 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBEDLAM2.0: Synthetic Humans and Cameras in Motion
Nov 18, 2025Inferring 3D human motion from video remains a challenging problem with many applications. While traditional methods estimate the human in image coordinates, many applications require human motion to be estimated in world coordinates. This is particularly challenging when there is both human and camera motion. Progress on this topic has been limited by the lack of rich video data with ground truth human and camera movement. We address this with BEDLAM2.0, a new dataset that goes beyond the popular BEDLAM dataset in important ways. In addition to introducing more diverse and realistic cameras and camera motions, BEDLAM2.0 increases diversity and realism of body shape, motions, clothing, hair, and 3D environments. Additionally, it adds shoes, which were missing in BEDLAM. BEDLAM has become a key resource for training 3D human pose and motion regressors today and we show that BEDLAM2.0 is significantly better, particularly for training methods that estimate humans in world coordinates. We compare state-of-the art methods trained on BEDLAM and BEDLAM2.0, and find that BEDLAM2.0 significantly improves accuracy over BEDLAM. For research purposes, we provide the rendered videos, ground truth body parameters, and camera motions. We also provide the 3D assets to which we have rights and links to those from third parties.
PromptHMR: Promptable Human Mesh Recovery
Apr 08, 2025



Human pose and shape (HPS) estimation presents challenges in diverse scenarios such as crowded scenes, person-person interactions, and single-view reconstruction. Existing approaches lack mechanisms to incorporate auxiliary "side information" that could enhance reconstruction accuracy in such challenging scenarios. Furthermore, the most accurate methods rely on cropped person detections and cannot exploit scene context while methods that process the whole image often fail to detect people and are less accurate than methods that use crops. While recent language-based methods explore HPS reasoning through large language or vision-language models, their metric accuracy is well below the state of the art. In contrast, we present PromptHMR, a transformer-based promptable method that reformulates HPS estimation through spatial and semantic prompts. Our method processes full images to maintain scene context and accepts multiple input modalities: spatial prompts like bounding boxes and masks, and semantic prompts like language descriptions or interaction labels. PromptHMR demonstrates robust performance across challenging scenarios: estimating people from bounding boxes as small as faces in crowded scenes, improving body shape estimation through language descriptions, modeling person-person interactions, and producing temporally coherent motions in videos. Experiments on benchmarks show that PromptHMR achieves state-of-the-art performance while offering flexible prompt-based control over the HPS estimation process.
Toward Human Understanding with Controllable Synthesis
Nov 13, 2024



Training methods to perform robust 3D human pose and shape (HPS) estimation requires diverse training images with accurate ground truth. While BEDLAM demonstrates the potential of traditional procedural graphics to generate such data, the training images are clearly synthetic. In contrast, generative image models produce highly realistic images but without ground truth. Putting these methods together seems straightforward: use a generative model with the body ground truth as controlling signal. However, we find that, the more realistic the generated images, the more they deviate from the ground truth, making them inappropriate for training and evaluation. Enhancements of realistic details, such as clothing and facial expressions, can lead to subtle yet significant deviations from the ground truth, potentially misleading training models. We empirically verify that this misalignment causes the accuracy of HPS networks to decline when trained with generated images. To address this, we design a controllable synthesis method that effectively balances image realism with precise ground truth. We use this to create the Generative BEDLAM (Gen-B) dataset, which improves the realism of the existing synthetic BEDLAM dataset while preserving ground truth accuracy. We perform extensive experiments, with various noise-conditioning strategies, to evaluate the tradeoff between visual realism and HPS accuracy. We show, for the first time, that generative image models can be controlled by traditional graphics methods to produce training data that increases the accuracy of HPS methods.
CameraHMR: Aligning People with Perspective
Nov 12, 2024



We address the challenge of accurate 3D human pose and shape estimation from monocular images. The key to accuracy and robustness lies in high-quality training data. Existing training datasets containing real images with pseudo ground truth (pGT) use SMPLify to fit SMPL to sparse 2D joint locations, assuming a simplified camera with default intrinsics. We make two contributions that improve pGT accuracy. First, to estimate camera intrinsics, we develop a field-of-view prediction model (HumanFoV) trained on a dataset of images containing people. We use the estimated intrinsics to enhance the 4D-Humans dataset by incorporating a full perspective camera model during SMPLify fitting. Second, 2D joints provide limited constraints on 3D body shape, resulting in average-looking bodies. To address this, we use the BEDLAM dataset to train a dense surface keypoint detector. We apply this detector to the 4D-Humans dataset and modify SMPLify to fit the detected keypoints, resulting in significantly more realistic body shapes. Finally, we upgrade the HMR2.0 architecture to include the estimated camera parameters. We iterate model training and SMPLify fitting initialized with the previously trained model. This leads to more accurate pGT and a new model, CameraHMR, with state-of-the-art accuracy. Code and pGT are available for research purposes.
TokenHMR: Advancing Human Mesh Recovery with a Tokenized Pose Representation
Apr 25, 2024We address the problem of regressing 3D human pose and shape from a single image, with a focus on 3D accuracy. The current best methods leverage large datasets of 3D pseudo-ground-truth (p-GT) and 2D keypoints, leading to robust performance. With such methods, we observe a paradoxical decline in 3D pose accuracy with increasing 2D accuracy. This is caused by biases in the p-GT and the use of an approximate camera projection model. We quantify the error induced by current camera models and show that fitting 2D keypoints and p-GT accurately causes incorrect 3D poses. Our analysis defines the invalid distances within which minimizing 2D and p-GT losses is detrimental. We use this to formulate a new loss Threshold-Adaptive Loss Scaling (TALS) that penalizes gross 2D and p-GT losses but not smaller ones. With such a loss, there are many 3D poses that could equally explain the 2D evidence. To reduce this ambiguity we need a prior over valid human poses but such priors can introduce unwanted bias. To address this, we exploit a tokenized representation of human pose and reformulate the problem as token prediction. This restricts the estimated poses to the space of valid poses, effectively providing a uniform prior. Extensive experiments on the EMDB and 3DPW datasets show that our reformulated keypoint loss and tokenization allows us to train on in-the-wild data while improving 3D accuracy over the state-of-the-art. Our models and code are available for research at https://tokenhmr.is.tue.mpg.de.
PoseGPT: Chatting about 3D Human Pose
Nov 30, 2023



We introduce PoseGPT, a framework employing Large Language Models (LLMs) to understand and reason about 3D human poses from images or textual descriptions. Our work is motivated by the human ability to intuitively understand postures from a single image or a brief description, a process that intertwines image interpretation, world knowledge, and an understanding of body language. Traditional human pose estimation methods, whether image-based or text-based, often lack holistic scene comprehension and nuanced reasoning, leading to a disconnect between visual data and its real-world implications. PoseGPT addresses these limitations by embedding SMPL poses as a distinct signal token within a multi-modal LLM, enabling direct generation of 3D body poses from both textual and visual inputs. This approach not only simplifies pose prediction but also empowers LLMs to apply their world knowledge in reasoning about human poses, fostering two advanced tasks: speculative pose generation and reasoning about pose estimation. These tasks involve reasoning about humans to generate 3D poses from subtle text queries, possibly accompanied by images. We establish benchmarks for these tasks, moving beyond traditional 3D pose generation and estimation methods. Our results show that PoseGPT outperforms existing multimodal LLMs and task-sepcific methods on these newly proposed tasks. Furthermore, PoseGPT's ability to understand and generate 3D human poses based on complex reasoning opens new directions in human pose analysis.
BEDLAM: A Synthetic Dataset of Bodies Exhibiting Detailed Lifelike Animated Motion
Jun 29, 2023



We show, for the first time, that neural networks trained only on synthetic data achieve state-of-the-art accuracy on the problem of 3D human pose and shape (HPS) estimation from real images. Previous synthetic datasets have been small, unrealistic, or lacked realistic clothing. Achieving sufficient realism is non-trivial and we show how to do this for full bodies in motion. Specifically, our BEDLAM dataset contains monocular RGB videos with ground-truth 3D bodies in SMPL-X format. It includes a diversity of body shapes, motions, skin tones, hair, and clothing. The clothing is realistically simulated on the moving bodies using commercial clothing physics simulation. We render varying numbers of people in realistic scenes with varied lighting and camera motions. We then train various HPS regressors using BEDLAM and achieve state-of-the-art accuracy on real-image benchmarks despite training with synthetic data. We use BEDLAM to gain insights into what model design choices are important for accuracy. With good synthetic training data, we find that a basic method like HMR approaches the accuracy of the current SOTA method (CLIFF). BEDLAM is useful for a variety of tasks and all images, ground truth bodies, 3D clothing, support code, and more are available for research purposes. Additionally, we provide detailed information about our synthetic data generation pipeline, enabling others to generate their own datasets. See the project page: https://bedlam.is.tue.mpg.de/.
AGORA: Avatars in Geography Optimized for Regression Analysis
Apr 29, 2021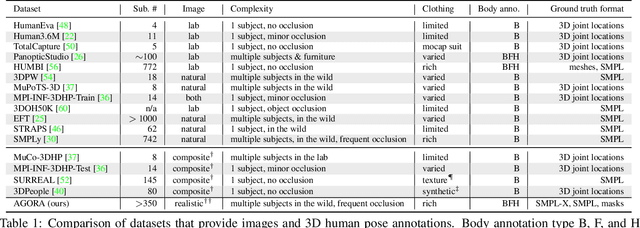
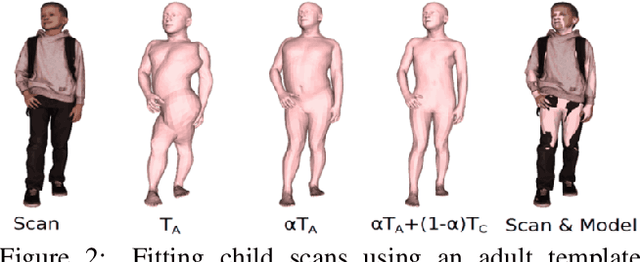
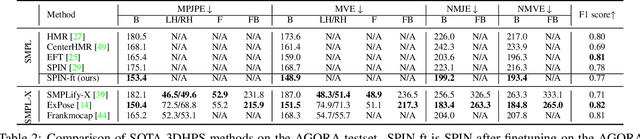
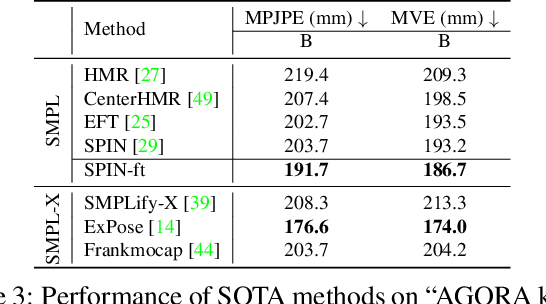
While the accuracy of 3D human pose estimation from images has steadily improved on benchmark datasets, the best methods still fail in many real-world scenarios. This suggests that there is a domain gap between current datasets and common scenes containing people. To obtain ground-truth 3D pose, current datasets limit the complexity of clothing, environmental conditions, number of subjects, and occlusion. Moreover, current datasets evaluate sparse 3D joint locations corresponding to the major joints of the body, ignoring the hand pose and the face shape. To evaluate the current state-of-the-art methods on more challenging images, and to drive the field to address new problems, we introduce AGORA, a synthetic dataset with high realism and highly accurate ground truth. Here we use 4240 commercially-available, high-quality, textured human scans in diverse poses and natural clothing; this includes 257 scans of children. We create reference 3D poses and body shapes by fitting the SMPL-X body model (with face and hands) to the 3D scans, taking into account clothing. We create around 14K training and 3K test images by rendering between 5 and 15 people per image using either image-based lighting or rendered 3D environments, taking care to make the images physically plausible and photoreal. In total, AGORA consists of 173K individual person crops. We evaluate existing state-of-the-art methods for 3D human pose estimation on this dataset and find that most methods perform poorly on images of children. Hence, we extend the SMPL-X model to better capture the shape of children. Additionally, we fine-tune methods on AGORA and show improved performance on both AGORA and 3DPW, confirming the realism of the dataset. We provide all the registered 3D reference training data, rendered images, and a web-based evaluation site at https://agora.is.tue.mpg.de/.