 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHORNet: Task-Guided Frame Selection for Video Question Answering with Vision-Language Models
Mar 19, 2026Video question answering (VQA) with vision-language models (VLMs) depends critically on which frames are selected from the input video, yet most systems rely on uniform or heuristic sampling that cannot be optimized for downstream answering quality. We introduce \textbf{HORNet}, a lightweight frame selection policy trained with Group Relative Policy Optimization (GRPO) to learn which frames a frozen VLM needs to answer questions correctly. With fewer than 1M trainable parameters, HORNet reduces input frames by up to 99\% and VLM processing time by up to 93\%, while improving answer quality on short-form benchmarks (+1.7\% F1 on MSVD-QA) and achieving strong performance on temporal reasoning tasks (+7.3 points over uniform sampling on NExT-QA). We formalize this as Select Any Frames (SAF), a task that decouples visual input curation from VLM reasoning, and show that GRPO-trained selection generalizes better out-of-distribution than supervised and PPO alternatives. HORNet's policy further transfers across VLM answerers without retraining, yielding an additional 8.5\% relative gain when paired with a stronger model. Evaluated across six benchmarks spanning 341,877 QA pairs and 114.2 hours of video, our results demonstrate that optimizing \emph{what} a VLM sees is a practical and complementary alternative to optimizing what it generates while improving efficiency. Code is available at https://github.com/ostadabbas/HORNet.
Motion-o: Trajectory-Grounded Video Reasoning
Mar 19, 2026Recent research has made substantial progress on video reasoning, with many models leveraging spatio-temporal evidence chains to strengthen their inference capabilities. At the same time, a growing set of datasets and benchmarks now provides structured annotations designed to support and evaluate such reasoning. However, little attention has been paid to reasoning about \emph{how} objects move between observations: no prior work has articulated the motion patterns by connecting successive observations, leaving trajectory understanding implicit and difficult to verify. We formalize this missing capability as Spatial-Temporal-Trajectory (STT) reasoning and introduce \textbf{Motion-o}, a motion-centric video understanding extension to visual language models that makes trajectories explicit and verifiable. To enable motion reasoning, we also introduce a trajectory-grounding dataset artifact that expands sparse keyframe supervision via augmentation to yield denser bounding box tracks and a stronger trajectory-level training signal. Finally, we introduce Motion Chain of Thought (MCoT), a structured reasoning pathway that makes object trajectories through discrete \texttt{<motion/>} tag summarizing per-object direction, speed, and scale (of velocity) change to explicitly connect grounded observations into trajectories. To train Motion-o, we design a reward function that compels the model to reason directly over visual evidence, all while requiring no architectural modifications. Empirical results demonstrate that Motion-o improves spatial-temporal grounding and trajectory prediction while remaining fully compatible with existing frameworks, establishing motion reasoning as a critical extension for evidence-based video understanding. Code is available at https://github.com/ostadabbas/Motion-o.
UniTrack: Differentiable Graph Representation Learning for Multi-Object Tracking
Feb 04, 2026We present UniTrack, a plug-and-play graph-theoretic loss function designed to significantly enhance multi-object tracking (MOT) performance by directly optimizing tracking-specific objectives through unified differentiable learning. Unlike prior graph-based MOT methods that redesign tracking architectures, UniTrack provides a universal training objective that integrates detection accuracy, identity preservation, and spatiotemporal consistency into a single end-to-end trainable loss function, enabling seamless integration with existing MOT systems without architectural modifications. Through differentiable graph representation learning, UniTrack enables networks to learn holistic representations of motion continuity and identity relationships across frames. We validate UniTrack across diverse tracking models and multiple challenging benchmarks, demonstrating consistent improvements across all tested architectures and datasets including Trackformer, MOTR, FairMOT, ByteTrack, GTR, and MOTE. Extensive evaluations show up to 53\% reduction in identity switches and 12\% IDF1 improvements across challenging benchmarks, with GTR achieving peak performance gains of 9.7\% MOTA on SportsMOT.
Structured Over Scale: Learning Spatial Reasoning from Educational Video
Jan 30, 2026Vision-language models (VLMs) demonstrate impressive performance on standard video understanding benchmarks yet fail systematically on simple reasoning tasks that preschool children can solve, including counting, spatial reasoning, and compositional understanding. We hypothesize that the pedagogically-structured content of educational videos provides an ideal training signal for improving these capabilities. We introduce DoraVQA, a dataset of 5,344 question-answer pairs automatically extracted from 8 seasons of Dora the Explorer with precise timestamp alignment. Each episode follows a consistent \textit{context-question-pause-answer} structure that creates a self-contained learning environment analogous to interactive tutoring. We fine-tune both Qwen2 and Qwen3 using Group Relative Policy Optimization (GRPO), leveraging the clear correctness signals and structured reasoning traces inherent in educational content. Despite training exclusively on 38 hours of children's educational videos, our approach achieves improvements of 8-14 points on DoraVQA and state-of-the-art 86.16\% on CVBench, with strong transfer to Video-MME and NExT-QA, demonstrating effective generalization from narrow pedagogical content to broad multimodal understanding. Through cross-domain benchmarks, we show that VLMs can perform tasks that require robust reasoning learned from structured educational content, suggesting that content structure matters as much as content scale.
Track and Caption Any Motion: Query-Free Motion Discovery and Description in Videos
Dec 11, 2025



We propose Track and Caption Any Motion (TCAM), a motion-centric framework for automatic video understanding that discovers and describes motion patterns without user queries. Understanding videos in challenging conditions like occlusion, camouflage, or rapid movement often depends more on motion dynamics than static appearance. TCAM autonomously observes a video, identifies multiple motion activities, and spatially grounds each natural language description to its corresponding trajectory through a motion-field attention mechanism. Our key insight is that motion patterns, when aligned with contrastive vision-language representations, provide powerful semantic signals for recognizing and describing actions. Through unified training that combines global video-text alignment with fine-grained spatial correspondence, TCAM enables query-free discovery of multiple motion expressions via multi-head cross-attention. On the MeViS benchmark, TCAM achieves 58.4% video-to-text retrieval, 64.9 JF for spatial grounding, and discovers 4.8 relevant expressions per video with 84.7% precision, demonstrating strong cross-task generalization.
Lang2Motion: Bridging Language and Motion through Joint Embedding Spaces
Dec 11, 2025We present Lang2Motion, a framework for language-guided point trajectory generation by aligning motion manifolds with joint embedding spaces. Unlike prior work focusing on human motion or video synthesis, we generate explicit trajectories for arbitrary objects using motion extracted from real-world videos via point tracking. Our transformer-based auto-encoder learns trajectory representations through dual supervision: textual motion descriptions and rendered trajectory visualizations, both mapped through CLIP's frozen encoders. Lang2Motion achieves 34.2% Recall@1 on text-to-trajectory retrieval, outperforming video-based methods by 12.5 points, and improves motion accuracy by 33-52% (12.4 ADE vs 18.3-25.3) compared to video generation baselines. We demonstrate 88.3% Top-1 accuracy on human action recognition despite training only on diverse object motions, showing effective transfer across motion domains. Lang2Motion supports style transfer, semantic interpolation, and latent-space editing through CLIP-aligned trajectory representations.
K-Track: Kalman-Enhanced Tracking for Accelerating Deep Point Trackers on Edge Devices
Dec 11, 2025Point tracking in video sequences is a foundational capability for real-world computer vision applications, including robotics, autonomous systems, augmented reality, and video analysis. While recent deep learning-based trackers achieve state-of-the-art accuracy on challenging benchmarks, their reliance on per-frame GPU inference poses a major barrier to deployment on resource-constrained edge devices, where compute, power, and connectivity are limited. We introduce K-Track (Kalman-enhanced Tracking), a general-purpose, tracker-agnostic acceleration framework designed to bridge this deployment gap. K-Track reduces inference cost by combining sparse deep learning keyframe updates with lightweight Kalman filtering for intermediate frame prediction, using principled Bayesian uncertainty propagation to maintain temporal coherence. This hybrid strategy enables 5-10X speedup while retaining over 85% of the original trackers' accuracy. We evaluate K-Track across multiple state-of-the-art point trackers and demonstrate real-time performance on edge platforms such as the NVIDIA Jetson Nano and RTX Titan. By preserving accuracy while dramatically lowering computational requirements, K-Track provides a practical path toward deploying high-quality point tracking in real-world, resource-limited settings, closing the gap between modern tracking algorithms and deployable vision systems.
Uncertainty-Aware Ankle Exoskeleton Control
Aug 28, 2025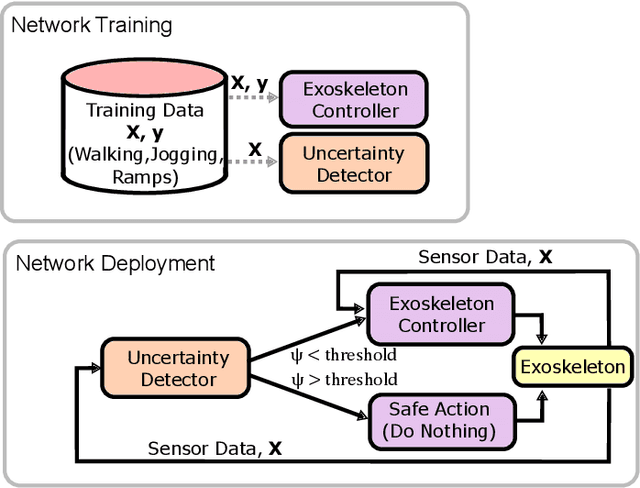
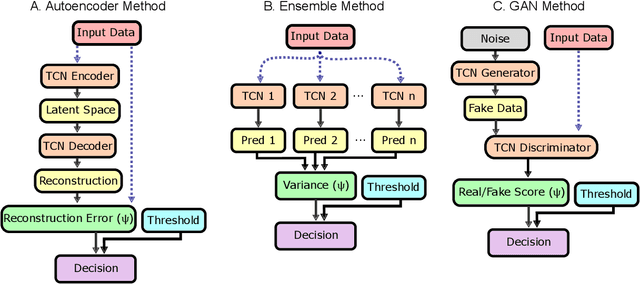
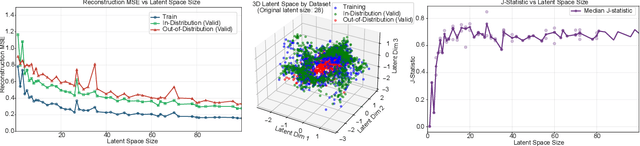

Lower limb exoskeletons show promise to assist human movement, but their utility is limited by controllers designed for discrete, predefined actions in controlled environments, restricting their real-world applicability. We present an uncertainty-aware control framework that enables ankle exoskeletons to operate safely across diverse scenarios by automatically disengaging when encountering unfamiliar movements. Our approach uses an uncertainty estimator to classify movements as similar (in-distribution) or different (out-of-distribution) relative to actions in the training set. We evaluated three architectures (model ensembles, autoencoders, and generative adversarial networks) on an offline dataset and tested the strongest performing architecture (ensemble of gait phase estimators) online. The online test demonstrated the ability of our uncertainty estimator to turn assistance on and off as the user transitioned between in-distribution and out-of-distribution tasks (F1: 89.2). This new framework provides a path for exoskeletons to safely and autonomously support human movement in unstructured, everyday environments.
Multiple Toddler Tracking in Indoor Videos
Nov 29, 2023



Multiple toddler tracking (MTT) involves identifying and differentiating toddlers in video footage. While conventional multi-object tracking (MOT) algorithms are adept at tracking diverse objects, toddlers pose unique challenges due to their unpredictable movements, various poses, and similar appearance. Tracking toddlers in indoor environments introduces additional complexities such as occlusions and limited fields of view. In this paper, we address the challenges of MTT and propose MTTSort, a customized method built upon the DeepSort algorithm. MTTSort is designed to track multiple toddlers in indoor videos accurately. Our contributions include discussing the primary challenges in MTT, introducing a genetic algorithm to optimize hyperparameters, proposing an accurate tracking algorithm, and curating the MTTrack dataset using unbiased AI co-labeling techniques. We quantitatively compare MTTSort to state-of-the-art MOT methods on MTTrack, DanceTrack, and MOT15 datasets. In our evaluation, the proposed method outperformed other MOT methods, achieving 0.98, 0.68, and 0.98 in multiple object tracking accuracy (MOTA), higher order tracking accuracy (HOTA), and iterative and discriminative framework 1 (IDF1) metrics, respectively.