 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGTPred: Benchmarking MLLMs for Interpretable Geo-localization and Time-of-capture Prediction
Jan 19, 2026Geo-localization aims to infer the geographic location where an image was captured using observable visual evidence. Traditional methods achieve impressive results through large-scale training on massive image corpora. With the emergence of multi-modal large language models (MLLMs), recent studies have explored their applications in geo-localization, benefiting from improved accuracy and interpretability. However, existing benchmarks largely ignore the temporal information inherent in images, which can further constrain the location. To bridge this gap, we introduce GTPred, a novel benchmark for geo-temporal prediction. GTPred comprises 370 globally distributed images spanning over 120 years. We evaluate MLLM predictions by jointly considering year and hierarchical location sequence matching, and further assess intermediate reasoning chains using meticulously annotated ground-truth reasoning processes. Experiments on 8 proprietary and 7 open-source MLLMs show that, despite strong visual perception, current models remain limited in world knowledge and geo-temporal reasoning. Results also demonstrate that incorporating temporal information significantly enhances location inference performance.
KidVis: Do Multimodal Large Language Models Possess the Visual Perceptual Capabilities of a 6-Year-Old?
Jan 13, 2026While Multimodal Large Language Models (MLLMs) have demonstrated impressive proficiency in high-level reasoning tasks, such as complex diagrammatic interpretation, it remains an open question whether they possess the fundamental visual primitives comparable to human intuition. To investigate this, we introduce KidVis, a novel benchmark grounded in the theory of human visual development. KidVis deconstructs visual intelligence into six atomic capabilities - Concentration, Tracking, Discrimination, Memory, Spatial, and Closure - already possessed by 6-7 year old children, comprising 10 categories of low-semantic-dependent visual tasks. Evaluating 20 state-of-the-art MLLMs against a human physiological baseline reveals a stark performance disparity. Results indicate that while human children achieve a near-perfect average score of 95.32, the state-of-the-art GPT-5 attains only 67.33. Crucially, we observe a "Scaling Law Paradox": simply increasing model parameters fails to yield linear improvements in these foundational visual capabilities. This study confirms that current MLLMs, despite their reasoning prowess, lack the essential physiological perceptual primitives required for generalized visual intelligence.
MACEval: A Multi-Agent Continual Evaluation Network for Large Models
Nov 12, 2025Hundreds of benchmarks dedicated to evaluating large models from multiple perspectives have been presented over the past few years. Albeit substantial efforts, most of them remain closed-ended and are prone to overfitting due to the potential data contamination in the ever-growing training corpus of large models, thereby undermining the credibility of the evaluation. Moreover, the increasing scale and scope of current benchmarks with transient metrics, as well as the heavily human-dependent curation procedure, pose significant challenges for timely maintenance and adaptation to gauge the advancing capabilities of large models. In this paper, we introduce MACEval, a \Multi-Agent Continual Evaluation network for dynamic evaluation of large models, and define a new set of metrics to quantify performance longitudinally and sustainably. MACEval adopts an interactive and autonomous evaluation mode that employs role assignment, in-process data generation, and evaluation routing through a cascaded agent network. Extensive experiments on 9 open-ended tasks with 23 participating large models demonstrate that MACEval is (1) human-free and automatic, mitigating laborious result processing with inter-agent judgment guided; (2) efficient and economical, reducing a considerable amount of data and overhead to obtain similar results compared to related benchmarks; and (3) flexible and scalable, migrating or integrating existing benchmarks via customized evaluation topologies. We hope that MACEval can broaden future directions of large model evaluation.
Evaluating from Benign to Dynamic Adversarial: A Squid Game for Large Language Models
Nov 12, 2025



Contemporary benchmarks are struggling to keep pace with the development of large language models (LLMs). Although they are indispensable to evaluate model performance on various tasks, it is uncertain whether the models trained on Internet data have genuinely learned how to solve problems or merely seen the questions before. This potential data contamination issue presents a fundamental challenge to establishing trustworthy evaluation frameworks. Meanwhile, existing benchmarks predominantly assume benign, resource-rich settings, leaving the behavior of LLMs under pressure unexplored. In this paper, we introduce Squid Game, a dynamic and adversarial evaluation environment with resource-constrained and asymmetric information settings elaborated to evaluate LLMs through interactive gameplay against other LLM opponents. Notably, Squid Game consists of six elimination-style levels, focusing on multi-faceted abilities, such as instruction-following, code, reasoning, planning, and safety alignment. We evaluate over 50 LLMs on Squid Game, presenting the largest behavioral evaluation study of general LLMs on dynamic adversarial scenarios. We observe a clear generational phase transition on performance in the same model lineage and find evidence that some models resort to speculative shortcuts to win the game, indicating the possibility of higher-level evaluation paradigm contamination in static benchmarks. Furthermore, we compare prominent LLM benchmarks and Squid Game with correlation analyses, highlighting that dynamic evaluation can serve as a complementary part for static evaluations. The code and data will be released in the future.
MMReID-Bench: Unleashing the Power of MLLMs for Effective and Versatile Person Re-identification
Aug 09, 2025Person re-identification (ReID) aims to retrieve the images of an interested person in the gallery images, with wide applications in medical rehabilitation, abnormal behavior detection, and public security. However, traditional person ReID models suffer from uni-modal capability, leading to poor generalization ability in multi-modal data, such as RGB, thermal, infrared, sketch images, textual descriptions, etc. Recently, the emergence of multi-modal large language models (MLLMs) shows a promising avenue for addressing this problem. Despite this potential, existing methods merely regard MLLMs as feature extractors or caption generators, which do not fully unleash their reasoning, instruction-following, and cross-modal understanding capabilities. To bridge this gap, we introduce MMReID-Bench, the first multi-task multi-modal benchmark specifically designed for person ReID. The MMReID-Bench includes 20,710 multi-modal queries and gallery images covering 10 different person ReID tasks. Comprehensive experiments demonstrate the remarkable capabilities of MLLMs in delivering effective and versatile person ReID. Nevertheless, they also have limitations in handling a few modalities, particularly thermal and infrared data. We hope MMReID-Bench can facilitate the community to develop more robust and generalizable multimodal foundation models for person ReID.
Can Large Models Fool the Eye? A New Turing Test for Biological Animation
Aug 08, 2025Evaluating the abilities of large models and manifesting their gaps are challenging. Current benchmarks adopt either ground-truth-based score-form evaluation on static datasets or indistinct textual chatbot-style human preferences collection, which may not provide users with immediate, intuitive, and perceptible feedback on performance differences. In this paper, we introduce BioMotion Arena, a novel framework for evaluating large language models (LLMs) and multimodal large language models (MLLMs) via visual animation. Our methodology draws inspiration from the inherent visual perception of motion patterns characteristic of living organisms that utilizes point-light source imaging to amplify the performance discrepancies between models. Specifically, we employ a pairwise comparison evaluation and collect more than 45k votes for 53 mainstream LLMs and MLLMs on 90 biological motion variants. Data analyses show that the crowd-sourced human votes are in good agreement with those of expert raters, demonstrating the superiority of our BioMotion Arena in offering discriminative feedback. We also find that over 90\% of evaluated models, including the cutting-edge open-source InternVL3 and proprietary Claude-4 series, fail to produce fundamental humanoid point-light groups, much less smooth and biologically plausible motions. This enables BioMotion Arena to serve as a challenging benchmark for performance visualization and a flexible evaluation framework without restrictions on ground-truth.
The Ever-Evolving Science Exam
Jul 22, 2025



As foundation models grow rapidly in capability and deployment, evaluating their scientific understanding becomes increasingly critical. Existing science benchmarks have made progress towards broad **Range**, wide **Reach**, and high **Rigor**, yet they often face two major challenges: **data leakage risks** that compromise benchmarking validity, and **evaluation inefficiency** due to large-scale testing. To address these issues, we introduce the **Ever-Evolving Science Exam (EESE)**, a dynamic benchmark designed to reliably assess scientific capabilities in foundation models. Our approach consists of two components: 1) a non-public **EESE-Pool** with over 100K expertly constructed science instances (question-answer pairs) across 5 disciplines and 500+ subfields, built through a multi-stage pipeline ensuring **Range**, **Reach**, and **Rigor**, 2) a periodically updated 500-instance subset **EESE**, sampled and validated to enable leakage-resilient, low-overhead evaluations. Experiments on 32 open- and closed-source models demonstrate that EESE effectively differentiates the strengths and weaknesses of models in scientific fields and cognitive dimensions. Overall, EESE provides a robust, scalable, and forward-compatible solution for science benchmark design, offering a realistic measure of how well foundation models handle science questions. The project page is at: https://github.com/aiben-ch/EESE.
RankLLM: A Python Package for Reranking with LLMs
May 25, 2025
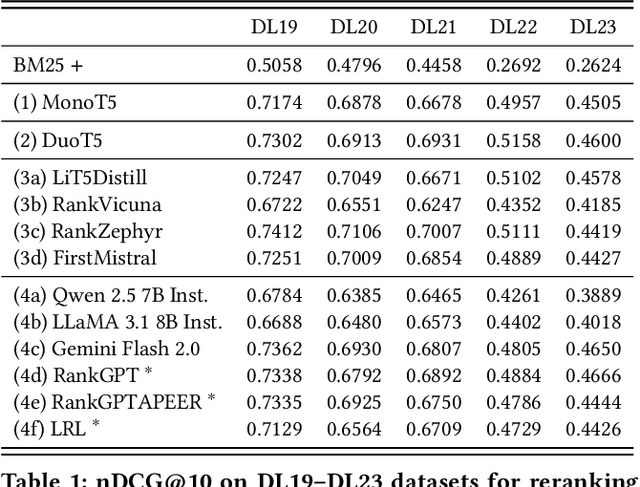


The adoption of large language models (LLMs) as rerankers in multi-stage retrieval systems has gained significant traction in academia and industry. These models refine a candidate list of retrieved documents, often through carefully designed prompts, and are typically used in applications built on retrieval-augmented generation (RAG). This paper introduces RankLLM, an open-source Python package for reranking that is modular, highly configurable, and supports both proprietary and open-source LLMs in customized reranking workflows. To improve usability, RankLLM features optional integration with Pyserini for retrieval and provides integrated evaluation for multi-stage pipelines. Additionally, RankLLM includes a module for detailed analysis of input prompts and LLM responses, addressing reliability concerns with LLM APIs and non-deterministic behavior in Mixture-of-Experts (MoE) models. This paper presents the architecture of RankLLM, along with a detailed step-by-step guide and sample code. We reproduce results from RankGPT, LRL, RankVicuna, RankZephyr, and other recent models. RankLLM integrates with common inference frameworks and a wide range of LLMs. This compatibility allows for quick reproduction of reported results, helping to speed up both research and real-world applications. The complete repository is available at rankllm.ai, and the package can be installed via PyPI.
LOVE: Benchmarking and Evaluating Text-to-Video Generation and Video-to-Text Interpretation
May 17, 2025Recent advancements in large multimodal models (LMMs) have driven substantial progress in both text-to-video (T2V) generation and video-to-text (V2T) interpretation tasks. However, current AI-generated videos (AIGVs) still exhibit limitations in terms of perceptual quality and text-video alignment. Therefore, a reliable and scalable automatic model for AIGV evaluation is desirable, which heavily relies on the scale and quality of human annotations. To this end, we present AIGVE-60K, a comprehensive dataset and benchmark for AI-Generated Video Evaluation, which features (i) comprehensive tasks, encompassing 3,050 extensive prompts across 20 fine-grained task dimensions, (ii) the largest human annotations, including 120K mean-opinion scores (MOSs) and 60K question-answering (QA) pairs annotated on 58,500 videos generated from 30 T2V models, and (iii) bidirectional benchmarking and evaluating for both T2V generation and V2T interpretation capabilities. Based on AIGVE-60K, we propose LOVE, a LMM-based metric for AIGV Evaluation from multiple dimensions including perceptual preference, text-video correspondence, and task-specific accuracy in terms of both instance level and model level. Comprehensive experiments demonstrate that LOVE not only achieves state-of-the-art performance on the AIGVE-60K dataset, but also generalizes effectively to a wide range of other AIGV evaluation benchmarks. These findings highlight the significance of the AIGVE-60K dataset. Database and codes are anonymously available at https://github.com/IntMeGroup/LOVE.
What Is Next for LLMs? Next-Generation AI Computing Hardware Using Photonic Chips
May 09, 2025



Large language models (LLMs) are rapidly pushing the limits of contemporary computing hardware. For example, training GPT-3 has been estimated to consume around 1300 MWh of electricity, and projections suggest future models may require city-scale (gigawatt) power budgets. These demands motivate exploration of computing paradigms beyond conventional von Neumann architectures. This review surveys emerging photonic hardware optimized for next-generation generative AI computing. We discuss integrated photonic neural network architectures (e.g., Mach-Zehnder interferometer meshes, lasers, wavelength-multiplexed microring resonators) that perform ultrafast matrix operations. We also examine promising alternative neuromorphic devices, including spiking neural network circuits and hybrid spintronic-photonic synapses, which combine memory and processing. The integration of two-dimensional materials (graphene, TMDCs) into silicon photonic platforms is reviewed for tunable modulators and on-chip synaptic elements. Transformer-based LLM architectures (self-attention and feed-forward layers) are analyzed in this context, identifying strategies and challenges for mapping dynamic matrix multiplications onto these novel hardware substrates. We then dissect the mechanisms of mainstream LLMs, such as ChatGPT, DeepSeek, and LLaMA, highlighting their architectural similarities and differences. We synthesize state-of-the-art components, algorithms, and integration methods, highlighting key advances and open issues in scaling such systems to mega-sized LLM models. We find that photonic computing systems could potentially surpass electronic processors by orders of magnitude in throughput and energy efficiency, but require breakthroughs in memory, especially for long-context windows and long token sequences, and in storage of ultra-large datasets.