 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExdark
Papers and Code
WARLearn: Weather-Adaptive Representation Learning
Nov 21, 2024



This paper introduces WARLearn, a novel framework designed for adaptive representation learning in challenging and adversarial weather conditions. Leveraging the in-variance principal used in Barlow Twins, we demonstrate the capability to port the existing models initially trained on clear weather data to effectively handle adverse weather conditions. With minimal additional training, our method exhibits remarkable performance gains in scenarios characterized by fog and low-light conditions. This adaptive framework extends its applicability beyond adverse weather settings, offering a versatile solution for domains exhibiting variations in data distributions. Furthermore, WARLearn is invaluable in scenarios where data distributions undergo significant shifts over time, enabling models to remain updated and accurate. Our experimental findings reveal a remarkable performance, with a mean average precision (mAP) of 52.6% on unseen real-world foggy dataset (RTTS). Similarly, in low light conditions, our framework achieves a mAP of 55.7% on unseen real-world low light dataset (ExDark). Notably, WARLearn surpasses the performance of state-of-the-art frameworks including FeatEnHancer, Image Adaptive YOLO, DENet, C2PNet, PairLIE and ZeroDCE, by a substantial margin in adverse weather, improving the baseline performance in both foggy and low light conditions. The WARLearn code is available at https://github.com/ShubhamAgarwal12/WARLearn
Enhanced Model Robustness to Input Corruptions by Per-corruption Adaptation of Normalization Statistics
Jul 08, 2024Developing a reliable vision system is a fundamental challenge for robotic technologies (e.g., indoor service robots and outdoor autonomous robots) which can ensure reliable navigation even in challenging environments such as adverse weather conditions (e.g., fog, rain), poor lighting conditions (e.g., over/under exposure), or sensor degradation (e.g., blurring, noise), and can guarantee high performance in safety-critical functions. Current solutions proposed to improve model robustness usually rely on generic data augmentation techniques or employ costly test-time adaptation methods. In addition, most approaches focus on addressing a single vision task (typically, image recognition) utilising synthetic data. In this paper, we introduce Per-corruption Adaptation of Normalization statistics (PAN) to enhance the model robustness of vision systems. Our approach entails three key components: (i) a corruption type identification module, (ii) dynamic adjustment of normalization layer statistics based on identified corruption type, and (iii) real-time update of these statistics according to input data. PAN can integrate seamlessly with any convolutional model for enhanced accuracy in several robot vision tasks. In our experiments, PAN obtains robust performance improvement on challenging real-world corrupted image datasets (e.g., OpenLoris, ExDark, ACDC), where most of the current solutions tend to fail. Moreover, PAN outperforms the baseline models by 20-30% on synthetic benchmarks in object recognition tasks.
SDNIA-YOLO: A Robust Object Detection Model for Extreme Weather Conditions
Jun 18, 2024



Though current object detection models based on deep learning have achieved excellent results on many conventional benchmark datasets, their performance will dramatically decline on real-world images taken under extreme conditions. Existing methods either used image augmentation based on traditional image processing algorithms or applied customized and scene-limited image adaptation technologies for robust modeling. This study thus proposes a stylization data-driven neural-image-adaptive YOLO (SDNIA-YOLO), which improves the model's robustness by enhancing image quality adaptively and learning valuable information related to extreme weather conditions from images synthesized by neural style transfer (NST). Experiments show that the developed SDNIA-YOLOv3 achieves significant mAP@.5 improvements of at least 15% on the real-world foggy (RTTS) and lowlight (ExDark) test sets compared with the baseline model. Besides, the experiments also highlight the outstanding potential of stylization data in simulating extreme weather conditions. The developed SDNIA-YOLO remains excellent characteristics of the native YOLO to a great extent, such as end-to-end one-stage, data-driven, and fast.
Boosting Object Detection with Zero-Shot Day-Night Domain Adaptation
Dec 02, 2023



Detecting objects in low-light scenarios presents a persistent challenge, as detectors trained on well-lit data exhibit significant performance degradation on low-light data due to the low visibility. Previous methods mitigate this issue by investigating image enhancement or object detection techniques using low-light image datasets. However, the progress is impeded by the inherent difficulties associated with collecting and annotating low-light images. To address this challenge, we propose to boost low-light object detection with zero-shot day-night domain adaptation, which aims to generalize a detector from well-lit scenarios to low-light ones without requiring real low-light data. We first design a reflectance representation learning module to learn Retinex-based illumination invariance in images with a carefully designed illumination invariance reinforcement strategy. Next, an interchange-redecomposition-coherence procedure is introduced to improve over the vanilla Retinex image decomposition process by performing two sequential image decompositions and introducing a redecomposition cohering loss. Extensive experiments on ExDark, DARK FACE and CODaN datasets show strong low-light generalizability of our method.
DEFormer: DCT-driven Enhancement Transformer for Low-light Image and Dark Vision
Sep 13, 2023



The goal of low-light image enhancement is to restore the color and details of the image and is of great significance for high-level visual tasks in autonomous driving. However, it is difficult to restore the lost details in the dark area by relying only on the RGB domain. In this paper we introduce frequency as a new clue into the network and propose a novel DCT-driven enhancement transformer (DEFormer). First, we propose a learnable frequency branch (LFB) for frequency enhancement contains DCT processing and curvature-based frequency enhancement (CFE). CFE calculates the curvature of each channel to represent the detail richness of different frequency bands, then we divides the frequency features, which focuses on frequency bands with richer textures. In addition, we propose a cross domain fusion (CDF) for reducing the differences between the RGB domain and the frequency domain. We also adopt DEFormer as a preprocessing in dark detection, DEFormer effectively improves the performance of the detector, bringing 2.1% and 3.4% improvement in ExDark and DARK FACE datasets on mAP respectively.
FeatEnHancer: Enhancing Hierarchical Features for Object Detection and Beyond Under Low-Light Vision
Aug 07, 2023



Extracting useful visual cues for the downstream tasks is especially challenging under low-light vision. Prior works create enhanced representations by either correlating visual quality with machine perception or designing illumination-degrading transformation methods that require pre-training on synthetic datasets. We argue that optimizing enhanced image representation pertaining to the loss of the downstream task can result in more expressive representations. Therefore, in this work, we propose a novel module, FeatEnHancer, that hierarchically combines multiscale features using multiheaded attention guided by task-related loss function to create suitable representations. Furthermore, our intra-scale enhancement improves the quality of features extracted at each scale or level, as well as combines features from different scales in a way that reflects their relative importance for the task at hand. FeatEnHancer is a general-purpose plug-and-play module and can be incorporated into any low-light vision pipeline. We show with extensive experimentation that the enhanced representation produced with FeatEnHancer significantly and consistently improves results in several low-light vision tasks, including dark object detection (+5.7 mAP on ExDark), face detection (+1.5 mAPon DARK FACE), nighttime semantic segmentation (+5.1 mIoU on ACDC ), and video object detection (+1.8 mAP on DarkVision), highlighting the effectiveness of enhancing hierarchical features under low-light vision.
PE-YOLO: Pyramid Enhancement Network for Dark Object Detection
Jul 20, 2023Current object detection models have achieved good results on many benchmark datasets, detecting objects in dark conditions remains a large challenge. To address this issue, we propose a pyramid enhanced network (PENet) and joint it with YOLOv3 to build a dark object detection framework named PE-YOLO. Firstly, PENet decomposes the image into four components of different resolutions using the Laplacian pyramid. Specifically we propose a detail processing module (DPM) to enhance the detail of images, which consists of context branch and edge branch. In addition, we propose a low-frequency enhancement filter (LEF) to capture low-frequency semantics and prevent high-frequency noise. PE-YOLO adopts an end-to-end joint training approach and only uses normal detection loss to simplify the training process. We conduct experiments on the low-light object detection dataset ExDark to demonstrate the effectiveness of ours. The results indicate that compared with other dark detectors and low-light enhancement models, PE-YOLO achieves the advanced results, achieving 78.0% in mAP and 53.6 in FPS, respectively, which can adapt to object detection under different low-light conditions. The code is available at https://github.com/XiangchenYin/PE-YOLO.
Enhancing object detection robustness: A synthetic and natural perturbation approach
Apr 20, 2023



Robustness against real-world distribution shifts is crucial for the successful deployment of object detection models in practical applications. In this paper, we address the problem of assessing and enhancing the robustness of object detection models against natural perturbations, such as varying lighting conditions, blur, and brightness. We analyze four state-of-the-art deep neural network models, Detr-ResNet-101, Detr-ResNet-50, YOLOv4, and YOLOv4-tiny, using the COCO 2017 dataset and ExDark dataset. By simulating synthetic perturbations with the AugLy package, we systematically explore the optimal level of synthetic perturbation required to improve the models robustness through data augmentation techniques. Our comprehensive ablation study meticulously evaluates the impact of synthetic perturbations on object detection models performance against real-world distribution shifts, establishing a tangible connection between synthetic augmentation and real-world robustness. Our findings not only substantiate the effectiveness of synthetic perturbations in improving model robustness, but also provide valuable insights for researchers and practitioners in developing more robust and reliable object detection models tailored for real-world applications.
GDIP: Gated Differentiable Image Processing for Object-Detection in Adverse Conditions
Sep 29, 2022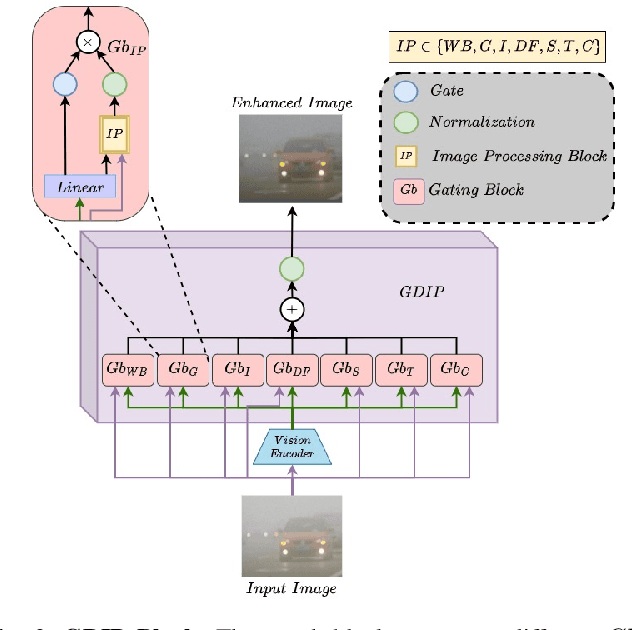
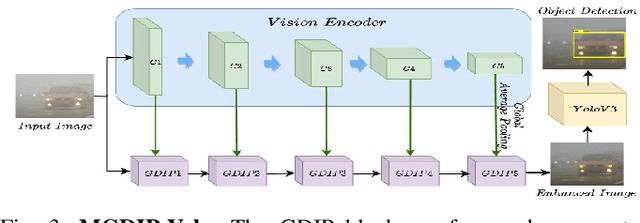
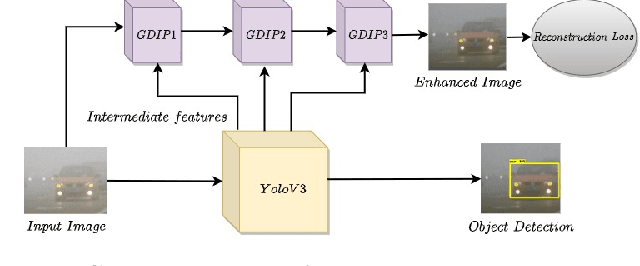
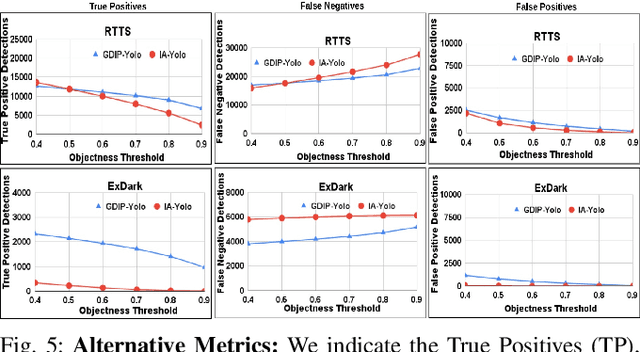
Detecting objects under adverse weather and lighting conditions is crucial for the safe and continuous operation of an autonomous vehicle, and remains an unsolved problem. We present a Gated Differentiable Image Processing (GDIP) block, a domain-agnostic network architecture, which can be plugged into existing object detection networks (e.g., Yolo) and trained end-to-end with adverse condition images such as those captured under fog and low lighting. Our proposed GDIP block learns to enhance images directly through the downstream object detection loss. This is achieved by learning parameters of multiple image pre-processing (IP) techniques that operate concurrently, with their outputs combined using weights learned through a novel gating mechanism. We further improve GDIP through a multi-stage guidance procedure for progressive image enhancement. Finally, trading off accuracy for speed, we propose a variant of GDIP that can be used as a regularizer for training Yolo, which eliminates the need for GDIP-based image enhancement during inference, resulting in higher throughput and plausible real-world deployment. We demonstrate significant improvement in detection performance over several state-of-the-art methods through quantitative and qualitative studies on synthetic datasets such as PascalVOC, and real-world foggy (RTTS) and low-lighting (ExDark) datasets.
KinD-LCE Curve Estimation And Retinex Fusion On Low-Light Image
Jul 19, 2022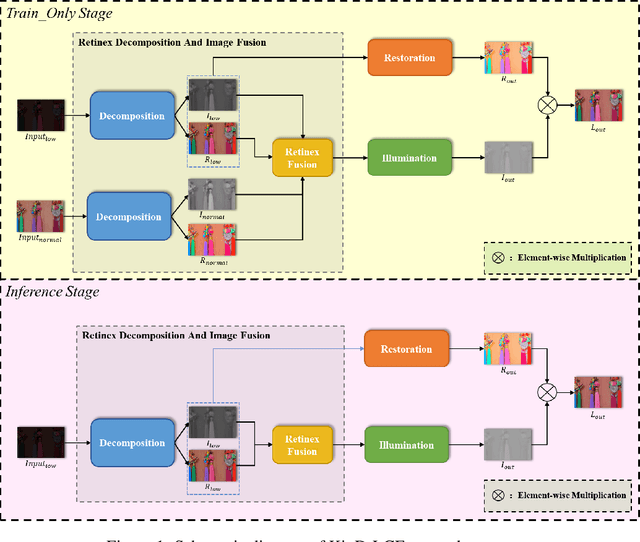

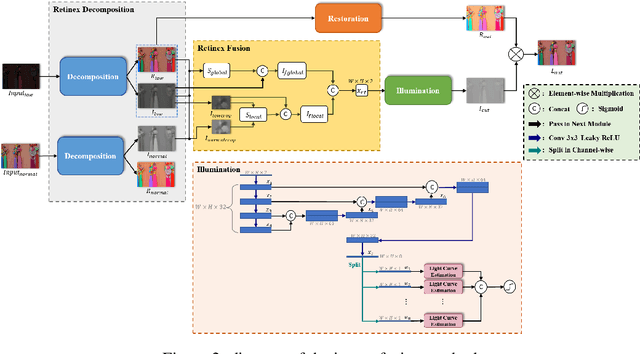

The problems of low light image noise and chromatic aberration is a challenging problem for tasks such as object detection, semantic segmentation, instance segmentation, etc. In this paper, we propose the algorithm for low illumination enhancement. KinD-LCE uses the light curve estimation module in the network structure to enhance the illumination map in the Retinex decomposed image, which improves the image brightness; we proposed the illumination map and reflection map fusion module to restore the restored image details and reduce the detail loss. Finally, we included a total variation loss function to eliminate noise. Our method uses the GladNet dataset as the training set, and the LOL dataset as the test set and is validated using ExDark as the dataset for downstream tasks. Extensive Experiments on the benchmarks demonstrate the advantages of our method and are close to the state-of-the-art results, which achieve a PSNR of 19.7216 and SSIM of 0.8213 in terms of metrics.