 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLightGen: Efficient Image Generation through Knowledge Distillation and Direct Preference Optimization
Mar 11, 2025



Recent advances in text-to-image generation have primarily relied on extensive datasets and parameter-heavy architectures. These requirements severely limit accessibility for researchers and practitioners who lack substantial computational resources. In this paper, we introduce \model, an efficient training paradigm for image generation models that uses knowledge distillation (KD) and Direct Preference Optimization (DPO). Drawing inspiration from the success of data KD techniques widely adopted in Multi-Modal Large Language Models (MLLMs), LightGen distills knowledge from state-of-the-art (SOTA) text-to-image models into a compact Masked Autoregressive (MAR) architecture with only $0.7B$ parameters. Using a compact synthetic dataset of just $2M$ high-quality images generated from varied captions, we demonstrate that data diversity significantly outweighs data volume in determining model performance. This strategy dramatically reduces computational demands and reduces pre-training time from potentially thousands of GPU-days to merely 88 GPU-days. Furthermore, to address the inherent shortcomings of synthetic data, particularly poor high-frequency details and spatial inaccuracies, we integrate the DPO technique that refines image fidelity and positional accuracy. Comprehensive experiments confirm that LightGen achieves image generation quality comparable to SOTA models while significantly reducing computational resources and expanding accessibility for resource-constrained environments. Code is available at https://github.com/XianfengWu01/LightGen
UQABench: Evaluating User Embedding for Prompting LLMs in Personalized Question Answering
Feb 26, 2025Large language models (LLMs) achieve remarkable success in natural language processing (NLP). In practical scenarios like recommendations, as users increasingly seek personalized experiences, it becomes crucial to incorporate user interaction history into the context of LLMs to enhance personalization. However, from a practical utility perspective, user interactions' extensive length and noise present challenges when used directly as text prompts. A promising solution is to compress and distill interactions into compact embeddings, serving as soft prompts to assist LLMs in generating personalized responses. Although this approach brings efficiency, a critical concern emerges: Can user embeddings adequately capture valuable information and prompt LLMs? To address this concern, we propose \name, a benchmark designed to evaluate the effectiveness of user embeddings in prompting LLMs for personalization. We establish a fair and standardized evaluation process, encompassing pre-training, fine-tuning, and evaluation stages. To thoroughly evaluate user embeddings, we design three dimensions of tasks: sequence understanding, action prediction, and interest perception. These evaluation tasks cover the industry's demands in traditional recommendation tasks, such as improving prediction accuracy, and its aspirations for LLM-based methods, such as accurately understanding user interests and enhancing the user experience. We conduct extensive experiments on various state-of-the-art methods for modeling user embeddings. Additionally, we reveal the scaling laws of leveraging user embeddings to prompt LLMs. The benchmark is available online.
Does Editing Provide Evidence for Localization?
Feb 19, 2025



A basic aspiration for interpretability research in large language models is to "localize" semantically meaningful behaviors to particular components within the LLM. There are various heuristics for finding candidate locations within the LLM. Once a candidate localization is found, it can be assessed by editing the internal representations at the corresponding localization and checking whether this induces model behavior that is consistent with the semantic interpretation of the localization. The question we address here is: how strong is the evidence provided by such edits? To evaluate the localization claim, we want to assess the effect of the optimal intervention at a particular location. The key new technical tool is a way of adapting LLM alignment techniques to find such optimal localized edits. With this tool in hand, we give an example where the edit-based evidence for localization appears strong, but where localization clearly fails. Indeed, we find that optimal edits at random localizations can be as effective as aligning the full model. In aggregate, our results suggest that merely observing that localized edits induce targeted changes in behavior provides little to no evidence that these locations actually encode the target behavior.
A Comprehensive Survey on Generative AI for Video-to-Music Generation
Feb 18, 2025The burgeoning growth of video-to-music generation can be attributed to the ascendancy of multimodal generative models. However, there is a lack of literature that comprehensively combs through the work in this field. To fill this gap, this paper presents a comprehensive review of video-to-music generation using deep generative AI techniques, focusing on three key components: visual feature extraction, music generation frameworks, and conditioning mechanisms. We categorize existing approaches based on their designs for each component, clarifying the roles of different strategies. Preceding this, we provide a fine-grained classification of video and music modalities, illustrating how different categories influence the design of components within the generation pipelines. Furthermore, we summarize available multimodal datasets and evaluation metrics while highlighting ongoing challenges in the field.
LIR-LIVO: A Lightweight,Robust LiDAR/Vision/Inertial Odometry with Illumination-Resilient Deep Features
Feb 12, 2025In this paper, we propose LIR-LIVO, a lightweight and robust LiDAR-inertial-visual odometry system designed for challenging illumination and degraded environments. The proposed method leverages deep learning-based illumination-resilient features and LiDAR-Inertial-Visual Odometry (LIVO). By incorporating advanced techniques such as uniform depth distribution of features enabled by depth association with LiDAR point clouds and adaptive feature matching utilizing Superpoint and LightGlue, LIR-LIVO achieves state-of-the-art (SOTA) accuracy and robustness with low computational cost. Experiments are conducted on benchmark datasets, including NTU-VIRAL, Hilti'22, and R3LIVE-Dataset. The corresponding results demonstrate that our proposed method outperforms other SOTA methods on both standard and challenging datasets. Particularly, the proposed method demonstrates robust pose estimation under poor ambient lighting conditions in the Hilti'22 dataset. The code of this work is publicly accessible on GitHub to facilitate advancements in the robotics community.
Unlocking Scaling Law in Industrial Recommendation Systems with a Three-step Paradigm based Large User Model
Feb 12, 2025Recent advancements in autoregressive Large Language Models (LLMs) have achieved significant milestones, largely attributed to their scalability, often referred to as the "scaling law". Inspired by these achievements, there has been a growing interest in adapting LLMs for Recommendation Systems (RecSys) by reformulating RecSys tasks into generative problems. However, these End-to-End Generative Recommendation (E2E-GR) methods tend to prioritize idealized goals, often at the expense of the practical advantages offered by traditional Deep Learning based Recommendation Models (DLRMs) in terms of in features, architecture, and practices. This disparity between idealized goals and practical needs introduces several challenges and limitations, locking the scaling law in industrial RecSys. In this paper, we introduce a large user model (LUM) that addresses these limitations through a three-step paradigm, designed to meet the stringent requirements of industrial settings while unlocking the potential for scalable recommendations. Our extensive experimental evaluations demonstrate that LUM outperforms both state-of-the-art DLRMs and E2E-GR approaches. Notably, LUM exhibits excellent scalability, with performance improvements observed as the model scales up to 7 billion parameters. Additionally, we have successfully deployed LUM in an industrial application, where it achieved significant gains in an A/B test, further validating its effectiveness and practicality.
Encrypted Large Model Inference: The Equivariant Encryption Paradigm
Feb 03, 2025



Large scale deep learning model, such as modern language models and diffusion architectures, have revolutionized applications ranging from natural language processing to computer vision. However, their deployment in distributed or decentralized environments raises significant privacy concerns, as sensitive data may be exposed during inference. Traditional techniques like secure multi-party computation, homomorphic encryption, and differential privacy offer partial remedies but often incur substantial computational overhead, latency penalties, or limited compatibility with non-linear network operations. In this work, we introduce Equivariant Encryption (EE), a novel paradigm designed to enable secure, "blind" inference on encrypted data with near zero performance overhead. Unlike fully homomorphic approaches that encrypt the entire computational graph, EE selectively obfuscates critical internal representations within neural network layers while preserving the exact functionality of both linear and a prescribed set of non-linear operations. This targeted encryption ensures that raw inputs, intermediate activations, and outputs remain confidential, even when processed on untrusted infrastructure. We detail the theoretical foundations of EE, compare its performance and integration complexity against conventional privacy preserving techniques, and demonstrate its applicability across a range of architectures, from convolutional networks to large language models. Furthermore, our work provides a comprehensive threat analysis, outlining potential attack vectors and baseline strategies, and benchmarks EE against standard inference pipelines in decentralized settings. The results confirm that EE maintains high fidelity and throughput, effectively bridging the gap between robust data confidentiality and the stringent efficiency requirements of modern, large scale model inference.
Top Ten Challenges Towards Agentic Neural Graph Databases
Jan 24, 2025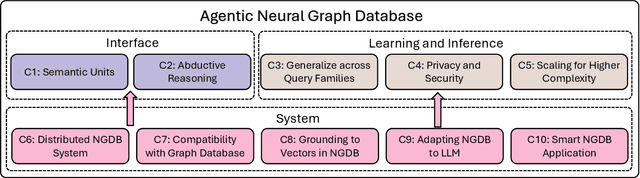
Graph databases (GDBs) like Neo4j and TigerGraph excel at handling interconnected data but lack advanced inference capabilities. Neural Graph Databases (NGDBs) address this by integrating Graph Neural Networks (GNNs) for predictive analysis and reasoning over incomplete or noisy data. However, NGDBs rely on predefined queries and lack autonomy and adaptability. This paper introduces Agentic Neural Graph Databases (Agentic NGDBs), which extend NGDBs with three core functionalities: autonomous query construction, neural query execution, and continuous learning. We identify ten key challenges in realizing Agentic NGDBs: semantic unit representation, abductive reasoning, scalable query execution, and integration with foundation models like large language models (LLMs). By addressing these challenges, Agentic NGDBs can enable intelligent, self-improving systems for modern data-driven applications, paving the way for adaptable and autonomous data management solutions.
Humanity's Last Exam
Jan 24, 2025Benchmarks are important tools for tracking the rapid advancements in large language model (LLM) capabilities. However, benchmarks are not keeping pace in difficulty: LLMs now achieve over 90\% accuracy on popular benchmarks like MMLU, limiting informed measurement of state-of-the-art LLM capabilities. In response, we introduce Humanity's Last Exam (HLE), a multi-modal benchmark at the frontier of human knowledge, designed to be the final closed-ended academic benchmark of its kind with broad subject coverage. HLE consists of 3,000 questions across dozens of subjects, including mathematics, humanities, and the natural sciences. HLE is developed globally by subject-matter experts and consists of multiple-choice and short-answer questions suitable for automated grading. Each question has a known solution that is unambiguous and easily verifiable, but cannot be quickly answered via internet retrieval. State-of-the-art LLMs demonstrate low accuracy and calibration on HLE, highlighting a significant gap between current LLM capabilities and the expert human frontier on closed-ended academic questions. To inform research and policymaking upon a clear understanding of model capabilities, we publicly release HLE at https://lastexam.ai.
Enhancing Patient-Centric Communication: Leveraging LLMs to Simulate Patient Perspectives
Jan 12, 2025



Large Language Models (LLMs) have demonstrated impressive capabilities in role-playing scenarios, particularly in simulating domain-specific experts using tailored prompts. This ability enables LLMs to adopt the persona of individuals with specific backgrounds, offering a cost-effective and efficient alternative to traditional, resource-intensive user studies. By mimicking human behavior, LLMs can anticipate responses based on concrete demographic or professional profiles. In this paper, we evaluate the effectiveness of LLMs in simulating individuals with diverse backgrounds and analyze the consistency of these simulated behaviors compared to real-world outcomes. In particular, we explore the potential of LLMs to interpret and respond to discharge summaries provided to patients leaving the Intensive Care Unit (ICU). We evaluate and compare with human responses the comprehensibility of discharge summaries among individuals with varying educational backgrounds, using this analysis to assess the strengths and limitations of LLM-driven simulations. Notably, when LLMs are primed with educational background information, they deliver accurate and actionable medical guidance 88% of the time. However, when other information is provided, performance significantly drops, falling below random chance levels. This preliminary study shows the potential benefits and pitfalls of automatically generating patient-specific health information from diverse populations. While LLMs show promise in simulating health personas, our results highlight critical gaps that must be addressed before they can be reliably used in clinical settings. Our findings suggest that a straightforward query-response model could outperform a more tailored approach in delivering health information. This is a crucial first step in understanding how LLMs can be optimized for personalized health communication while maintaining accuracy.