 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConstrained 6-DoF Grasp Generation on Complex Shapes for Improved Dual-Arm Manipulation
Apr 06, 2024



Efficiently generating grasp poses tailored to specific regions of an object is vital for various robotic manipulation tasks, especially in a dual-arm setup. This scenario presents a significant challenge due to the complex geometries involved, requiring a deep understanding of the local geometry to generate grasps efficiently on the specified constrained regions. Existing methods only explore settings involving table-top/small objects and require augmented datasets to train, limiting their performance on complex objects. We propose CGDF: Constrained Grasp Diffusion Fields, a diffusion-based grasp generative model that generalizes to objects with arbitrary geometries, as well as generates dense grasps on the target regions. CGDF uses a part-guided diffusion approach that enables it to get high sample efficiency in constrained grasping without explicitly training on massive constraint-augmented datasets. We provide qualitative and quantitative comparisons using analytical metrics and in simulation, in both unconstrained and constrained settings to show that our method can generalize to generate stable grasps on complex objects, especially useful for dual-arm manipulation settings, while existing methods struggle to do so.
DiffPrompter: Differentiable Implicit Visual Prompts for Semantic-Segmentation in Adverse Conditions
Oct 06, 2023



Semantic segmentation in adverse weather scenarios is a critical task for autonomous driving systems. While foundation models have shown promise, the need for specialized adaptors becomes evident for handling more challenging scenarios. We introduce DiffPrompter, a novel differentiable visual and latent prompting mechanism aimed at expanding the learning capabilities of existing adaptors in foundation models. Our proposed $\nabla$HFC image processing block excels particularly in adverse weather conditions, where conventional methods often fall short. Furthermore, we investigate the advantages of jointly training visual and latent prompts, demonstrating that this combined approach significantly enhances performance in out-of-distribution scenarios. Our differentiable visual prompts leverage parallel and series architectures to generate prompts, effectively improving object segmentation tasks in adverse conditions. Through a comprehensive series of experiments and evaluations, we provide empirical evidence to support the efficacy of our approach. Project page at https://diffprompter.github.io.
GDIP: Gated Differentiable Image Processing for Object-Detection in Adverse Conditions
Sep 29, 2022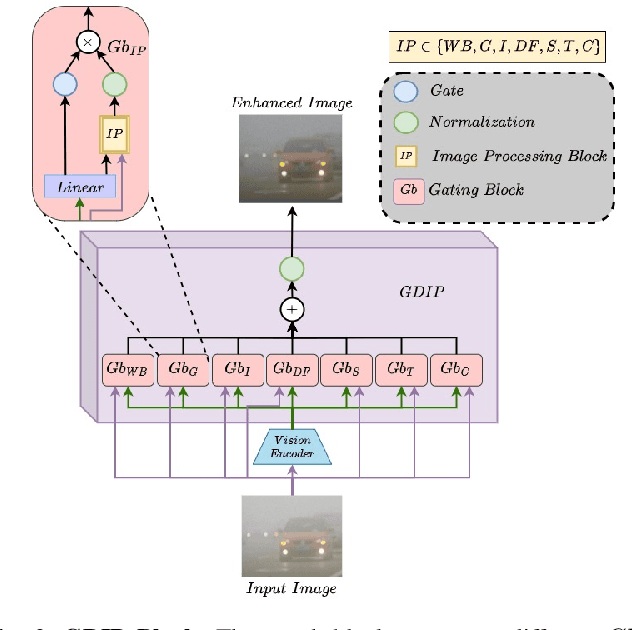
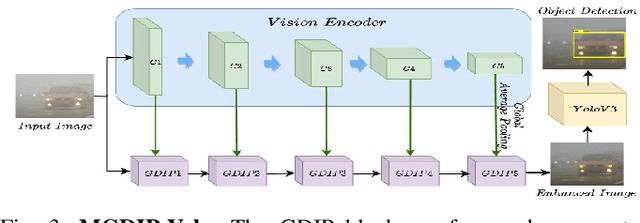
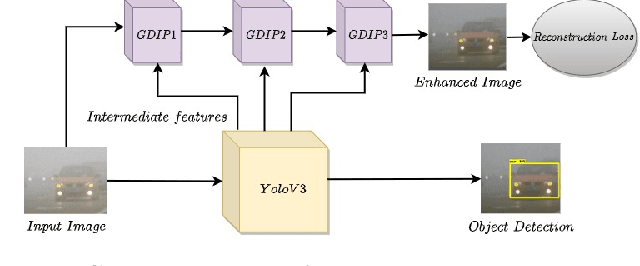
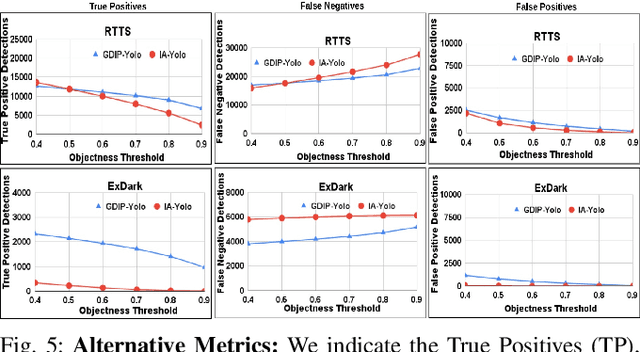
Detecting objects under adverse weather and lighting conditions is crucial for the safe and continuous operation of an autonomous vehicle, and remains an unsolved problem. We present a Gated Differentiable Image Processing (GDIP) block, a domain-agnostic network architecture, which can be plugged into existing object detection networks (e.g., Yolo) and trained end-to-end with adverse condition images such as those captured under fog and low lighting. Our proposed GDIP block learns to enhance images directly through the downstream object detection loss. This is achieved by learning parameters of multiple image pre-processing (IP) techniques that operate concurrently, with their outputs combined using weights learned through a novel gating mechanism. We further improve GDIP through a multi-stage guidance procedure for progressive image enhancement. Finally, trading off accuracy for speed, we propose a variant of GDIP that can be used as a regularizer for training Yolo, which eliminates the need for GDIP-based image enhancement during inference, resulting in higher throughput and plausible real-world deployment. We demonstrate significant improvement in detection performance over several state-of-the-art methods through quantitative and qualitative studies on synthetic datasets such as PascalVOC, and real-world foggy (RTTS) and low-lighting (ExDark) datasets.
LatentGAN Autoencoder: Learning Disentangled Latent Distribution
Apr 05, 2022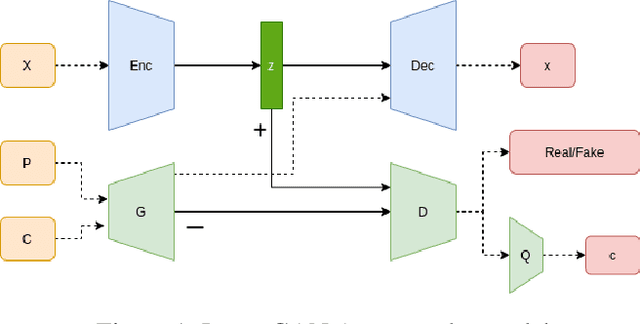
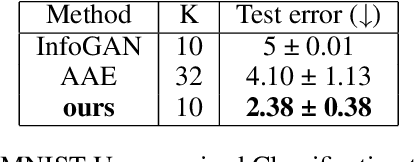


In autoencoder, the encoder generally approximates the latent distribution over the dataset, and the decoder generates samples using this learned latent distribution. There is very little control over the latent vector as using the random latent vector for generation will lead to trivial outputs. This work tries to address this issue by using the LatentGAN generator to directly learn to approximate the latent distribution of the autoencoder and show meaningful results on MNIST, 3D Chair, and CelebA datasets, an additional information-theoretic constrain is used which successfully learns to control autoencoder latent distribution. With this, our model also achieves an error rate of 2.38 on MNIST unsupervised image classification, which is better as compared to InfoGAN and AAE.