 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Dynamic GI: Random-Access Neural Compression for Temporal Lightmaps in Dynamic Lighting Environments
Apr 14, 2026High-quality global illumination (GI) in real-time rendering is commonly achieved using precomputed lighting techniques, with lightmap as the standard choice. To support GI for static objects in dynamic lighting environments, multiple lightmaps at different lighting conditions need to be precomputed, which incurs substantial storage and memory overhead. To overcome this limitation, we propose Neural Dynamic GI (NDGI), a novel compression technique specifically designed for temporal lightmap sets. Our method utilizes multi-dimensional feature maps and lightweight neural networks to integrate the temporal information instead of storing multiple sets explicitly, which significantly reduces the storage size of lightmaps. Additionally, we introduce a block compression (BC) simulation strategy during the training process, which enables BC compression on the final generated feature maps and further improves the compression ratio. To enable efficient real-time decompression, we also integrate a virtual texturing (VT) system with our neural representation. Compared with prior methods, our approach achieves high-quality dynamic GI while maintaining remarkably low storage and memory requirements, with only modest real-time decompression overhead. To facilitate further research in this direction, we will release our temporal lightmap dataset precomputed in multiple scenes featuring diverse temporal variations.
FoMo4Wheat: Toward reliable crop vision foundation models with globally curated data
Sep 08, 2025



Vision-driven field monitoring is central to digital agriculture, yet models built on general-domain pretrained backbones often fail to generalize across tasks, owing to the interaction of fine, variable canopy structures with fluctuating field conditions. We present FoMo4Wheat, one of the first crop-domain vision foundation model pretrained with self-supervision on ImAg4Wheat, the largest and most diverse wheat image dataset to date (2.5 million high-resolution images collected over a decade at 30 global sites, spanning >2,000 genotypes and >500 environmental conditions). This wheat-specific pretraining yields representations that are robust for wheat and transferable to other crops and weeds. Across ten in-field vision tasks at canopy and organ levels, FoMo4Wheat models consistently outperform state-of-the-art models pretrained on general-domain dataset. These results demonstrate the value of crop-specific foundation models for reliable in-field perception and chart a path toward a universal crop foundation model with cross-species and cross-task capabilities. FoMo4Wheat models and the ImAg4Wheat dataset are publicly available online: https://github.com/PheniX-Lab/FoMo4Wheat and https://huggingface.co/PheniX-Lab/FoMo4Wheat. The demonstration website is: https://fomo4wheat.phenix-lab.com/.
TVPR: Text-to-Video Person Retrieval and a New Benchmark
Jul 14, 2023Most existing methods for text-based person retrieval focus on text-to-image person retrieval. Nevertheless, due to the lack of dynamic information provided by isolated frames, the performance is hampered when the person is obscured in isolated frames or variable motion details are given in the textual description. In this paper, we propose a new task called Text-to-Video Person Retrieval(TVPR) which aims to effectively overcome the limitations of isolated frames. Since there is no dataset or benchmark that describes person videos with natural language, we construct a large-scale cross-modal person video dataset containing detailed natural language annotations, such as person's appearance, actions and interactions with environment, etc., termed as Text-to-Video Person Re-identification (TVPReid) dataset, which will be publicly available. To this end, a Text-to-Video Person Retrieval Network (TVPRN) is proposed. Specifically, TVPRN acquires video representations by fusing visual and motion representations of person videos, which can deal with temporal occlusion and the absence of variable motion details in isolated frames. Meanwhile, we employ the pre-trained BERT to obtain caption representations and the relationship between caption and video representations to reveal the most relevant person videos. To evaluate the effectiveness of the proposed TVPRN, extensive experiments have been conducted on TVPReid dataset. To the best of our knowledge, TVPRN is the first successful attempt to use video for text-based person retrieval task and has achieved state-of-the-art performance on TVPReid dataset. The TVPReid dataset will be publicly available to benefit future research.
Resource-Driven Mission-Phasing Techniques for Constrained Agents in Stochastic Environments
Jan 16, 2014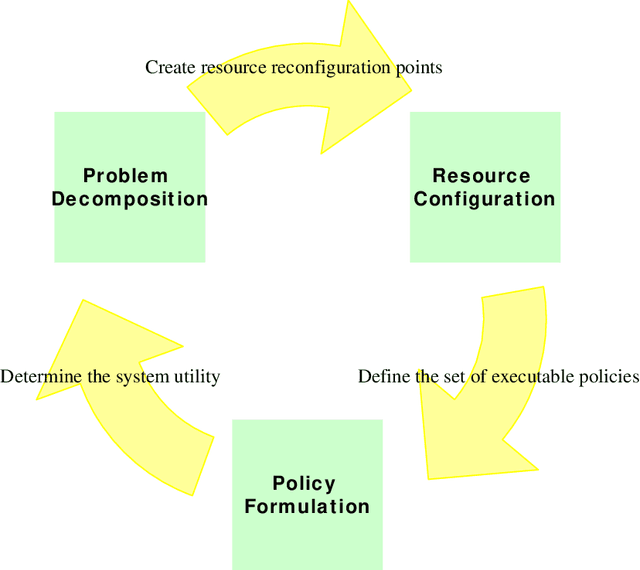
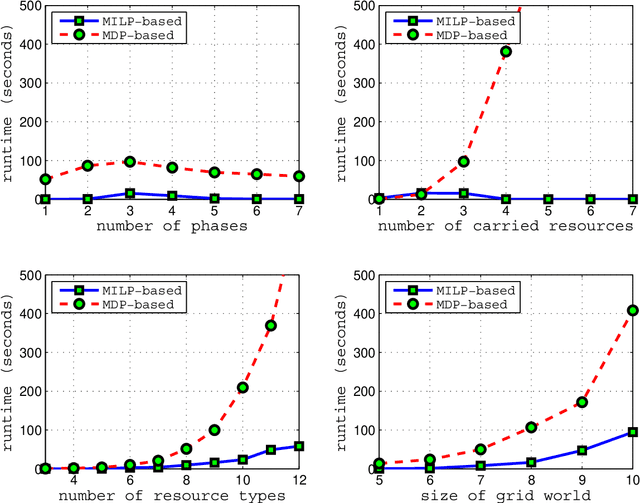

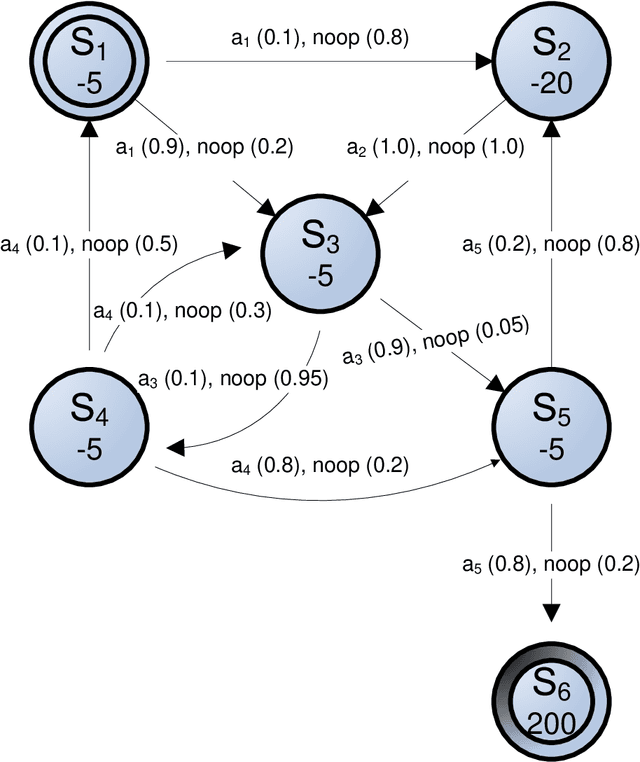
Because an agents resources dictate what actions it can possibly take, it should plan which resources it holds over time carefully, considering its inherent limitations (such as power or payload restrictions), the competing needs of other agents for the same resources, and the stochastic nature of the environment. Such agents can, in general, achieve more of their objectives if they can use --- and even create --- opportunities to change which resources they hold at various times. Driven by resource constraints, the agents could break their overall missions into an optimal series of phases, optimally reconfiguring their resources at each phase, and optimally using their assigned resources in each phase, given their knowledge of the stochastic environment. In this paper, we formally define and analyze this constrained, sequential optimization problem in both the single-agent and multi-agent contexts. We present a family of mixed integer linear programming (MILP) formulations of this problem that can optimally create phases (when phases are not predefined) accounting for costs and limitations in phase creation. Because our formulations multaneously also find the optimal allocations of resources at each phase and the optimal policies for using the allocated resources at each phase, they exploit structure across these coupled problems. This allows them to find solutions significantly faster(orders of magnitude faster in larger problems) than alternative solution techniques, as we demonstrate empirically.