 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHORNet: Task-Guided Frame Selection for Video Question Answering with Vision-Language Models
Mar 19, 2026Video question answering (VQA) with vision-language models (VLMs) depends critically on which frames are selected from the input video, yet most systems rely on uniform or heuristic sampling that cannot be optimized for downstream answering quality. We introduce \textbf{HORNet}, a lightweight frame selection policy trained with Group Relative Policy Optimization (GRPO) to learn which frames a frozen VLM needs to answer questions correctly. With fewer than 1M trainable parameters, HORNet reduces input frames by up to 99\% and VLM processing time by up to 93\%, while improving answer quality on short-form benchmarks (+1.7\% F1 on MSVD-QA) and achieving strong performance on temporal reasoning tasks (+7.3 points over uniform sampling on NExT-QA). We formalize this as Select Any Frames (SAF), a task that decouples visual input curation from VLM reasoning, and show that GRPO-trained selection generalizes better out-of-distribution than supervised and PPO alternatives. HORNet's policy further transfers across VLM answerers without retraining, yielding an additional 8.5\% relative gain when paired with a stronger model. Evaluated across six benchmarks spanning 341,877 QA pairs and 114.2 hours of video, our results demonstrate that optimizing \emph{what} a VLM sees is a practical and complementary alternative to optimizing what it generates while improving efficiency. Code is available at https://github.com/ostadabbas/HORNet.
Motion-o: Trajectory-Grounded Video Reasoning
Mar 19, 2026Recent research has made substantial progress on video reasoning, with many models leveraging spatio-temporal evidence chains to strengthen their inference capabilities. At the same time, a growing set of datasets and benchmarks now provides structured annotations designed to support and evaluate such reasoning. However, little attention has been paid to reasoning about \emph{how} objects move between observations: no prior work has articulated the motion patterns by connecting successive observations, leaving trajectory understanding implicit and difficult to verify. We formalize this missing capability as Spatial-Temporal-Trajectory (STT) reasoning and introduce \textbf{Motion-o}, a motion-centric video understanding extension to visual language models that makes trajectories explicit and verifiable. To enable motion reasoning, we also introduce a trajectory-grounding dataset artifact that expands sparse keyframe supervision via augmentation to yield denser bounding box tracks and a stronger trajectory-level training signal. Finally, we introduce Motion Chain of Thought (MCoT), a structured reasoning pathway that makes object trajectories through discrete \texttt{<motion/>} tag summarizing per-object direction, speed, and scale (of velocity) change to explicitly connect grounded observations into trajectories. To train Motion-o, we design a reward function that compels the model to reason directly over visual evidence, all while requiring no architectural modifications. Empirical results demonstrate that Motion-o improves spatial-temporal grounding and trajectory prediction while remaining fully compatible with existing frameworks, establishing motion reasoning as a critical extension for evidence-based video understanding. Code is available at https://github.com/ostadabbas/Motion-o.
UniTrack: Differentiable Graph Representation Learning for Multi-Object Tracking
Feb 04, 2026We present UniTrack, a plug-and-play graph-theoretic loss function designed to significantly enhance multi-object tracking (MOT) performance by directly optimizing tracking-specific objectives through unified differentiable learning. Unlike prior graph-based MOT methods that redesign tracking architectures, UniTrack provides a universal training objective that integrates detection accuracy, identity preservation, and spatiotemporal consistency into a single end-to-end trainable loss function, enabling seamless integration with existing MOT systems without architectural modifications. Through differentiable graph representation learning, UniTrack enables networks to learn holistic representations of motion continuity and identity relationships across frames. We validate UniTrack across diverse tracking models and multiple challenging benchmarks, demonstrating consistent improvements across all tested architectures and datasets including Trackformer, MOTR, FairMOT, ByteTrack, GTR, and MOTE. Extensive evaluations show up to 53\% reduction in identity switches and 12\% IDF1 improvements across challenging benchmarks, with GTR achieving peak performance gains of 9.7\% MOTA on SportsMOT.
Structured Over Scale: Learning Spatial Reasoning from Educational Video
Jan 30, 2026Vision-language models (VLMs) demonstrate impressive performance on standard video understanding benchmarks yet fail systematically on simple reasoning tasks that preschool children can solve, including counting, spatial reasoning, and compositional understanding. We hypothesize that the pedagogically-structured content of educational videos provides an ideal training signal for improving these capabilities. We introduce DoraVQA, a dataset of 5,344 question-answer pairs automatically extracted from 8 seasons of Dora the Explorer with precise timestamp alignment. Each episode follows a consistent \textit{context-question-pause-answer} structure that creates a self-contained learning environment analogous to interactive tutoring. We fine-tune both Qwen2 and Qwen3 using Group Relative Policy Optimization (GRPO), leveraging the clear correctness signals and structured reasoning traces inherent in educational content. Despite training exclusively on 38 hours of children's educational videos, our approach achieves improvements of 8-14 points on DoraVQA and state-of-the-art 86.16\% on CVBench, with strong transfer to Video-MME and NExT-QA, demonstrating effective generalization from narrow pedagogical content to broad multimodal understanding. Through cross-domain benchmarks, we show that VLMs can perform tasks that require robust reasoning learned from structured educational content, suggesting that content structure matters as much as content scale.
Lang2Motion: Bridging Language and Motion through Joint Embedding Spaces
Dec 11, 2025We present Lang2Motion, a framework for language-guided point trajectory generation by aligning motion manifolds with joint embedding spaces. Unlike prior work focusing on human motion or video synthesis, we generate explicit trajectories for arbitrary objects using motion extracted from real-world videos via point tracking. Our transformer-based auto-encoder learns trajectory representations through dual supervision: textual motion descriptions and rendered trajectory visualizations, both mapped through CLIP's frozen encoders. Lang2Motion achieves 34.2% Recall@1 on text-to-trajectory retrieval, outperforming video-based methods by 12.5 points, and improves motion accuracy by 33-52% (12.4 ADE vs 18.3-25.3) compared to video generation baselines. We demonstrate 88.3% Top-1 accuracy on human action recognition despite training only on diverse object motions, showing effective transfer across motion domains. Lang2Motion supports style transfer, semantic interpolation, and latent-space editing through CLIP-aligned trajectory representations.
Learning Multimodal AI Algorithms for Amplifying Limited User Input into High-dimensional Control Space
May 16, 2025Current invasive assistive technologies are designed to infer high-dimensional motor control signals from severely paralyzed patients. However, they face significant challenges, including public acceptance, limited longevity, and barriers to commercialization. Meanwhile, noninvasive alternatives often rely on artifact-prone signals, require lengthy user training, and struggle to deliver robust high-dimensional control for dexterous tasks. To address these issues, this study introduces a novel human-centered multimodal AI approach as intelligent compensatory mechanisms for lost motor functions that could potentially enable patients with severe paralysis to control high-dimensional assistive devices, such as dexterous robotic arms, using limited and noninvasive inputs. In contrast to the current state-of-the-art (SoTA) noninvasive approaches, our context-aware, multimodal shared-autonomy framework integrates deep reinforcement learning algorithms to blend limited low-dimensional user input with real-time environmental perception, enabling adaptive, dynamic, and intelligent interpretation of human intent for complex dexterous manipulation tasks, such as pick-and-place. The results from our ARAS (Adaptive Reinforcement learning for Amplification of limited inputs in Shared autonomy) trained with synthetic users over 50,000 computer simulation episodes demonstrated the first successful implementation of the proposed closed-loop human-in-the-loop paradigm, outperforming the SoTA shared autonomy algorithms. Following a zero-shot sim-to-real transfer, ARAS was evaluated on 23 human subjects, demonstrating high accuracy in dynamic intent detection and smooth, stable 3D trajectory control for dexterous pick-and-place tasks. ARAS user study achieved a high task success rate of 92.88%, with short completion times comparable to those of SoTA invasive assistive technologies.
STREAMS: An Assistive Multimodal AI Framework for Empowering Biosignal Based Robotic Controls
Oct 04, 2024



End-effector based assistive robots face persistent challenges in generating smooth and robust trajectories when controlled by human's noisy and unreliable biosignals such as muscle activities and brainwaves. The produced endpoint trajectories are often jerky and imprecise to perform complex tasks such as stable robotic grasping. We propose STREAMS (Self-Training Robotic End-to-end Adaptive Multimodal Shared autonomy) as a novel framework leveraged deep reinforcement learning to tackle this challenge in biosignal based robotic control systems. STREAMS blends environmental information and synthetic user input into a Deep Q Learning Network (DQN) pipeline for an interactive end-to-end and self-training mechanism to produce smooth trajectories for the control of end-effector based robots. The proposed framework achieved a high-performance record of 98% in simulation with dynamic target estimation and acquisition without any pre-existing datasets. As a zero-shot sim-to-real user study with five participants controlling a physical robotic arm with noisy head movements, STREAMS (as an assistive mode) demonstrated significant improvements in trajectory stabilization, user satisfaction, and task performance reported as a success rate of 83% compared to manual mode which was 44% without any task support. STREAMS seeks to improve biosignal based assistive robotic controls by offering an interactive, end-to-end solution that stabilizes end-effector trajectories, enhancing task performance and accuracy.
Temporal-controlled Frame Swap for Generating High-Fidelity Stereo Driving Data for Autonomy Analysis
Jun 12, 2023This paper presents a novel approach, TeFS (Temporal-controlled Frame Swap), to generate synthetic stereo driving data for visual simultaneous localization and mapping (vSLAM) tasks. TeFS is designed to overcome the lack of native stereo vision support in commercial driving simulators, and we demonstrate its effectiveness using Grand Theft Auto V (GTA V), a high-budget open-world video game engine. We introduce GTAV-TeFS, the first large-scale GTA V stereo-driving dataset, containing over 88,000 high-resolution stereo RGB image pairs, along with temporal information, GPS coordinates, camera poses, and full-resolution dense depth maps. GTAV-TeFS offers several advantages over other synthetic stereo datasets and enables the evaluation and enhancement of state-of-the-art stereo vSLAM models under GTA V's environment. We validate the quality of the stereo data collected using TeFS by conducting a comparative analysis with the conventional dual-viewport data using an open-source simulator. We also benchmark various vSLAM models using the challenging-case comparison groups included in GTAV-TeFS, revealing the distinct advantages and limitations inherent to each model. The goal of our work is to bring more high-fidelity stereo data from commercial-grade game simulators into the research domain and push the boundary of vSLAM models.
Bridging the Domain Gap between Synthetic and Real-World Data for Autonomous Driving
Jun 05, 2023



Modern autonomous systems require extensive testing to ensure reliability and build trust in ground vehicles. However, testing these systems in the real-world is challenging due to the lack of large and diverse datasets, especially in edge cases. Therefore, simulations are necessary for their development and evaluation. However, existing open-source simulators often exhibit a significant gap between synthetic and real-world domains, leading to deteriorated mobility performance and reduced platform reliability when using simulation data. To address this issue, our Scoping Autonomous Vehicle Simulation (SAVeS) platform benchmarks the performance of simulated environments for autonomous ground vehicle testing between synthetic and real-world domains. Our platform aims to quantify the domain gap and enable researchers to develop and test autonomous systems in a controlled environment. Additionally, we propose using domain adaptation technologies to address the domain gap between synthetic and real-world data with our SAVeS$^+$ extension. Our results demonstrate that SAVeS$^+$ is effective in helping to close the gap between synthetic and real-world domains and yields comparable performance for models trained with processed synthetic datasets to those trained on real-world datasets of same scale. This paper highlights our efforts to quantify and address the domain gap between synthetic and real-world data for autonomy simulation. By enabling researchers to develop and test autonomous systems in a controlled environment, we hope to bring autonomy simulation one step closer to realization.
Prior-Aware Synthetic Data to the Rescue: Animal Pose Estimation with Very Limited Real Data
Aug 30, 2022
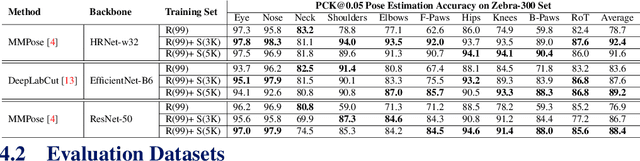
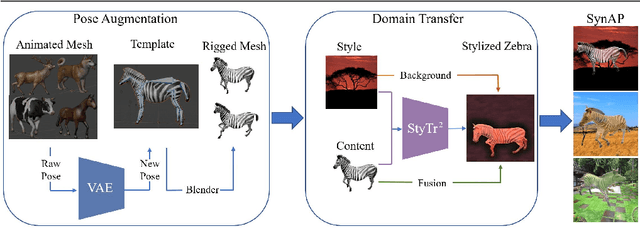
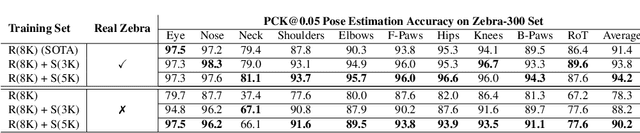
Accurately annotated image datasets are essential components for studying animal behaviors from their poses. Compared to the number of species we know and may exist, the existing labeled pose datasets cover only a small portion of them, while building comprehensive large-scale datasets is prohibitively expensive. Here, we present a very data efficient strategy targeted for pose estimation in quadrupeds that requires only a small amount of real images from the target animal. It is confirmed that fine-tuning a backbone network with pretrained weights on generic image datasets such as ImageNet can mitigate the high demand for target animal pose data and shorten the training time by learning the the prior knowledge of object segmentation and keypoint estimation in advance. However, when faced with serious data scarcity (i.e., $<10^2$ real images), the model performance stays unsatisfactory, particularly for limbs with considerable flexibility and several comparable parts. We therefore introduce a prior-aware synthetic animal data generation pipeline called PASyn to augment the animal pose data essential for robust pose estimation. PASyn generates a probabilistically-valid synthetic pose dataset, SynAP, through training a variational generative model on several animated 3D animal models. In addition, a style transfer strategy is utilized to blend the synthetic animal image into the real backgrounds. We evaluate the improvement made by our approach with three popular backbone networks and test their pose estimation accuracy on publicly available animal pose images as well as collected from real animals in a zoo.