 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausally Disentangled Contrastive Learning for Multilingual Speaker Embeddings
Feb 01, 2026Self-supervised speaker embeddings are widely used in speaker verification systems, but prior work has shown that they often encode sensitive demographic attributes, raising fairness and privacy concerns. This paper investigates the extent to which demographic information, specifically gender, age, and accent, is present in SimCLR-trained speaker embeddings and whether such leakage can be mitigated without severely degrading speaker verification performance. We study two debiasing strategies: adversarial training through gradient reversal and a causal bottleneck architecture that explicitly separates demographic and residual information. Demographic leakage is quantified using both linear and nonlinear probing classifiers, while speaker verification performance is evaluated using ROC-AUC and EER. Our results show that gender information is strongly and linearly encoded in baseline embeddings, whereas age and accent are weaker and primarily nonlinearly represented. Adversarial debiasing reduces gender leakage but has limited effect on age and accent and introduces a clear trade-off with verification accuracy. The causal bottleneck further suppresses demographic information, particularly in the residual representation, but incurs substantial performance degradation. These findings highlight fundamental limitations in mitigating demographic leakage in self-supervised speaker embeddings and clarify the trade-offs inherent in current debiasing approaches.
Hybrid Vision Transformer_GAN Attribute Neutralizer for Mitigating Bias in Chest X_Ray Diagnosis
Jan 21, 2026Bias in chest X-ray classifiers frequently stems from sex- and age-related shortcuts, leading to systematic underdiagnosis of minority subgroups. Previous pixel-space attribute neutralizers, which rely on convolutional encoders, lessen but do not fully remove this attribute leakage at clinically usable edit strengths. This study evaluates whether substituting the U-Net convolutional encoder with a Vision Transformer backbone in the Attribute-Neutral Framework can reduce demographic attribute leakage while preserving diagnostic accuracy. A data-efficient Image Transformer Small (DeiT-S) neutralizer was trained on the ChestX-ray14 dataset. Its edited images, generated across eleven edit-intensity levels, were evaluated with an independent AI judge for attribute leakage and with a convolutional neural network (ConvNet) for disease prediction. At a moderate edit level (alpha = 0.5), the Vision Transformer (ViT) neutralizer reduces patient sex-recognition area under the curve (AUC) to approximately 0.80, about 10 percentage points below the original framework's convolutional U-Net encoder, despite being trained for only half as many epochs. Meanwhile, macro receiver operating characteristic area under the curve (ROC AUC) across 15 findings stays within five percentage points of the unedited baseline, and the worst-case subgroup AUC remains near 0.70. These results indicate that global self-attention vision models can further suppress attribute leakage without sacrificing clinical utility, suggesting a practical route toward fairer chest X-ray AI.
Assessing the quality and coherence of word embeddings after SCM-based intersectional bias mitigation
Jan 07, 2026Static word embeddings often absorb social biases from the text they learn from, and those biases can quietly shape downstream systems. Prior work that uses the Stereotype Content Model (SCM) has focused mostly on single-group bias along warmth and competence. We broaden that lens to intersectional bias by building compound representations for pairs of social identities through summation or concatenation, and by applying three debiasing strategies: Subtraction, Linear Projection, and Partial Projection. We study three widely used embedding families (Word2Vec, GloVe, and ConceptNet Numberbatch) and assess them with two complementary views of utility: whether local neighborhoods remain coherent and whether analogy behavior is preserved. Across models, SCM-based mitigation carries over well to the intersectional case and largely keeps the overall semantic landscape intact. The main cost is a familiar trade off: methods that most tightly preserve geometry tend to be more cautious about analogy behavior, while more assertive projections can improve analogies at the expense of strict neighborhood stability. Partial Projection is reliably conservative and keeps representations steady; Linear Projection can be more assertive; Subtraction is a simple baseline that remains competitive. The choice between summation and concatenation depends on the embedding family and the application goal. Together, these findings suggest that intersectional debiasing with SCM is practical in static embed- dings, and they offer guidance for selecting aggregation and debiasing settings when balancing stability against analogy performance.
Cross-Language Speaker Attribute Prediction Using MIL and RL
Jan 06, 2026We study multilingual speaker attribute prediction under linguistic variation, domain mismatch, and data imbalance across languages. We propose RLMIL-DAT, a multilingual extension of the reinforced multiple instance learning framework that combines reinforcement learning based instance selection with domain adversarial training to encourage language invariant utterance representations. We evaluate the approach on a five language Twitter corpus in a few shot setting and on a VoxCeleb2 derived corpus covering forty languages in a zero shot setting for gender and age prediction. Across a wide range of model configurations and multiple random seeds, RLMIL-DAT consistently improves Macro F1 compared to standard multiple instance learning and the original reinforced multiple instance learning framework. The largest gains are observed for gender prediction, while age prediction remains more challenging and shows smaller but positive improvements. Ablation experiments indicate that domain adversarial training is the primary contributor to the performance gains, enabling effective transfer from high resource English to lower resource languages by discouraging language specific cues in the shared encoder. In the zero shot setting on the smaller VoxCeleb2 subset, improvements are generally positive but less consistent, reflecting limited statistical power and the difficulty of generalizing to many unseen languages. Overall, the results demonstrate that combining instance selection with adversarial domain adaptation is an effective and robust strategy for cross lingual speaker attribute prediction.
Exploring a Hybrid Deep Learning Approach for Anomaly Detection in Mental Healthcare Provider Billing: Addressing Label Scarcity through Semi-Supervised Anomaly Detection
Jul 02, 2025



The complexity of mental healthcare billing enables anomalies, including fraud. While machine learning methods have been applied to anomaly detection, they often struggle with class imbalance, label scarcity, and complex sequential patterns. This study explores a hybrid deep learning approach combining Long Short-Term Memory (LSTM) networks and Transformers, with pseudo-labeling via Isolation Forests (iForest) and Autoencoders (AE). Prior work has not evaluated such hybrid models trained on pseudo-labeled data in the context of healthcare billing. The approach is evaluated on two real-world billing datasets related to mental healthcare. The iForest LSTM baseline achieves the highest recall (0.963) on declaration-level data. On the operation-level data, the hybrid iForest-based model achieves the highest recall (0.744), though at the cost of lower precision. These findings highlight the potential of combining pseudo-labeling with hybrid deep learning in complex, imbalanced anomaly detection settings.
A Topological Improvement of the Overall Performance of Sparse Evolutionary Training: Motif-Based Structural Optimization of Sparse MLPs Project
Jun 10, 2025

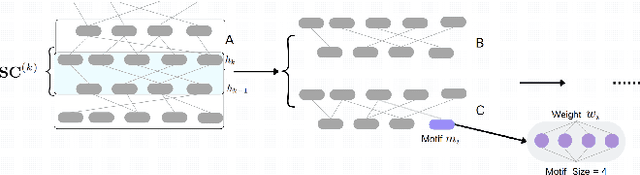
Deep Neural Networks (DNNs) have been proven to be exceptionally effective and have been applied across diverse domains within deep learning. However, as DNN models increase in complexity, the demand for reduced computational costs and memory overheads has become increasingly urgent. Sparsity has emerged as a leading approach in this area. The robustness of sparse Multi-layer Perceptrons (MLPs) for supervised feature selection, along with the application of Sparse Evolutionary Training (SET), illustrates the feasibility of reducing computational costs without compromising accuracy. Moreover, it is believed that the SET algorithm can still be improved through a structural optimization method called motif-based optimization, with potential efficiency gains exceeding 40% and a performance decline of under 4%. This research investigates whether the structural optimization of Sparse Evolutionary Training applied to Multi-layer Perceptrons (SET-MLP) can enhance performance and to what extent this improvement can be achieved.
A Framework for Multi-View Multiple Object Tracking using Single-View Multi-Object Trackers on Fish Data
May 22, 2025Multi-object tracking (MOT) in computer vision has made significant advancements, yet tracking small fish in underwater environments presents unique challenges due to complex 3D motions and data noise. Traditional single-view MOT models often fall short in these settings. This thesis addresses these challenges by adapting state-of-the-art single-view MOT models, FairMOT and YOLOv8, for underwater fish detecting and tracking in ecological studies. The core contribution of this research is the development of a multi-view framework that utilizes stereo video inputs to enhance tracking accuracy and fish behavior pattern recognition. By integrating and evaluating these models on underwater fish video datasets, the study aims to demonstrate significant improvements in precision and reliability compared to single-view approaches. The proposed framework detects fish entities with a relative accuracy of 47% and employs stereo-matching techniques to produce a novel 3D output, providing a more comprehensive understanding of fish movements and interactions
MARINE: A Computer Vision Model for Detecting Rare Predator-Prey Interactions in Animal Videos
Jul 25, 2024



Encounters between predator and prey play an essential role in ecosystems, but their rarity makes them difficult to detect in video recordings. Although advances in action recognition (AR) and temporal action detection (AD), especially transformer-based models and vision foundation models, have achieved high performance on human action datasets, animal videos remain relatively under-researched. This thesis addresses this gap by proposing the model MARINE, which utilizes motion-based frame selection designed for fast animal actions and DINOv2 feature extraction with a trainable classification head for action recognition. MARINE outperforms VideoMAE in identifying predator attacks in videos of fish, both on a small and specific coral reef dataset (81.53\% against 52.64\% accuracy), and on a subset of the more extensive Animal Kingdom dataset (94.86\% against 83.14\% accuracy). In a multi-label setting on a representative sample of Animal Kingdom, MARINE achieves 23.79\% mAP, positioning it mid-field among existing benchmarks. Furthermore, in an AD task on the coral reef dataset, MARINE achieves 80.78\% AP (against VideoMAE's 34.89\%) although at a lowered t-IoU threshold of 25\%. Therefore, despite room for improvement, MARINE offers an effective starter framework to apply to AR and AD tasks on animal recordings and thus contribute to the study of natural ecosystems.
Leveraging Foundation Models via Knowledge Distillation in Multi-Object Tracking: Distilling DINOv2 Features to FairMOT
Jul 25, 2024Multiple Object Tracking (MOT) is a computer vision task that has been employed in a variety of sectors. Some common limitations in MOT are varying object appearances, occlusions, or crowded scenes. To address these challenges, machine learning methods have been extensively deployed, leveraging large datasets, sophisticated models, and substantial computational resources. Due to practical limitations, access to the above is not always an option. However, with the recent release of foundation models by prominent AI companies, pretrained models have been trained on vast datasets and resources using state-of-the-art methods. This work tries to leverage one such foundation model, called DINOv2, through using knowledge distillation. The proposed method uses a teacher-student architecture, where DINOv2 is the teacher and the FairMOT backbone HRNetv2 W18 is the student. The results imply that although the proposed method shows improvements in certain scenarios, it does not consistently outperform the original FairMOT model. These findings highlight the potential and limitations of applying foundation models in knowledge