a high-performance detector and tracker to resolve restrictions. (...) The accuracy of our first approach (85.71%) is slightly improved compared to our baseline, FairMOT (85.44%) in the validation dataset. In the final results calculated based on L2-norm error, the baseline was 48.1, while the proposed model combination was 34.9, which is a great reduction of error by a margin of 27.4%. In the second approach, although DeepSORT only processes a quarter of all frames due to hardware and time limitations, our model with DeepSORT (42.9%) outperforms FairMOT (71.4%) in terms of recall. Both of our models ranked second and third place in the `AI Grand Challenge' organized by the Korean Ministry of Science and ICT in 2020 and 2021, respectively. The source codes are publicly available at these URLs (github.com/mlvlab/drone_ai_challenge, github.com/mlvlab/Drone_Task1, github.com/mlvlab/Rony2_task3, github.com/mlvlab/Drone_task4).
TraSw: Tracklet-Switch Adversarial Attacks against Multi-Object Tracking
Nov 17, 2021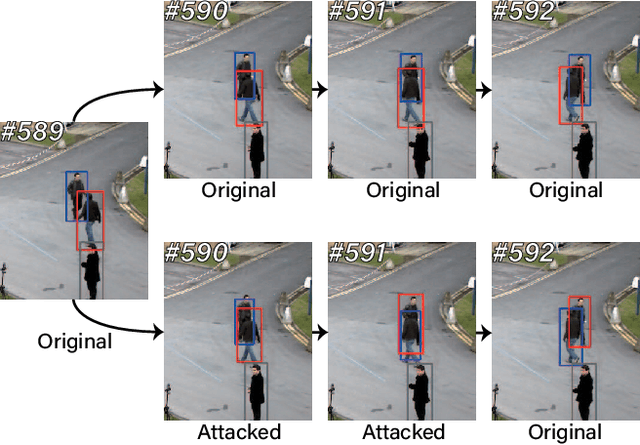
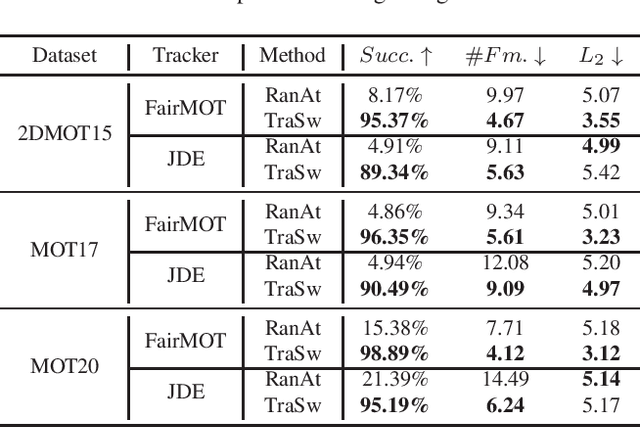
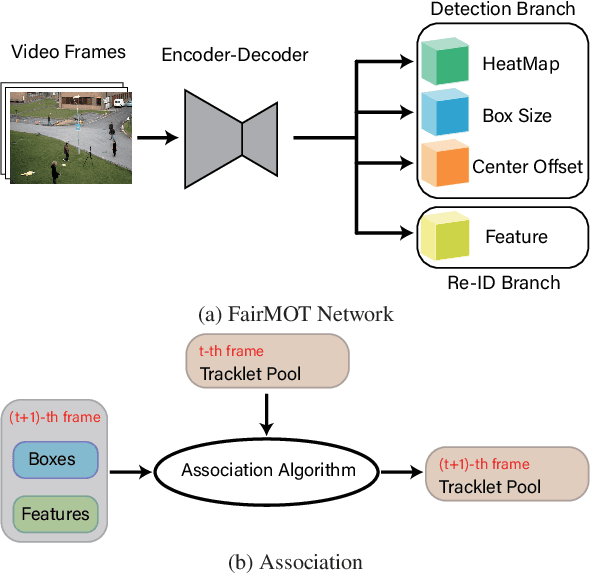
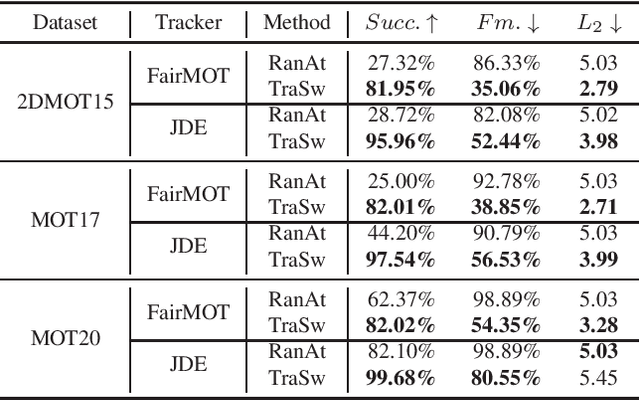
Benefiting from the development of Deep Neural Networks, Multi-Object Tracking (MOT) has achieved aggressive progress. Currently, the real-time Joint-Detection-Tracking (JDT) based MOT trackers gain increasing attention and derive many excellent models. However, the robustness of JDT trackers is rarely studied, and it is challenging to attack the MOT system since its mature association algorithms are designed to be robust against errors during tracking. In this work, we analyze the weakness of JDT trackers and propose a novel adversarial attack method, called Tracklet-Switch (TraSw), against the complete tracking pipeline of MOT. Specifically, a push-pull loss and a center leaping optimization are designed to generate adversarial examples for both re-ID feature and object detection. TraSw can fool the tracker to fail to track the targets in the subsequent frames by attacking very few frames. We evaluate our method on the advanced deep trackers (i.e., FairMOT, JDE, ByteTrack) using the MOT-Challenge datasets (i.e., 2DMOT15, MOT17, and MOT20). Experiments show that TraSw can achieve a high success rate of over 95% by attacking only five frames on average for the single-target attack and a reasonably high success rate of over 80% for the multiple-target attack. The code is available at https://github.com/DerryHub/FairMOT-attack .
Joint Learning Architecture for Multiple Object Tracking and Trajectory Forecasting
Aug 24, 2021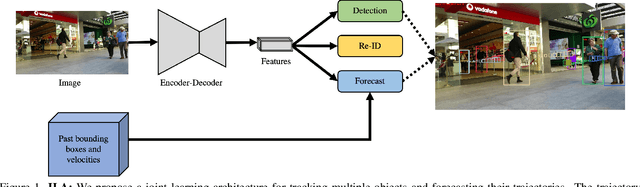
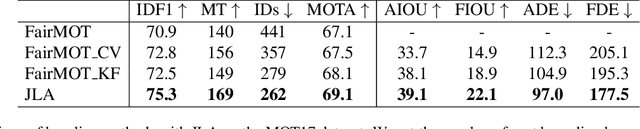
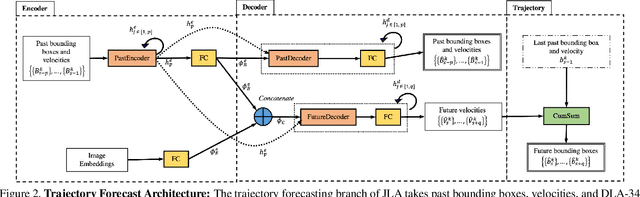
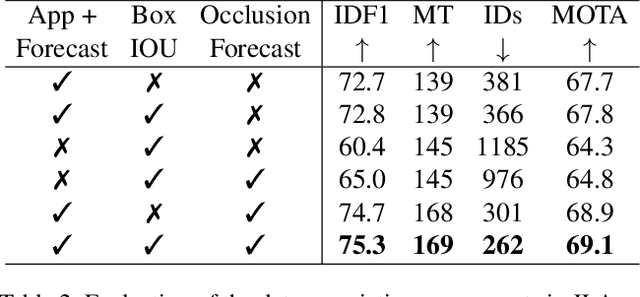
This paper introduces a joint learning architecture (JLA) for multiple object tracking (MOT) and trajectory forecasting in which the goal is to predict objects' current and future trajectories simultaneously. Motion prediction is widely used in several state of the art MOT methods to refine predictions in the form of bounding boxes. Typically, a Kalman Filter provides short-term estimations to help trackers correctly predict objects' locations in the current frame. However, the Kalman Filter-based approaches cannot predict non-linear trajectories. We propose to jointly train a tracking and trajectory forecasting model and use the predicted trajectory forecasts for short-term motion estimates in lieu of linear motion prediction methods such as the Kalman filter. We evaluate our JLA on the MOTChallenge benchmark. Evaluations result show that JLA performs better for short-term motion prediction and reduces ID switches by 33%, 31%, and 47% in the MOT16, MOT17, and MOT20 datasets, respectively, in comparison to FairMOT.
FGAGT: Flow-Guided Adaptive Graph Tracking
Nov 04, 2020
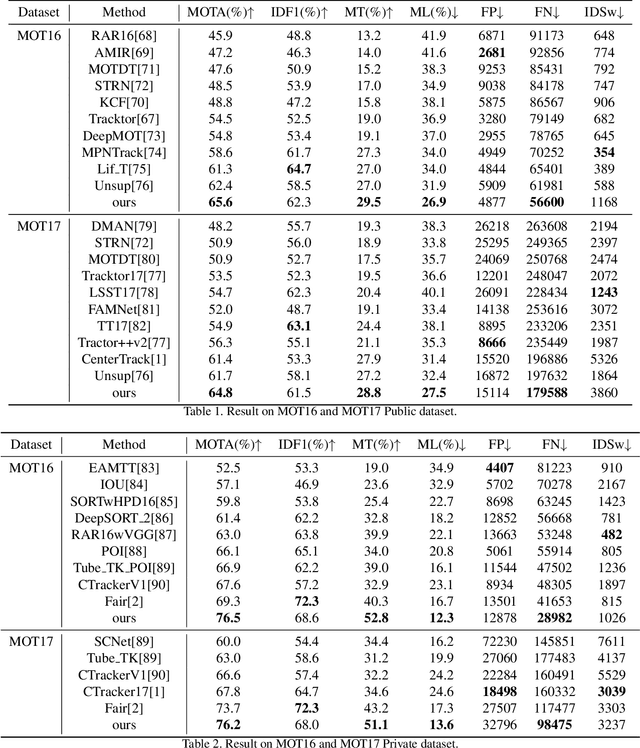
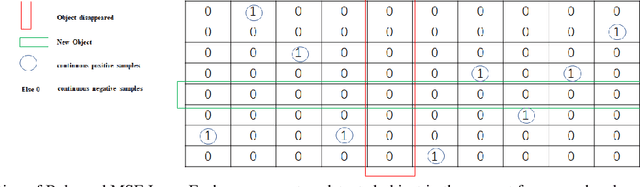
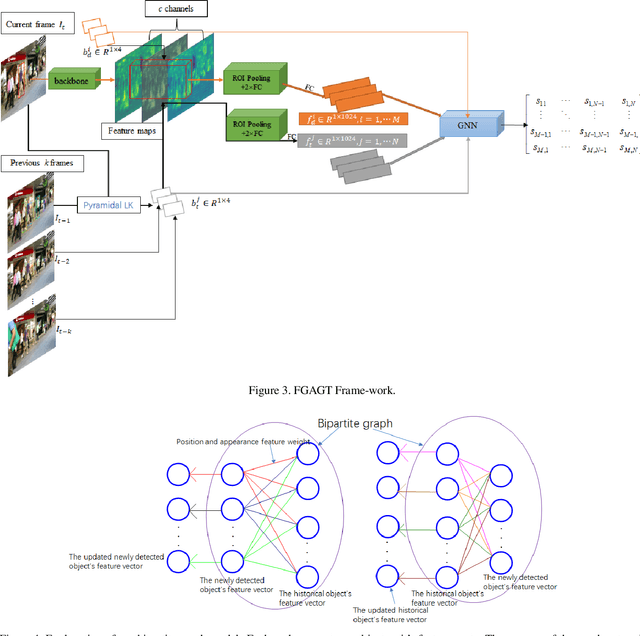
Most previous tracking methods usually use the optical flow method to estimate the position of the historical object in the current frame and then use the linear combination of feature similarity and IOU(Intersection over Union) to perform association matching near the position. However, the features used in these methods are not aligned, i.e., the features of the historical objects are extracted from the historical feature maps, not from the current frame, even the same object may undergo posture, angle, etc. changes during the movement, and even light intensity changes. In addition, most methods only use the appearance information when extracting the feature vector, not the position relationship, nor the feature information of the historical object, so the information is not fully utilized. In order to solve the above problems, we proposed the FGAGT tracker, which uses the optical flow method to predict the center position of the historical object in the current frame and extract the feature vector, so that the feature of the historical object can be aligned with the feature of the object in the current frame. Then these features are input into the graph neural network, and the global Spatio-temporal position and appearance information are integrated to update the feature vectors of all objects. In the training phase, we propose the Balanced MSE LOSS to balance the sample distribution for data association. Experiments show that our method reaches the level of state-of-the-art, where the MOTA index exceeds FairMOT by 2.5 points, and CenterTrack by 8.4 points on the MOT17 dataset, exceeds FairMOT by 1.6 points on the MOT16 dataset. Code will be avaliable.