 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoonSeg3R: Monocular Online Zero-Shot Segment Anything in 3D with Reconstructive Foundation Priors
Dec 17, 2025In this paper, we focus on online zero-shot monocular 3D instance segmentation, a novel practical setting where existing approaches fail to perform because they rely on posed RGB-D sequences. To overcome this limitation, we leverage CUT3R, a recent Reconstructive Foundation Model (RFM), to provide reliable geometric priors from a single RGB stream. We propose MoonSeg3R, which introduces three key components: (1) a self-supervised query refinement module with spatial-semantic distillation that transforms segmentation masks from 2D visual foundation models (VFMs) into discriminative 3D queries; (2) a 3D query index memory that provides temporal consistency by retrieving contextual queries; and (3) a state-distribution token from CUT3R that acts as a mask identity descriptor to strengthen cross-frame fusion. Experiments on ScanNet200 and SceneNN show that MoonSeg3R is the first method to enable online monocular 3D segmentation and achieves performance competitive with state-of-the-art RGB-D-based systems. Code and models will be released.
Jamais Vu: Exposing the Generalization Gap in Supervised Semantic Correspondence
Jun 09, 2025Semantic correspondence (SC) aims to establish semantically meaningful matches across different instances of an object category. We illustrate how recent supervised SC methods remain limited in their ability to generalize beyond sparsely annotated training keypoints, effectively acting as keypoint detectors. To address this, we propose a novel approach for learning dense correspondences by lifting 2D keypoints into a canonical 3D space using monocular depth estimation. Our method constructs a continuous canonical manifold that captures object geometry without requiring explicit 3D supervision or camera annotations. Additionally, we introduce SPair-U, an extension of SPair-71k with novel keypoint annotations, to better assess generalization. Experiments not only demonstrate that our model significantly outperforms supervised baselines on unseen keypoints, highlighting its effectiveness in learning robust correspondences, but that unsupervised baselines outperform supervised counterparts when generalized across different datasets.
Boosting Object Detection with Zero-Shot Day-Night Domain Adaptation
Dec 02, 2023



Detecting objects in low-light scenarios presents a persistent challenge, as detectors trained on well-lit data exhibit significant performance degradation on low-light data due to the low visibility. Previous methods mitigate this issue by investigating image enhancement or object detection techniques using low-light image datasets. However, the progress is impeded by the inherent difficulties associated with collecting and annotating low-light images. To address this challenge, we propose to boost low-light object detection with zero-shot day-night domain adaptation, which aims to generalize a detector from well-lit scenarios to low-light ones without requiring real low-light data. We first design a reflectance representation learning module to learn Retinex-based illumination invariance in images with a carefully designed illumination invariance reinforcement strategy. Next, an interchange-redecomposition-coherence procedure is introduced to improve over the vanilla Retinex image decomposition process by performing two sequential image decompositions and introducing a redecomposition cohering loss. Extensive experiments on ExDark, DARK FACE and CODaN datasets show strong low-light generalizability of our method.
Domain-general Crowd Counting in Unseen Scenarios
Dec 05, 2022



Domain shift across crowd data severely hinders crowd counting models to generalize to unseen scenarios. Although domain adaptive crowd counting approaches close this gap to a certain extent, they are still dependent on the target domain data to adapt (e.g. finetune) their models to the specific domain. In this paper, we aim to train a model based on a single source domain which can generalize well on any unseen domain. This falls into the realm of domain generalization that remains unexplored in crowd counting. We first introduce a dynamic sub-domain division scheme which divides the source domain into multiple sub-domains such that we can initiate a meta-learning framework for domain generalization. The sub-domain division is dynamically refined during the meta-learning. Next, in order to disentangle domain-invariant information from domain-specific information in image features, we design the domain-invariant and -specific crowd memory modules to re-encode image features. Two types of losses, i.e. feature reconstruction and orthogonal losses, are devised to enable this disentanglement. Extensive experiments on several standard crowd counting benchmarks i.e. SHA, SHB, QNRF, and NWPU, show the strong generalizability of our method.
Redesigning Multi-Scale Neural Network for Crowd Counting
Aug 04, 2022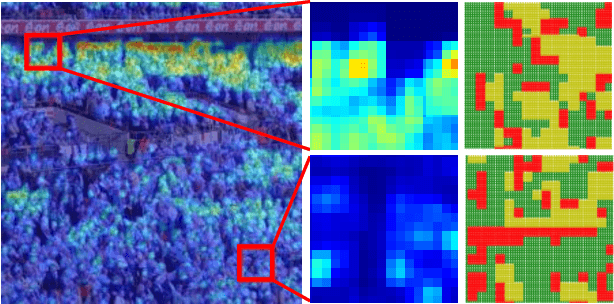
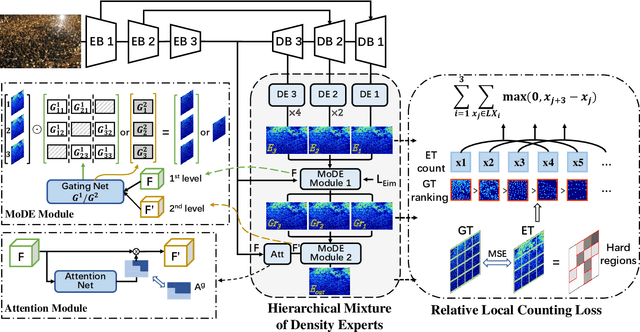
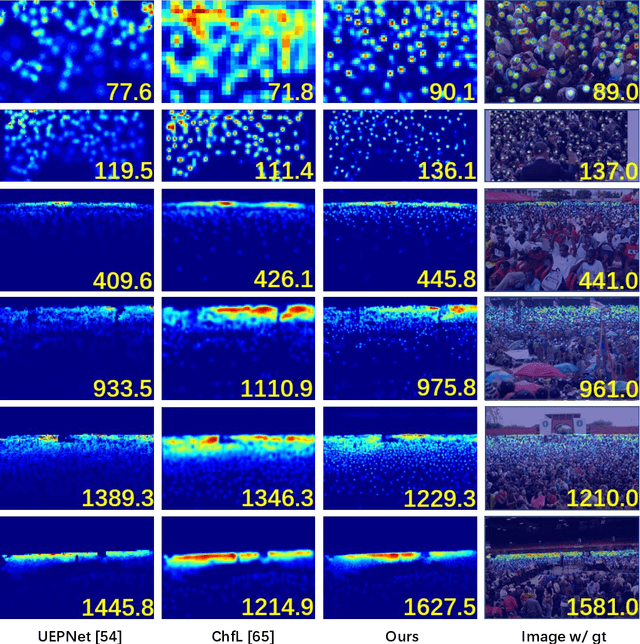
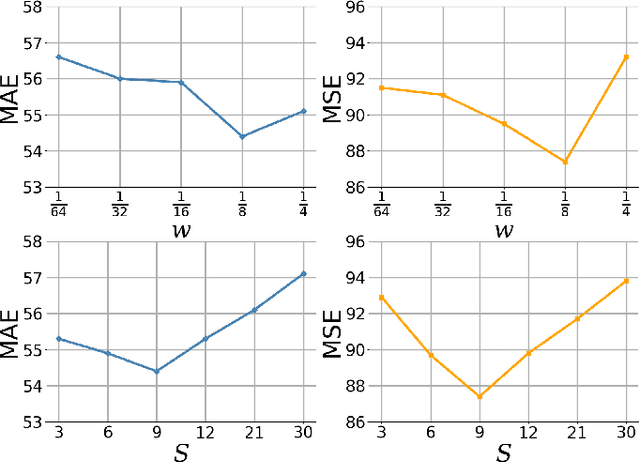
Perspective distortions and crowd variations make crowd counting a challenging task in computer vision. To tackle it, many previous works have used multi-scale architecture in deep neural networks (DNNs). Multi-scale branches can be either directly merged (e.g. by concatenation) or merged through the guidance of proxies (e.g. attentions) in the DNNs. Despite their prevalence, these combination methods are not sophisticated enough to deal with the per-pixel performance discrepancy over multi-scale density maps. In this work, we redesign the multi-scale neural network by introducing a hierarchical mixture of density experts, which hierarchically merges multi-scale density maps for crowd counting. Within the hierarchical structure, an expert competition and collaboration scheme is presented to encourage contributions from all scales; pixel-wise soft gating nets are introduced to provide pixel-wise soft weights for scale combinations in different hierarchies. The network is optimized using both the crowd density map and the local counting map, where the latter is obtained by local integration on the former. Optimizing both can be problematic because of their potential conflicts. We introduce a new relative local counting loss based on relative count differences among hard-predicted local regions in an image, which proves to be complementary to the conventional absolute error loss on the density map. Experiments show that our method achieves the state-of-the-art performance on five public datasets, i.e. ShanghaiTech, UCF_CC_50, JHU-CROWD++, NWPU-Crowd and Trancos.