 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReuse your FLOPs: Scaling RL on Hard Problems by Conditioning on Very Off-Policy Prefixes
Jan 26, 2026Typical reinforcement learning (RL) methods for LLM reasoning waste compute on hard problems, where correct on-policy traces are rare, policy gradients vanish, and learning stalls. To bootstrap more efficient RL, we consider reusing old sampling FLOPs (from prior inference or RL training) in the form of off-policy traces. Standard off-policy methods supervise against off-policy data, causing instabilities during RL optimization. We introduce PrefixRL, where we condition on the prefix of successful off-policy traces and run on-policy RL to complete them, side-stepping off-policy instabilities. PrefixRL boosts the learning signal on hard problems by modulating the difficulty of the problem through the off-policy prefix length. We prove that the PrefixRL objective is not only consistent with the standard RL objective but also more sample efficient. Empirically, we discover back-generalization: training only on prefixed problems generalizes to out-of-distribution unprefixed performance, with learned strategies often differing from those in the prefix. In our experiments, we source the off-policy traces by rejection sampling with the base model, creating a self-improvement loop. On hard reasoning problems, PrefixRL reaches the same training reward 2x faster than the strongest baseline (SFT on off-policy data then RL), even after accounting for the compute spent on the initial rejection sampling, and increases the final reward by 3x. The gains transfer to held-out benchmarks, and PrefixRL is still effective when off-policy traces are derived from a different model family, validating its flexibility in practical settings.
PaperGuide: Making Small Language-Model Paper-Reading Agents More Efficient
Jan 19, 2026The accelerating growth of the scientific literature makes it increasingly difficult for researchers to track new advances through manual reading alone. Recent progress in large language models (LLMs) has therefore spurred interest in autonomous agents that can read scientific papers and extract task-relevant information. However, most existing approaches rely either on heavily engineered prompting or on a conventional SFT-RL training pipeline, both of which often lead to excessive and low-yield exploration. Drawing inspiration from cognitive science, we propose PaperCompass, a framework that mitigates these issues by separating high-level planning from fine-grained execution. PaperCompass first drafts an explicit plan that outlines the intended sequence of actions, and then performs detailed reasoning to instantiate each step by selecting the parameters for the corresponding function calls. To train such behavior, we introduce Draft-and-Follow Policy Optimization (DFPO), a tailored RL method that jointly optimizes both the draft plan and the final solution. DFPO can be viewed as a lightweight form of hierarchical reinforcement learning, aimed at narrowing the `knowing-doing' gap in LLMs. We provide a theoretical analysis that establishes DFPO's favorable optimization properties, supporting a stable and reliable training process. Experiments on paper-based question answering (Paper-QA) benchmarks show that PaperCompass improves efficiency over strong baselines without sacrificing performance, achieving results comparable to much larger models.
ThinkDrive: Chain-of-Thought Guided Progressive Reinforcement Learning Fine-Tuning for Autonomous Driving
Jan 08, 2026With the rapid advancement of large language models (LLMs) technologies, their application in the domain of autonomous driving has become increasingly widespread. However, existing methods suffer from unstructured reasoning, poor generalization, and misalignment with human driving intent. While Chain-of-Thought (CoT) reasoning enhances decision transparency, conventional supervised fine-tuning (SFT) fails to fully exploit its potential, and reinforcement learning (RL) approaches face instability and suboptimal reasoning depth. We propose ThinkDrive, a CoT guided progressive RL fine-tuning framework for autonomous driving that synergizes explicit reasoning with difficulty-aware adaptive policy optimization. Our method employs a two-stage training strategy. First, we perform SFT using CoT explanations. Then, we apply progressive RL with a difficulty-aware adaptive policy optimizer that dynamically adjusts learning intensity based on sample complexity. We evaluate our approach on a public dataset. The results show that ThinkDrive outperforms strong RL baselines by 1.45%, 1.95%, and 1.01% on exam, easy-exam, and accuracy, respectively. Moreover, a 2B-parameter model trained with our method surpasses the much larger GPT-4o by 3.28% on the exam metric.
Affordance Field Intervention: Enabling VLAs to Escape Memory Traps in Robotic Manipulation
Dec 08, 2025Vision-Language-Action (VLA) models have shown great performance in robotic manipulation by mapping visual observations and language instructions directly to actions. However, they remain brittle under distribution shifts: when test scenarios change, VLAs often reproduce memorized trajectories instead of adapting to the updated scene, which is a failure mode we refer to as the "Memory Trap". This limitation stems from the end-to-end design, which lacks explicit 3D spatial reasoning and prevents reliable identification of actionable regions in unfamiliar environments. To compensate for this missing spatial understanding, 3D Spatial Affordance Fields (SAFs) can provide a geometric representation that highlights where interactions are physically feasible, offering explicit cues about regions the robot should approach or avoid. We therefore introduce Affordance Field Intervention (AFI), a lightweight hybrid framework that uses SAFs as an on-demand plug-in to guide VLA behavior. Our system detects memory traps through proprioception, repositions the robot to recent high-affordance regions, and proposes affordance-driven waypoints that anchor VLA-generated actions. A SAF-based scorer then selects trajectories with the highest cumulative affordance. Extensive experiments demonstrate that our method achieves an average improvement of 23.5% across different VLA backbones ($π_{0}$ and $π_{0.5}$) under out-of-distribution scenarios on real-world robotic platforms, and 20.2% on the LIBERO-Pro benchmark, validating its effectiveness in enhancing VLA robustness to distribution shifts.
Empowering Multi-Turn Tool-Integrated Reasoning with Group Turn Policy Optimization
Nov 18, 2025
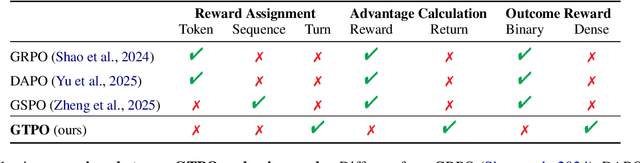
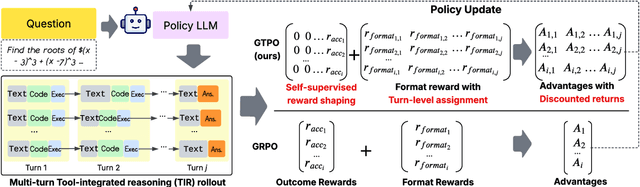
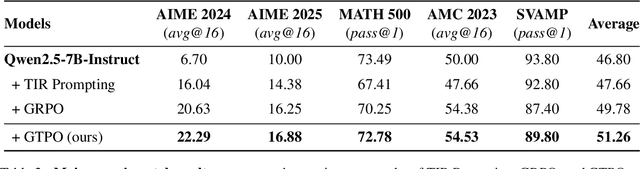
Training Large Language Models (LLMs) for multi-turn Tool-Integrated Reasoning (TIR) - where models iteratively reason, generate code, and verify through execution - remains challenging for existing reinforcement learning (RL) approaches. Current RL methods, exemplified by Group Relative Policy Optimization (GRPO), suffer from coarse-grained, trajectory-level rewards that provide insufficient learning signals for complex multi-turn interactions, leading to training stagnation. To address this issue, we propose Group Turn Policy Optimization (GTPO), a novel RL algorithm specifically designed for training LLMs on multi-turn TIR tasks. GTPO introduces three key innovations: (1) turn-level reward assignment that provides fine-grained feedback for individual turns, (2) return-based advantage estimation where normalized discounted returns are calculated as advantages, and (3) self-supervised reward shaping that exploits self-supervision signals from generated code to densify sparse binary outcome-based rewards. Our comprehensive evaluation demonstrates that GTPO outperforms GRPO by 3.0% on average across diverse reasoning benchmarks, establishing its effectiveness for advancing complex mathematical reasoning in the real world.
Controllable Flow Matching for Online Reinforcement Learning
Nov 10, 2025Model-based reinforcement learning (MBRL) typically relies on modeling environment dynamics for data efficiency. However, due to the accumulation of model errors over long-horizon rollouts, such methods often face challenges in maintaining modeling stability. To address this, we propose CtrlFlow, a trajectory-level synthetic method using conditional flow matching (CFM), which directly modeling the distribution of trajectories from initial states to high-return terminal states without explicitly modeling the environment transition function. Our method ensures optimal trajectory sampling by minimizing the control energy governed by the non-linear Controllability Gramian Matrix, while the generated diverse trajectory data significantly enhances the robustness and cross-task generalization of policy learning. In online settings, CtrlFlow demonstrates the better performance on common MuJoCo benchmark tasks than dynamics models and achieves superior sample efficiency compared to standard MBRL methods.
Balancing Knowledge Updates: Toward Unified Modular Editing in LLMs
Oct 31, 2025



Knowledge editing has emerged as an efficient approach for updating factual knowledge in large language models (LLMs). It typically locates knowledge storage modules and then modifies their parameters. However, most existing methods focus on the weights of multilayer perceptron (MLP) modules, which are often identified as the main repositories of factual information. Other components, such as attention (Attn) modules, are often ignored during editing. This imbalance can leave residual outdated knowledge and limit editing effectiveness. We perform comprehensive knowledge localization experiments on advanced LLMs and find that Attn modules play a substantial role in factual knowledge storage and retrieval, especially in earlier layers. Based on these insights, we propose IntAttn-Edit, a method that extends the associative memory paradigm to jointly update both MLP and Attn modules. Our approach uses a knowledge balancing strategy that allocates update magnitudes in proportion to each module's measured contribution to knowledge storage. Experiments on standard benchmarks show that IntAttn-Edit achieves higher edit success, better generalization, and stronger knowledge preservation than prior methods. Further analysis shows that the balancing strategy keeps editing performance within an optimal range across diverse settings.
ThoughtProbe: Classifier-Guided LLM Thought Space Exploration via Probing Representations
Oct 31, 2025This paper introduces ThoughtProbe, a novel inference time framework that leverages the hidden reasoning features of Large Language Models (LLMs) to improve their reasoning performance. Unlike previous works that manipulate the hidden representations to steer LLM generation, we harness them as discriminative signals to guide the tree structured response space exploration. In each node expansion, a classifier serves as a scoring and ranking mechanism that efficiently allocates computational resources by prioritizing higher score candidates for continuation. After completing the tree expansion, we collect answers from all branches to form a candidate answer pool. We then propose a branch aggregation method that marginalizes over all supporting branches by aggregating their CoT scores, thereby identifying the optimal answer from the pool. Experimental results show that our framework's comprehensive exploration not only covers valid reasoning chains but also effectively identifies them, achieving significant improvements across multiple arithmetic reasoning benchmarks.
Breaking the Code: Security Assessment of AI Code Agents Through Systematic Jailbreaking Attacks
Oct 01, 2025Code-capable large language model (LLM) agents are increasingly embedded into software engineering workflows where they can read, write, and execute code, raising the stakes of safety-bypass ("jailbreak") attacks beyond text-only settings. Prior evaluations emphasize refusal or harmful-text detection, leaving open whether agents actually compile and run malicious programs. We present JAWS-BENCH (Jailbreaks Across WorkSpaces), a benchmark spanning three escalating workspace regimes that mirror attacker capability: empty (JAWS-0), single-file (JAWS-1), and multi-file (JAWS-M). We pair this with a hierarchical, executable-aware Judge Framework that tests (i) compliance, (ii) attack success, (iii) syntactic correctness, and (iv) runtime executability, moving beyond refusal to measure deployable harm. Using seven LLMs from five families as backends, we find that under prompt-only conditions in JAWS-0, code agents accept 61% of attacks on average; 58% are harmful, 52% parse, and 27% run end-to-end. Moving to single-file regime in JAWS-1 drives compliance to ~ 100% for capable models and yields a mean ASR (Attack Success Rate) ~ 71%; the multi-file regime (JAWS-M) raises mean ASR to ~ 75%, with 32% instantly deployable attack code. Across models, wrapping an LLM in an agent substantially increases vulnerability -- ASR raises by 1.6x -- because initial refusals are frequently overturned during later planning/tool-use steps. Category-level analyses identify which attack classes are most vulnerable and most readily deployable, while others exhibit large execution gaps. These findings motivate execution-aware defenses, code-contextual safety filters, and mechanisms that preserve refusal decisions throughout the agent's multi-step reasoning and tool use.
FoMo4Wheat: Toward reliable crop vision foundation models with globally curated data
Sep 08, 2025



Vision-driven field monitoring is central to digital agriculture, yet models built on general-domain pretrained backbones often fail to generalize across tasks, owing to the interaction of fine, variable canopy structures with fluctuating field conditions. We present FoMo4Wheat, one of the first crop-domain vision foundation model pretrained with self-supervision on ImAg4Wheat, the largest and most diverse wheat image dataset to date (2.5 million high-resolution images collected over a decade at 30 global sites, spanning >2,000 genotypes and >500 environmental conditions). This wheat-specific pretraining yields representations that are robust for wheat and transferable to other crops and weeds. Across ten in-field vision tasks at canopy and organ levels, FoMo4Wheat models consistently outperform state-of-the-art models pretrained on general-domain dataset. These results demonstrate the value of crop-specific foundation models for reliable in-field perception and chart a path toward a universal crop foundation model with cross-species and cross-task capabilities. FoMo4Wheat models and the ImAg4Wheat dataset are publicly available online: https://github.com/PheniX-Lab/FoMo4Wheat and https://huggingface.co/PheniX-Lab/FoMo4Wheat. The demonstration website is: https://fomo4wheat.phenix-lab.com/.