 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeel the Bite: Robot-Assisted Inside-Mouth Bite Transfer using Robust Mouth Perception and Physical Interaction-Aware Control
Mar 06, 2024Robot-assisted feeding can greatly enhance the lives of those with mobility limitations. Modern feeding systems can pick up and position food in front of a care recipient's mouth for a bite. However, many with severe mobility constraints cannot lean forward and need direct inside-mouth food placement. This demands precision, especially for those with restricted mouth openings, and appropriately reacting to various physical interactions - incidental contacts as the utensil moves inside, impulsive contacts due to sudden muscle spasms, deliberate tongue maneuvers by the person being fed to guide the utensil, and intentional bites. In this paper, we propose an inside-mouth bite transfer system that addresses these challenges with two key components: a multi-view mouth perception pipeline robust to tool occlusion, and a control mechanism that employs multimodal time-series classification to discern and react to different physical interactions. We demonstrate the efficacy of these individual components through two ablation studies. In a full system evaluation, our system successfully fed 13 care recipients with diverse mobility challenges. Participants consistently emphasized the comfort and safety of our inside-mouth bite transfer system, and gave it high technology acceptance ratings - underscoring its transformative potential in real-world scenarios. Supplementary materials and videos can be found at http://emprise.cs.cornell.edu/bitetransfer/ .
Max-Min Fair Energy-Efficient Beam Design for Quantized ISAC LEO Satellite Systems: A Rate-Splitting Approach
Feb 14, 2024



Low earth orbit (LEO) satellite systems with sensing functionality is envisioned to facilitate global-coverage service and emerging applications in 6G. Currently, two fundamental challenges, namely, inter-beam interference among users and power limitation at the LEO satellites, limit the full potential of the joint design of sensing and communication. To effectively control the interference, rate-splitting multiple access (RSMA) scheme is employed as the interference management strategy in the system design. On the other hand, to address the limited power supply at the LEO satellites, we consider low-resolution quantization digital-to-analog converters (DACs) at the transmitter to reduce power consumption, which grows exponentially with the number of quantization bits. Additionally, optimizing the total energy efficiency (EE) of the system is a common practice to save the power. However, this metric lacks fairness among users. To ensure this fairness and further enhance EE, we investigate the max-min fairness EE of the RSMA-assisted integrated sensing and communications (ISAC)-LEO satellite system. In this system, the satellite transmits a quantized dual-functional signal serving downlink users while detecting a target. Specifically, we optimize the precoders for maximizing the minimal EE among all users, considering the power consumption of each radio frequency (RF) chain under communication and sensing constraints. To tackle this optimization problem, we proposed an iterative algorithm based on successive convex approximation (SCA) and Dinkelbach's method. Numerical results illustrate that the proposed design outperforms the strategies that aim to maximize the total EE of the system and conventional space-division multiple access (SDMA) in terms of max-min fairness EE and the communication-sensing trade-off.
Model-Based Control with Sparse Neural Dynamics
Dec 20, 2023



Learning predictive models from observations using deep neural networks (DNNs) is a promising new approach to many real-world planning and control problems. However, common DNNs are too unstructured for effective planning, and current control methods typically rely on extensive sampling or local gradient descent. In this paper, we propose a new framework for integrated model learning and predictive control that is amenable to efficient optimization algorithms. Specifically, we start with a ReLU neural model of the system dynamics and, with minimal losses in prediction accuracy, we gradually sparsify it by removing redundant neurons. This discrete sparsification process is approximated as a continuous problem, enabling an end-to-end optimization of both the model architecture and the weight parameters. The sparsified model is subsequently used by a mixed-integer predictive controller, which represents the neuron activations as binary variables and employs efficient branch-and-bound algorithms. Our framework is applicable to a wide variety of DNNs, from simple multilayer perceptrons to complex graph neural dynamics. It can efficiently handle tasks involving complicated contact dynamics, such as object pushing, compositional object sorting, and manipulation of deformable objects. Numerical and hardware experiments show that, despite the aggressive sparsification, our framework can deliver better closed-loop performance than existing state-of-the-art methods.
Learning to Design and Use Tools for Robotic Manipulation
Nov 01, 2023



When limited by their own morphologies, humans and some species of animals have the remarkable ability to use objects from the environment toward accomplishing otherwise impossible tasks. Robots might similarly unlock a range of additional capabilities through tool use. Recent techniques for jointly optimizing morphology and control via deep learning are effective at designing locomotion agents. But while outputting a single morphology makes sense for locomotion, manipulation involves a variety of strategies depending on the task goals at hand. A manipulation agent must be capable of rapidly prototyping specialized tools for different goals. Therefore, we propose learning a designer policy, rather than a single design. A designer policy is conditioned on task information and outputs a tool design that helps solve the task. A design-conditioned controller policy can then perform manipulation using these tools. In this work, we take a step towards this goal by introducing a reinforcement learning framework for jointly learning these policies. Through simulated manipulation tasks, we show that this framework is more sample efficient than prior methods in multi-goal or multi-variant settings, can perform zero-shot interpolation or fine-tuning to tackle previously unseen goals, and allows tradeoffs between the complexity of design and control policies under practical constraints. Finally, we deploy our learned policies onto a real robot. Please see our supplementary video and website at https://robotic-tool-design.github.io/ for visualizations.
Generalizable Metric Network for Cross-domain Person Re-identification
Jun 21, 2023Person Re-identification (Re-ID) is a crucial technique for public security and has made significant progress in supervised settings. However, the cross-domain (i.e., domain generalization) scene presents a challenge in Re-ID tasks due to unseen test domains and domain-shift between the training and test sets. To tackle this challenge, most existing methods aim to learn domain-invariant or robust features for all domains. In this paper, we observe that the data-distribution gap between the training and test sets is smaller in the sample-pair space than in the sample-instance space. Based on this observation, we propose a Generalizable Metric Network (GMN) to further explore sample similarity in the sample-pair space. Specifically, we add a Metric Network (M-Net) after the main network and train it on positive and negative sample-pair features, which is then employed during the test stage. Additionally, we introduce the Dropout-based Perturbation (DP) module to enhance the generalization capability of the metric network by enriching the sample-pair diversity. Moreover, we develop a Pair-Identity Center (PIC) loss to enhance the model's discrimination by ensuring that sample-pair features with the same pair-identity are consistent. We validate the effectiveness of our proposed method through a lot of experiments on multiple benchmark datasets and confirm the value of each module in our GMN.
Diffusion Co-Policy for Synergistic Human-Robot Collaborative Tasks
May 20, 2023



Modeling multimodal human behavior accurately has been a key barrier to increasing the level of interaction between human and robot, particularly for collaborative tasks. Our key insight is that the predictive accuracy of human behaviors on physical tasks is bottlenecked by the model for methods involving human behavior prediction. We present a method for training denoising diffusion probabilistic models on a dataset of collaborative human-human demonstrations and conditioning on past human partner actions to plan sequences of robot actions that synergize well with humans during test time. We demonstrate the method outperforms other state-of-art learning methods on human-robot table-carrying, a continuous state-action task, in both simulation and real settings with a human in the loop. Moreover, we qualitatively highlight compelling robot behaviors that arise during evaluations that demonstrate evidence of true human-robot collaboration, including mutual adaptation, shared task understanding, leadership switching, learned partner behaviors, and low levels of wasteful interaction forces arising from dissent. Project page coming soon.
Integrated Sensing and Communications Enabled Low Earth Orbit Satellite Systems
Apr 03, 2023Extreme crowding of electromagnetic spectrum in recent years has led to the emergence of complex challenges in designing sensing and communications systems. Both systems need wide bandwidth to provide a designated quality-of-service thus resulting in competing interests in exploiting the spectrum. Efficient spectrum utilization has led to the emergence of Integrated Sensing and Communications (ISAC) systems, an approach listed for beyond 5G networks. Several seminal works focusing on the physical and medium-access layer as well as system aspects of ISAC have appeared in the literature already. These works largely focus on terrestrial communications and the use of near-earth objects like Unmanned Aerial Vehicles (UAV)s. The focus of this work is to explore the ISAC in the emerging massive Low Earth Orbit (LEO) satellite systems, leveraging on their low latency, density, ubiquitous coverage and ease of integration. In particular, two aspects of the ISAC: opportunistic and optimized will be highlighted in this work through the use of LEO satellites for positioning as well as the use of Rate-Splitting Multiple Access (RSMA) technique optimized to address sensing and communication requirements.
Robot Navigation with Reinforcement Learned Path Generation and Fine-Tuned Motion Control
Oct 19, 2022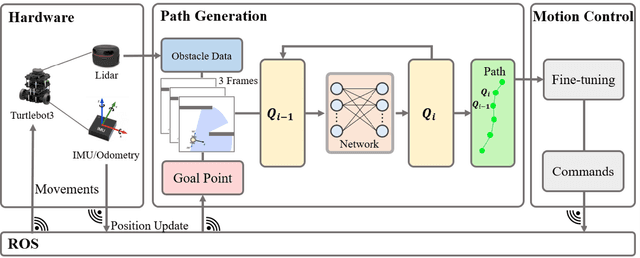
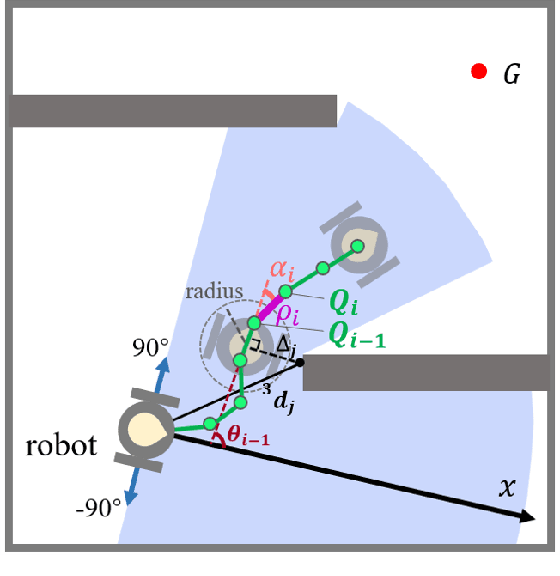
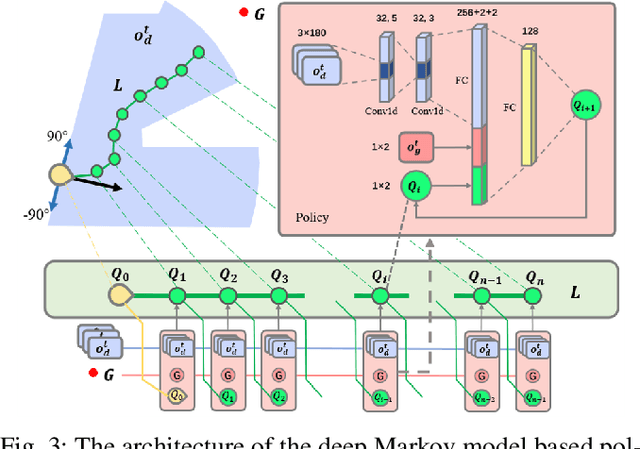

In this paper, we propose a novel reinforcement learning (RL) based path generation (RL-PG) approach for mobile robot navigation without a prior exploration of an unknown environment. Multiple predictive path points are dynamically generated by a deep Markov model optimized using RL approach for robot to track. To ensure the safety when tracking the predictive points, the robot's motion is fine-tuned by a motion fine-tuning module. Such an approach, using the deep Markov model with RL algorithm for planning, focuses on the relationship between adjacent path points. We analyze the benefits that our proposed approach are more effective and are with higher success rate than RL-Based approach DWA-RL and a traditional navigation approach APF. We deploy our model on both simulation and physical platforms and demonstrate our model performs robot navigation effectively and safely.
$λ$-MIMO: Massive MIMO via Modulo Sampling
Oct 18, 2022



Massive multiple-input multiple-output (M-MIMO) architecture is the workhorse of modern communication systems. Currently, two fundamental bottlenecks, namely, power consumption and receiver saturation, limit the full potential achievement of this technology. These bottlenecks are intricately linked with the analog-to-digital converter (ADC) used in each radio frequency (RF) chain. The power consumption in MIMO systems grows exponentially with the ADC's bit budget while ADC saturation causes permanent loss of information. This motivates the need for a solution that can simultaneously tackle the above-mentioned bottlenecks while offering advantages over existing alternatives such as low-resolution ADCs. Taking a radically different approach to this problem, we propose $\lambda$-MIMO architecture which uses modulo ADCs ($M_\lambda$-ADC) instead of a conventional ADC. Our work is inspired by the Unlimited Sampling Framework. $M_\lambda$-ADC in the RF chain folds high dynamic range signals into low dynamic range modulo samples, thus alleviating the ADC saturation problem. At the same time, digitization of modulo signal results in high resolution quantization. In the novel $\lambda$-MIMO context, we discuss baseband signal reconstruction, detection and uplink achievable sum-rate performance. The key takeaways of our work include, (a) leveraging higher signal-to-quantization noise ratio (SQNR), (b) detection and average uplink sum-rate performances comparable to a conventional, infinite-resolution ADC when using a $1$-$2$ bit $M_\lambda$-ADC. This enables higher order modulation schemes e.g. $1024$ QAM that seemed previously impossible, (c) superior trade-off between energy efficiency and bit budget, thus resulting in higher power efficiency. Numerical simulations and modulo ADC based hardware experiments corroborate our theory and reinforce the clear benefits of $\lambda$-MIMO approach.
It Takes Two: Learning to Plan for Human-Robot Cooperative Carrying
Sep 26, 2022
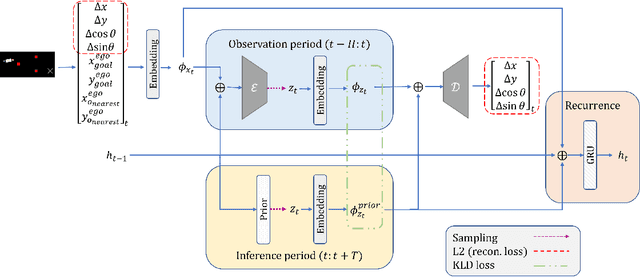
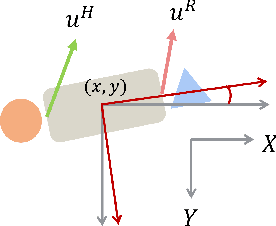
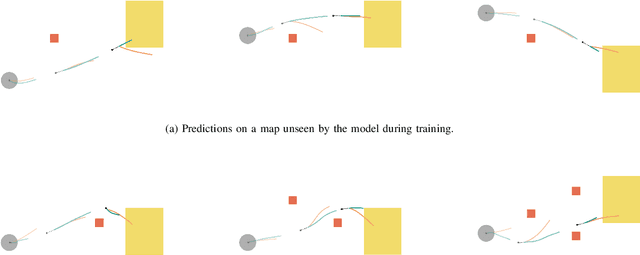
Collaborative table-carrying is a complex task due to the continuous nature of the action and state-spaces, multimodality of strategies, existence of obstacles in the environment, and the need for instantaneous adaptation to other agents. In this work, we present a method for predicting realistic motion plans for cooperative human-robot teams on a table-carrying task. Using a Variational Recurrent Neural Network, VRNN, to model the variation in the trajectory of a human-robot team over time, we are able to capture the distribution over the team's future states while leveraging information from interaction history. The key to our approach is in our model's ability to leverage human demonstration data and generate trajectories that synergize well with humans during test time. We show that the model generates more human-like motion compared to a baseline, centralized sampling-based planner, Rapidly-exploring Random Trees (RRT). Furthermore, we evaluate the VRNN planner with a human partner and show its ability to both generate more human-like paths and achieve higher task success rate than RRT can while planning with a human. Finally, we demonstrate that a LoCoBot using the VRNN planner can complete the task successfully with a human controlling another LoCoBot.