 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D Human Shape Estimation
Papers and Code
JRDB-Pose3D: A Multi-person 3D Human Pose and Shape Estimation Dataset for Robotics
Feb 03, 2026Real-world scenes are inherently crowded. Hence, estimating 3D poses of all nearby humans, tracking their movements over time, and understanding their activities within social and environmental contexts are essential for many applications, such as autonomous driving, robot perception, robot navigation, and human-robot interaction. However, most existing 3D human pose estimation datasets primarily focus on single-person scenes or are collected in controlled laboratory environments, which restricts their relevance to real-world applications. To bridge this gap, we introduce JRDB-Pose3D, which captures multi-human indoor and outdoor environments from a mobile robotic platform. JRDB-Pose3D provides rich 3D human pose annotations for such complex and dynamic scenes, including SMPL-based pose annotations with consistent body-shape parameters and track IDs for each individual over time. JRDB-Pose3D contains, on average, 5-10 human poses per frame, with some scenes featuring up to 35 individuals simultaneously. The proposed dataset presents unique challenges, including frequent occlusions, truncated bodies, and out-of-frame body parts, which closely reflect real-world environments. Moreover, JRDB-Pose3D inherits all available annotations from the JRDB dataset, such as 2D pose, information about social grouping, activities, and interactions, full-scene semantic masks with consistent human- and object-level tracking, and detailed annotations for each individual, such as age, gender, and race, making it a holistic dataset for a wide range of downstream perception and human-centric understanding tasks.
Deep Learning Based Facial Retargeting Using Local Patches
Jan 13, 2026In the era of digital animation, the quest to produce lifelike facial animations for virtual characters has led to the development of various retargeting methods. While the retargeting facial motion between models of similar shapes has been very successful, challenges arise when the retargeting is performed on stylized or exaggerated 3D characters that deviate significantly from human facial structures. In this scenario, it is important to consider the target character's facial structure and possible range of motion to preserve the semantics assumed by the original facial motions after the retargeting. To achieve this, we propose a local patch-based retargeting method that transfers facial animations captured in a source performance video to a target stylized 3D character. Our method consists of three modules. The Automatic Patch Extraction Module extracts local patches from the source video frame. These patches are processed through the Reenactment Module to generate correspondingly re-enacted target local patches. The Weight Estimation Module calculates the animation parameters for the target character at every frame for the creation of a complete facial animation sequence. Extensive experiments demonstrate that our method can successfully transfer the semantic meaning of source facial expressions to stylized characters with considerable variations in facial feature proportion.
* Eurographics 25
ClothHMR: 3D Mesh Recovery of Humans in Diverse Clothing from Single Image
Dec 19, 2025With 3D data rapidly emerging as an important form of multimedia information, 3D human mesh recovery technology has also advanced accordingly. However, current methods mainly focus on handling humans wearing tight clothing and perform poorly when estimating body shapes and poses under diverse clothing, especially loose garments. To this end, we make two key insights: (1) tailoring clothing to fit the human body can mitigate the adverse impact of clothing on 3D human mesh recovery, and (2) utilizing human visual information from large foundational models can enhance the generalization ability of the estimation. Based on these insights, we propose ClothHMR, to accurately recover 3D meshes of humans in diverse clothing. ClothHMR primarily consists of two modules: clothing tailoring (CT) and FHVM-based mesh recovering (MR). The CT module employs body semantic estimation and body edge prediction to tailor the clothing, ensuring it fits the body silhouette. The MR module optimizes the initial parameters of the 3D human mesh by continuously aligning the intermediate representations of the 3D mesh with those inferred from the foundational human visual model (FHVM). ClothHMR can accurately recover 3D meshes of humans wearing diverse clothing, precisely estimating their body shapes and poses. Experimental results demonstrate that ClothHMR significantly outperforms existing state-of-the-art methods across benchmark datasets and in-the-wild images. Additionally, a web application for online fashion and shopping powered by ClothHMR is developed, illustrating that ClothHMR can effectively serve real-world usage scenarios. The code and model for ClothHMR are available at: \url{https://github.com/starVisionTeam/ClothHMR}.
Spinal Line Detection for Posture Evaluation through Train-ing-free 3D Human Body Reconstruction with 2D Depth Images
Dec 14, 2025The spinal angle is an important indicator of body balance. It is important to restore the 3D shape of the human body and estimate the spine center line. Existing mul-ti-image-based body restoration methods require expensive equipment and complex pro-cedures, and single image-based body restoration methods have limitations in that it is difficult to accurately estimate the internal structure such as the spine center line due to occlusion and viewpoint limitation. This study proposes a method to compensate for the shortcomings of the multi-image-based method and to solve the limitations of the sin-gle-image method. We propose a 3D body posture analysis system that integrates depth images from four directions to restore a 3D human model and automatically estimate the spine center line. Through hierarchical matching of global and fine registration, restora-tion to noise and occlusion is performed. Also, the Adaptive Vertex Reduction is applied to maintain the resolution and shape reliability of the mesh, and the accuracy and stabil-ity of spinal angle estimation are simultaneously secured by using the Level of Detail en-semble. The proposed method achieves high-precision 3D spine registration estimation without relying on training data or complex neural network models, and the verification confirms the improvement of matching quality.
Hand-Aware Egocentric Motion Reconstruction with Sequence-Level Context
Dec 22, 2025Egocentric vision systems are becoming widely available, creating new opportunities for human-computer interaction. A core challenge is estimating the wearer's full-body motion from first-person videos, which is crucial for understanding human behavior. However, this task is difficult since most body parts are invisible from the egocentric view. Prior approaches mainly rely on head trajectories, leading to ambiguity, or assume continuously tracked hands, which is unrealistic for lightweight egocentric devices. In this work, we present HaMoS, the first hand-aware, sequence-level diffusion framework that directly conditions on both head trajectory and intermittently visible hand cues caused by field-of-view limitations and occlusions, as in real-world egocentric devices. To overcome the lack of datasets pairing diverse camera views with human motion, we introduce a novel augmentation method that models such real-world conditions. We also demonstrate that sequence-level contexts such as body shape and field-of-view are crucial for accurate motion reconstruction, and thus employ local attention to infer long sequences efficiently. Experiments on public benchmarks show that our method achieves state-of-the-art accuracy and temporal smoothness, demonstrating a practical step toward reliable in-the-wild egocentric 3D motion understanding.
BEDLAM2.0: Synthetic Humans and Cameras in Motion
Nov 18, 2025Inferring 3D human motion from video remains a challenging problem with many applications. While traditional methods estimate the human in image coordinates, many applications require human motion to be estimated in world coordinates. This is particularly challenging when there is both human and camera motion. Progress on this topic has been limited by the lack of rich video data with ground truth human and camera movement. We address this with BEDLAM2.0, a new dataset that goes beyond the popular BEDLAM dataset in important ways. In addition to introducing more diverse and realistic cameras and camera motions, BEDLAM2.0 increases diversity and realism of body shape, motions, clothing, hair, and 3D environments. Additionally, it adds shoes, which were missing in BEDLAM. BEDLAM has become a key resource for training 3D human pose and motion regressors today and we show that BEDLAM2.0 is significantly better, particularly for training methods that estimate humans in world coordinates. We compare state-of-the art methods trained on BEDLAM and BEDLAM2.0, and find that BEDLAM2.0 significantly improves accuracy over BEDLAM. For research purposes, we provide the rendered videos, ground truth body parameters, and camera motions. We also provide the 3D assets to which we have rights and links to those from third parties.
Sketch2PoseNet: Efficient and Generalized Sketch to 3D Human Pose Prediction
Oct 30, 20253D human pose estimation from sketches has broad applications in computer animation and film production. Unlike traditional human pose estimation, this task presents unique challenges due to the abstract and disproportionate nature of sketches. Previous sketch-to-pose methods, constrained by the lack of large-scale sketch-3D pose annotations, primarily relied on optimization with heuristic rules-an approach that is both time-consuming and limited in generalizability. To address these challenges, we propose a novel approach leveraging a "learn from synthesis" strategy. First, a diffusion model is trained to synthesize sketch images from 2D poses projected from 3D human poses, mimicking disproportionate human structures in sketches. This process enables the creation of a synthetic dataset, SKEP-120K, consisting of 120k accurate sketch-3D pose annotation pairs across various sketch styles. Building on this synthetic dataset, we introduce an end-to-end data-driven framework for estimating human poses and shapes from diverse sketch styles. Our framework combines existing 2D pose detectors and generative diffusion priors for sketch feature extraction with a feed-forward neural network for efficient 2D pose estimation. Multiple heuristic loss functions are incorporated to guarantee geometric coherence between the derived 3D poses and the detected 2D poses while preserving accurate self-contacts. Qualitative, quantitative, and subjective evaluations collectively show that our model substantially surpasses previous ones in both estimation accuracy and speed for sketch-to-pose tasks.
MMHOI: Modeling Complex 3D Multi-Human Multi-Object Interactions
Oct 09, 2025



Real-world scenes often feature multiple humans interacting with multiple objects in ways that are causal, goal-oriented, or cooperative. Yet existing 3D human-object interaction (HOI) benchmarks consider only a fraction of these complex interactions. To close this gap, we present MMHOI -- a large-scale, Multi-human Multi-object Interaction dataset consisting of images from 12 everyday scenarios. MMHOI offers complete 3D shape and pose annotations for every person and object, along with labels for 78 action categories and 14 interaction-specific body parts, providing a comprehensive testbed for next-generation HOI research. Building on MMHOI, we present MMHOI-Net, an end-to-end transformer-based neural network for jointly estimating human-object 3D geometries, their interactions, and associated actions. A key innovation in our framework is a structured dual-patch representation for modeling objects and their interactions, combined with action recognition to enhance the interaction prediction. Experiments on MMHOI and the recently proposed CORE4D datasets demonstrate that our approach achieves state-of-the-art performance in multi-HOI modeling, excelling in both accuracy and reconstruction quality.
SyncHuman: Synchronizing 2D and 3D Generative Models for Single-view Human Reconstruction
Oct 09, 2025Photorealistic 3D full-body human reconstruction from a single image is a critical yet challenging task for applications in films and video games due to inherent ambiguities and severe self-occlusions. While recent approaches leverage SMPL estimation and SMPL-conditioned image generative models to hallucinate novel views, they suffer from inaccurate 3D priors estimated from SMPL meshes and have difficulty in handling difficult human poses and reconstructing fine details. In this paper, we propose SyncHuman, a novel framework that combines 2D multiview generative model and 3D native generative model for the first time, enabling high-quality clothed human mesh reconstruction from single-view images even under challenging human poses. Multiview generative model excels at capturing fine 2D details but struggles with structural consistency, whereas 3D native generative model generates coarse yet structurally consistent 3D shapes. By integrating the complementary strengths of these two approaches, we develop a more effective generation framework. Specifically, we first jointly fine-tune the multiview generative model and the 3D native generative model with proposed pixel-aligned 2D-3D synchronization attention to produce geometrically aligned 3D shapes and 2D multiview images. To further improve details, we introduce a feature injection mechanism that lifts fine details from 2D multiview images onto the aligned 3D shapes, enabling accurate and high-fidelity reconstruction. Extensive experiments demonstrate that SyncHuman achieves robust and photo-realistic 3D human reconstruction, even for images with challenging poses. Our method outperforms baseline methods in geometric accuracy and visual fidelity, demonstrating a promising direction for future 3D generation models.
Affordance-Guided Diffusion Prior for 3D Hand Reconstruction
Oct 01, 2025

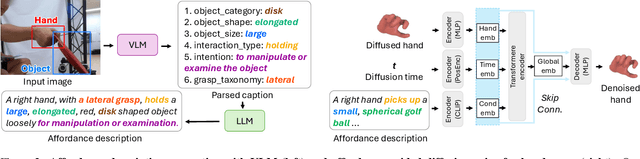

How can we reconstruct 3D hand poses when large portions of the hand are heavily occluded by itself or by objects? Humans often resolve such ambiguities by leveraging contextual knowledge -- such as affordances, where an object's shape and function suggest how the object is typically grasped. Inspired by this observation, we propose a generative prior for hand pose refinement guided by affordance-aware textual descriptions of hand-object interactions (HOI). Our method employs a diffusion-based generative model that learns the distribution of plausible hand poses conditioned on affordance descriptions, which are inferred from a large vision-language model (VLM). This enables the refinement of occluded regions into more accurate and functionally coherent hand poses. Extensive experiments on HOGraspNet, a 3D hand-affordance dataset with severe occlusions, demonstrate that our affordance-guided refinement significantly improves hand pose estimation over both recent regression methods and diffusion-based refinement lacking contextual reasoning.